关于resin ping超时的问题
最近遇到一个很奇怪的问题,就是在高峰期的时候,resin会ping ok超时(这是resin的一个自动检查工具,在conf/resin.conf配置),如下图:
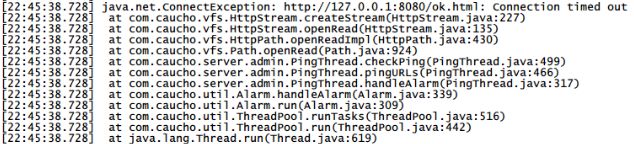
三次以上超时的话就会自动重启,因为之前没有过这方面的经验,所以解决起来很费劲,走了很多弯路(由于每次超时基本上都会有Forcing GC due to low memory这样的字眼,所以开始误以为是内存泄露),下面是分析经过,希望对有些人有帮助。
我在服务器ping超时的时候dump了一些信息(dump脚本文章末尾给出),我们来分析一下:
首先看load:21:58:15 up 34 days, 1:24, 2 users, load average: 0.32, 0.28, 0.27
很明显load不高。
再看top:
USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
root 18 0 12.1g 10g 89m S 21.7 70.0 203:49.72 java
cpu占用率也不高,这表示java没有进行密集的cpu计算,java内存占了70%,也就是15.6G*0.7=10.96G
再看看堆内存信息:
Eden Space:
capacity = 5910298624 (5636.5MB)
used = 5481955816 (5228.000465393066MB)
free = 428342808 (408.4995346069336MB)
92.75260295206363% used
From Space:
capacity = 190119936 (181.3125MB)
used = 0 (0.0MB)
free = 190119936 (181.3125MB)
0.0% used
To Space:
capacity = 190578688 (181.75MB)
used = 0 (0.0MB)
free = 190578688 (181.75MB)
0.0% used
PS Old Generation
capacity = 4194304000 (4000.0MB)
used = 2836024848 (2704.644058227539MB)
free = 1358279152 (1295.355941772461MB)
67.61610145568848% used
PS Perm Generation
capacity = 190840832 (182.0MB)
used = 99512072 (94.90210723876953MB)
free = 91328760 (87.09789276123047MB)
52.144014966356885% used
总共申请到的内存一共有:5636.5+181.3125+181.75+4000+182=10255.8125MB/1024M=10.015G,这说明JNI调用花费的内存为10.96-10.015=0.945G,JNI不存在内存泄漏。
可能有人觉得Eden用了92%,是不是太高了点,这很正常,它马上会被回收掉,我们可以再看看另一台服务器的堆内存信息:
Eden Space:
capacity = 9814802432 (9360.125MB)
used = 1181853960 (1127.1037673950195MB)
free = 8632948472 (8233.02123260498MB)
12.041546105367392% used
From Space:
capacity = 337051648 (321.4375MB)
used = 245305144 (233.94121551513672MB)
free = 91746504 (87.49628448486328MB)
72.7796898355471% used
To Space:
capacity = 333905920 (318.4375MB)
used = 0 (0.0MB)
free = 333905920 (318.4375MB)
0.0% used
PS Old Generation
capacity = 8388608000 (8000.0MB)
used = 3622388416 (3454.5787963867188MB)
free = 4766219584 (4545.421203613281MB)
43.18223495483399% used
PS Perm Generation
capacity = 100728832 (96.0625MB)
used = 100571056 (95.91203308105469MB)
free = 157776 (0.1504669189453125MB)
99.84336560161842% used
这样看来内存是完全够用的,Perm设置为256M,之后还会膨胀,所以99%也没什么。
我们再来看看gc信息:
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
185664.0 186112.0 0.0 0.0 5771776.0 5330191.7 4096000.0 2769555.5 186368.0 97179.8 266 106.315 5 19.005 125.320
我也没看出来有什么异常。
我们来总结一下:
内存够用
cpu也没有进行大量的操作
gc正常
关键是也没有发生oom异常(这表示内存够用)
另外,并不是每次超时之前resin都会打印Forcing GC due to low memory这样的字眼
所以,我认为不是内存泄漏的原因,也就不用再分析2G多大的heap文件了。
如果不是内存泄漏的原因,那么到底是什么原因呢?
有两个因素引起了我的注意:
1.以前也有过这种情况,但是也没有这么频繁,最近开始变得有点频繁了
2.我统计了发生超时的时间,绝大部分都集中在访问的高峰期
整个问题的关键因素是搞清楚resin为什么会ping超时,是cpu忙不过来了?不是,是网络堵了?也不是,是内存不够?也不是,那到底是为什么呢?上述信息明显不够,于是我在服务器上开启了resin的access.log;从access.log上可以看出,有大量的最近刚上线的请求,这是不是就是最近频繁发生的原因呢?另外,我在服务器发生超时的时候接了一个图:
从截图来看,22:45:38发生一次超时,从access.log来看,前一次ping发生在22:44:17,第二次ping发生在22:45:45,照理说,ping是每隔1分钟ping的,也就是说第二次ping应该发生在22:45:17,但是却发生在22:45:45,中间这个误差就是超时的时间。也就是说这个ping操作完全没有连接上resin,突然想到,不是cpu忙不过,不是内存不够,那极有可能是达到了最大连接数限制了,刚开始我以为是thread-max配置最大连接数,后来仔细查了资料,发现不是这么回事。
Thread-max是thread-pool配置的,threadpool就是一个加工厂,每个thread都是一个工人,它们处理来自tcp连接的请求,所以不是连接数的设置。从网上找的资料,下了一个resin3.0.21源码包,找到Port类:
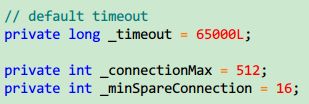
我没有去查找_connectionMax是否动态设置,但是据网上说resin是写死了的(又有的人说是pro专业版提供配置,但是我看Port类提供了动态设置的方法),也就是说最大连接数不能超过512个,看看代码:
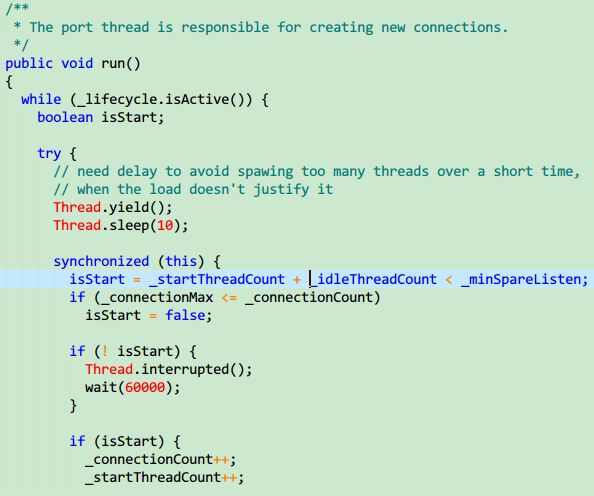
Port线程负责创建新的tcp连接,上面是代码,从这里可以看出,如果超出了最大连接数,就会等待60s,这个时间,ping早就超时了!!
那么我们的ping超时的时候,最大连接数到底是多少呢?幸好我当时也一并dump下了jstack,查找resin-tcp-connection-*:8080-,一共有515个这样的线程,除去"resin-tcp-connection-*:8080-101-EventThread"、"resin-tcp-connection-*:8080-101-SendThread(UserZooKeeper5:2181)"、"resin-tcp-connection-*:8080-101-SendThread(UserZooKeeper3:2181)"这三个不是用户tcp连接(是什么我也不知道),刚好剩下512个线程,这是巧合吗?好吧,我们再看看线上没有问题服务的tcp连接数,搜索resin-tcp-connection-*:8080-,一共是286个,小于512,这也是巧合吗?种种迹象表明,在ping超时时,我们的连接数达到了最大值512!!
最后的解决方法是,我参考了网上的方法,为resin加大了连接数,<http server-id="" host="*" port="8080" connection-max="700"/>
======================================dump脚本======================================
#!/bin/bash export JAVA_HOME=/opt/j2sdk export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH time=`date +"%Y-%m-%d-%H:%M:%S"` dir="/data/dump" if [ ! -x $dir ] then mkdir $dir fi #load w > $dir/load_$time.data echo load done! #java cpu/mem top -n 1 > $dir/top_$time.data echo top done! #resin pid pid=`/opt/j2sdk/bin/jps | grep Resin | cut -d' ' -f1` echo resin pid is $pid... #gc jstat -gc $pid > $dir/gc_$time.data echo gc done! #heap info jmap -heap $pid > $dir/heapinfo_$time.data echo heap info done! #histo jmap -histo:live $pid > $dir/histo_$time.data echo histo done! #heap dump jmap -dump:live,format=b,file=$dir/heapdump_$time.bin $pid echo heap dump done! #jstack jstack $pid > $dir/jstack_$time.data echo jstack done!