HashMap学习随笔
HashMap用的常有,但深入了解HashMap源码,数据结构,实现原理的人应该相对较少。今天闲暇之余,对HashMap的源码研究了一下。
HashMap在JAVA开发中,经常用到,需要使用键值对,但无需同步的,可以快速查找其中的元素,那么HashMap是怎么达到其快速定位无素的的呢?
1 首先谈一下HashMap的数据结构:
HashMap是一个由数据与链表构成的一种存储结构,水平方向是一种数组,页每个数组都是一个链表的头部。如下图:
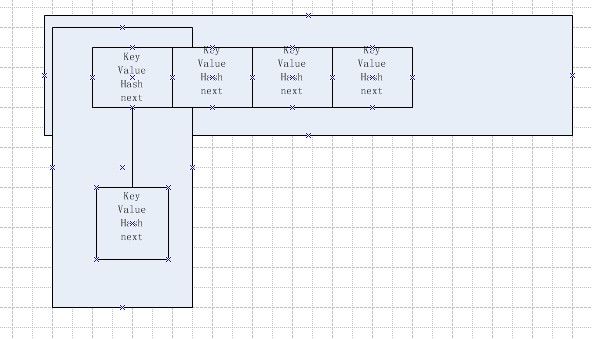
上图中,X轴方向为HashMap的数组容器,Y轴方向,为每个相应位置的单向链表。每一个元素都是一个包含如图所示四个属性,key,value,hash,next的一种数据结构,即EntrySet,其中的next指向Y轴方向其下一个元素.
现在知道HashMap的数据结构了,那么其实现又是怎么样的?
2 HashMap的实现
首先看一下HashMap的构造函数(可能用的比较多的是,无参构造函数)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
loadFactor :加载因子,加载因子与HashMap resize有关。默认为0.75
capacity:容器大小,默认值为16 其大小为上面所说的数据结构中数组的长度。
table:即为上面数据结构图中,X方向的数组(transient Entry[] table;)
threshold :resize的临界值,即当HashMap中无素个数达到该值时,HashMap就会调用其resize方法,重新扩充大小。
从下面的代码中:
while (capacity < initialCapacity)
capacity <<= 1;
可以看出,capacity的值是2的倍数,为什么?为什么?在下面我会讲到。
创建HashMap之后,我们得到了一个空的hashMap容器,我们接下来的可能就是往容器里面放我们的元素了。
public V put(K key, V value)
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
当你的key为null时,会调用putForNullKey,HashMap允许key为null,这样的对像是放在table[0]中。
如果不为空,则调用int hash = hash(key.hashCode());这是hashmap的一个自定义的hash,在key.hashCode()基础上进行二次hash
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
这样做的目的就是为了改进传统的hash方法,而且尽量保证key的每一位都会影响到最后的hash值,以达到减少hash冲突的目的.再看indexFor方法:
hashMap是根据这个方法定位到某个元素,将要存储在X方向,即table数组的哪个位置。
static int indexFor(int h, int length) {
return h & (length-1);
}
就一行代码,将key的二次hash值,与长度减一进行与操作,这一步可谓经典,通常我们会用取模的方式来定位数组中的某个位置,但是hashMap却用这种方法,而且length即capacity的值,面capacity又是2的倍数,减1之后,表示成二进制就全部是1了,那么与全部为1的一个数进行与操作,速度会大大提升了。这就是为什么"capacity的值是2的倍数"
位定到具体的列之后,hashMap会遍历该列的所有元素,当以该key的无素已经存在是,会将其value替换,并返回其原值。否则会重新创建一个新的EntrySet并放在table[indexFor(hash, table.length)]的位置上,并将之前该列的链表,设为其next。最后是判断hashmap中元素的个数是否达到了threshold ,如果达到了则将其容器扩大到原来的2倍。如下所示:
resize(2 * table.length);
当然hashMap的get 方法,是首先通过通过key的两次hash值与数组的长度(capacity)进行于操作,定位到数组的某个位置,然后对该列的链表进行遍历,一般情况下,hashMap的这种查找速度是非常快的,hash值相同的元素过多,就会造成链表中数据很多,而链表中的数据查找是通过遍历所有链表中的元素进行的,这可能会影响到查找速度,找到即返回,这里需要注意的是,返回为null时,你不能判断是找到了,还是在hashmap中存着一个value为null的元素,因为hashmap允许value为null.
HashMap有一些比较重新的方法,比如resize,putAll,remove等,我都认真的看过。感觉代码写的非常精致。希望有兴趣的朋友也认直的去看一下。
说到HashMap不是线程完全的情况,可以用Map Collections.synchronizedMap(Map m) 或者HashTable去实现。