程序员编程艺术第二十六章:基于给定的文档生成倒排索引(含源码下载)
第二十六章:基于给定的文档生成倒排索引的编码与实践
作者:July、yansha。
出处:结构之法算法之道
引言
本周实现倒排索引。实现过程中,寻找资料,结果发现找份资料诸多不易:1、网上搜倒排索引实现,结果千篇一律,例子都是那几个同样的单词;2、到谷歌学术上想找点稍微有价值水平的资料,结果下篇论文还收费或者要求注册之类;3、大部分技术书籍只有理论,没有实践。于是,朋友戏言:网上一般有价值的东西不多。希望,本blog的出现能稍稍改变此现状。
在第二十四章、倒排索引关键词不重复Hash编码中,我们针对一个给定的倒排索引文件,提取出其中的关键词,然后针对这些关键词进行Hash不重复编码。本章,咱们再倒退一步,即给定一个正排文档(暂略过文本解析,分词等步骤,日后会慢慢考虑这些且一并予以实现),要求生成对应的倒排索引文件。同时,本章还是基于Hash索引之上(运用暴雪的Hash函数可以比较完美的解决大数据量下的冲突问题),日后自会实现B+树索引。
与此同时,本编程艺术系列逐步从为面试服务而转到实战性的编程当中了,教初学者如何编程,如何运用高效的算法解决实际应用中的编程问题,将逐步成为本编程艺术系列的主旨之一。
OK,接下来,咱们针对给定的正排文档一步一步来生成倒排索引文件,有任何问题,欢迎随时不吝赐教或批评指正。谢谢。
第一节、索引的构建方法
根据信息检索导论(Christtopher D.Manning等著,王斌译)一书给的提示,我们可以选择两种构建索引的算法:BSBI算法,与SPIMI算法。
BSBI算法,基于磁盘的外部排序算法,此算法首先将词项映射成其ID的数据结构,如Hash映射。而后将文档解析成词项ID-文档ID对,并在内存中一直处理,直到累积至放满一个固定大小的块空间为止,我们选择合适的块大小,使之能方便加载到内存中并允许在内存中快速排序,快速排序后的块转换成倒排索引格式后写入磁盘。
建立倒排索引的步骤如下:
- 将文档分割成几个大小相等的部分;
- 对词项ID-文档ID进行排序;
- 将具有同一词项ID的所有文档ID放到倒排记录表中,其中每条倒排记录仅仅是一个文档ID;
- 将基于块的倒排索引写到磁盘上。
(基于块的排序索引算法,该算法将每个块的倒排索引文件存入文件f1,...,fn中,最后合并成fmerged
如果该算法应用最后一步产生了10个块,那么接下来便会将10个块索引同时合并成一个索引文件。)
合并时,同时打开所有块对应的文件,内存中维护了为10个块准备的读缓冲区和一个为最终合并索引准备的写缓冲区。每次迭代中,利用优先级队列(如堆结构或类似的数据结构)选择最小的未处理的词项ID进行处理。如下图所示(图片引自深入搜索引擎--海里信息的压缩、索引和查询,梁斌译),分块索引,分块排序,最终全部合并(说实话,跟MapReduce还是有些类似的):
读入该词项的倒排记录表并合并,合并结果写回磁盘中。需要时,再次从文件中读入数据到每个读缓冲区(基于磁盘的外部排序算法的更多可以参考:程序员编程艺术 第十章、如何给10^7个数据量的磁盘文件排序)。
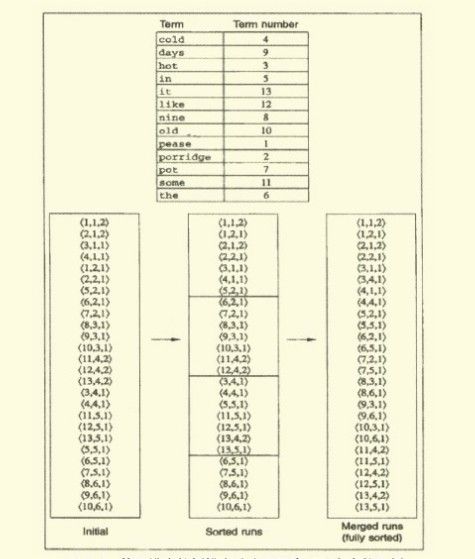
BSBI算法主要的时间消耗在排序上,选择什么排序方法呢,简单的快速排序足矣,其时间复杂度为O(N*logN),其中N是所需要排序的项(词项ID-文档ID对)的数目的上界。
SPIMI算法,内存式单遍扫描索引算法与上述BSBI算法不同的是:SPIMI使用词项而不是其ID,它将每个块的词典写入磁盘,对于写一块则重新采用新的词典,只要硬盘空间足够大,它能索引任何大小的文档集。
倒排索引 = 词典(关键词或词项+词项频率)+倒排记录表。建倒排索引的步骤如下:
- 从头开始扫描每一个词项-文档ID(信息)对,遇一词,构建索引;
- 继续扫描,若遇一新词,则再建一新索引块(加入词典,通过Hash表实现,同时,建一新的倒排记录表);若遇一旧词,则找到其倒排记录表的位置,添加其后
- 在内存内基于分块完成排序,后合并分块;
- 写入磁盘。
SPIMI与BSBI的主要区别:
SPIMI当发现关键词是第一次出现时,会直接在倒排记录表中增加一项(与BSBI算法不同)。同时,与BSBI算法一开始就整理出所有的词项ID-文档ID,并对它们进行排序的做法不同(而这恰恰是BSBI的做法),这里的每个倒排记录表都是动态增长的(也就是说,倒排记录表的大小会不断调整),同时,扫描一遍就可以实现全体倒排记录表的收集。
SPIMI这样做有两点好处:
- 由于不需要排序操作,因此处理的速度更快,
- 由于保留了倒排记录表对词项的归属关系,因此能节省内存,词项的ID也不需要保存。这样,每次单独的SPIMI-Invert调用能够处理的块大小可以非常大,整个倒排索引的构建过程也可以非常高效。
与此同时,自然而然便会浪费一部分空间(当然,此前因为不保存词项ID,倒也省下一点空间,总体而言,算作是抵销了)。
不过,至少SPIMI所用的空间会比BSBI所用空间少。当内存耗尽后,包括词典和倒排记录表的块索引将被写到磁盘上,但在此之前,为使倒排记录表按照词典顺序来加快最后的合并操作,所以要对词项进行排序操作。
小数据量与大数据量的区别
在小数据量时,有足够的内存保证该创建过程可以一次完成;
数据规模增大后,可以采用分组索引,然后再归并索 引的策略。该策略是,
- 建立索引的模块根据当时运行系统所在的计算机的内存大小,将索引分为 k 组,使得每组运算所需内存都小于系统能够提供的最大使用内存的大小。
- 按照倒排索引的生成算法,生成 k 组倒排索引。
- 然后将这 k 组索引归并,即将相同索引词对应的数据合并到一起,就得到了以索引词为主键的最终的倒排文件索引,即反向索引。
第二节、Hash表的构建与实现
如下,给定如下图所示的正排文档,每一行的信息分别为(中间用##########隔开):文档ID、订阅源(子频道)、 频道分类、 网站类ID(大频道)、时间、 md5、文档权值、关键词、作者等等。
要求基于给定的上述正排文档。生成如第二十四章所示的倒排索引文件(注,关键词所在的文章如果是同一个日期的话,是挨在同一行的,用“#”符号隔开):

正如上图粗略所示,我们知道倒排索引创建的过程如下:
- 写爬虫抓取相关的网页,而后提取相关网页或文章中所有的关键词;
- 分词,找出所有单词;
- 过滤不相干的信息(如广告等信息);
- 构建倒排索引,关键词=>(文章ID 出现次数 出现的位置)
- 生成词典文件 频率文件 位置文件
- 压缩。
OK,闲不多说,咱们来一步一步实现吧。
建相关的数据结构
根据给定的正排文档,我们可以建立如下的两个结构体表示这些信息:文档ID、订阅源(子频道)、 频道分类、 网站类ID(大频道)、时间、 md5、文档权值、关键词、作者等等。如下所示:
我们知道,通过第二十四章的暴雪的Hash表算法,可以比较好的避免相关冲突的问题。下面,我们再次引用其代码:基于暴雪的Hash之上的改造算法
有了这个Hash表,接下来,我们就可以把词插入Hash表进行存储了。
第三节、倒排索引文件的生成与实现
Hash表实现了(存于HashSearch.h中),还得编写一系列的函数,如下所示(所有代码还只是初步实现了功能,稍后在第四部分中将予以改进与优化):
最后,主函数编写如下:
程序编译运行后,生成的倒排索引文件为index.txt,其与原来给定的正排文档对照如下: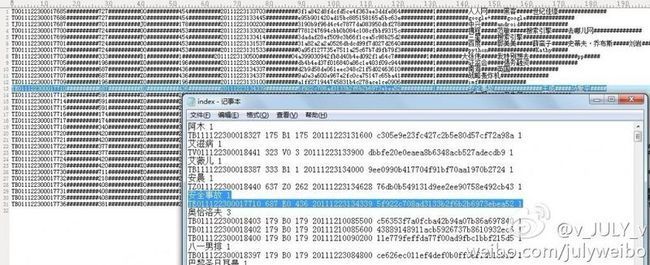
有没有发现关键词奥恰洛夫出现在的三篇文章是同一个日期1210的,貌似与本文开头指定的倒排索引格式要求不符?因为第二部分开头中,已明确说明:“注,关键词所在的文章如果是同一个日期的话,是挨在同一行的,用“#”符号隔开”。OK,有疑问是好事,代表你思考了,请直接转至下文第4部分。
第四节、程序需求功能的改进
4.1、对相同日期与不同日期的处理
细心的读者可能还是会注意到:在第二部分开头中,要求基于给定的上述正排文档。生成如第二十四章所示的倒排索引文件是下面这样子的,即是:
也就是说,上面建索引的过程本该是如下的:

与第一部分所述的SMIPI算法有什么区别?对的,就在于对在同一个日期的出现的关键词的处理。如果是遇一旧词,则找到其倒排记录表的位置:相同日期,添加到之前同一日期的记录之后(第一个记录的后面记下同一日期的记录数目);不同日期,另起一行新增记录。
相同(单个)日期,根据文档权值排序
不同日期,根据时间排序
代码主要修改如下:
修改后编译运行,生成的index.txt文件如下:
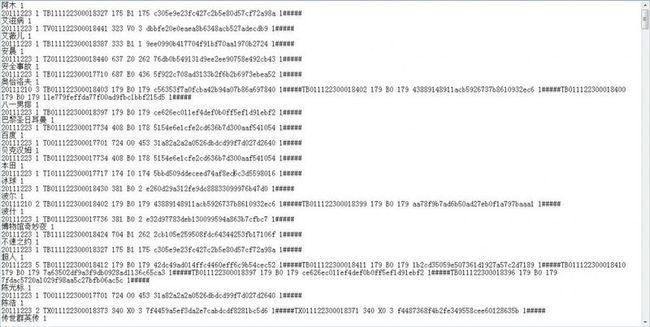
4.2、为关键词添上编码
如上图所示,已经满足需求了。但可以再在每个关键词的背后添加一个计数表示索引到了第多少个关键词:
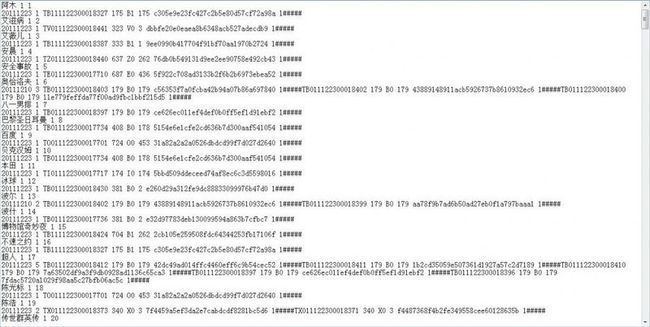
第五节、算法的二次改进
5.1、省去二次Hash
针对本文评论下读者的留言,做了下思考,自觉可以省去二次hash:
5.2、除去排序,针对不同日期的记录直接插入
综上5.1、5.2两节免去冒泡排序和,省去二次hash和免去冒泡排序,修改后如下:
修改后编译运行的效果图如下(用了另外一份更大的数据文件进行测试):

本章全部源码请到以下两处任一一处下载(欢迎读者朋友们继续优化,若能反馈于我,则幸甚不过了):
- http://download.csdn.net/detail/v_july_v/4012605(csdn下载处)
- https://github.com/fuxiang90/CreateInvertedIndex.(github下载处)