iOS应用架构谈(二):View层的组织和调用方案(中)
关于MVC、MVVM等一大堆思想
其实这些都是相对通用的思想,万变不离其宗的还是在开篇里面我提到的那三个角色:数据管理者,数据加工者,数据展示者。这些五花八门的思想,不外乎就是制订了一个规范,规定了这三个角色应当如何进行数据交换。但同时这些也是争议最多的话题,所以我在这里来把几个主流思想做一个梳理,当你在做View层架构时,能够有个比较好的参考。
MVC
MVC(Model-View-Controller)是最老牌的的思想,老牌到4人帮的书里把它归成了一种模式,其中Model就是作为数据管理者,View作为数据展示者,Controller作为数据加工者,Model和View又都是由Controller来根据业务需求调配,所以Controller还负担了一个数据流调配的功能。正在我写这篇文章的时候,我看到InfoQ发了这篇文章,里面提到了一个移动开发中的痛点是:对MVC架构划分的理解。我当时没能够去参加这个座谈会,也没办法发表个人意见,所以就只能在这里写写了。
在iOS开发领域,我们应当如何进行MVC的划分?
这里面其实有两个问题:
为什么我们会纠结于iOS开发领域中MVC的划分问题?
在iOS开发领域中,怎样才算是划分的正确姿势?
为什么我们会纠结于iOS开发领域中MVC的划分问题?
关于这个,每个人纠结的点可能不太一样,我也不知道当时座谈会上大家的观点。但请允许我猜一下:是不是因为UIViewController中自带了一个View,且控制了View的整个生命周期(viewDidLoad,viewWillAppear...),而在常识中我们都知道Controller不应该和View有如此紧密的联系,所以才导致大家对划分产生困惑?,下面我会针对这个猜测来给出我的意见。
在服务端开发领域,Controller和View的交互方式一般都是这样,比如Yii:
/*
...
数据库取数据
...
处理数据
...
*/
// 此处$this就是Controller
$this->render("plan",array(
'planList' => $planList,
'plan_id' => $_GET['id'],
));
这里Controller和View之间区分得非常明显,Controller做完自己的事情之后,就把所有关于View的工作交给了页面渲染引擎去做,Controller不会去做任何关于View的事情,包括生成View,这些都由渲染引擎代劳了。这是一个区别,但其实服务端View的概念和Native应用View的概念,真正的区别在于:从概念上严格划分的话,服务端其实根本没有View,拜HTTP协议所赐,我们平时所讨论的View只是用于描述View的字符串(更实质的应该称之为数据),真正的View是浏览器。。
所以服务端只管生成对View的描述,至于对View的长相,UI事件监听和处理,都是浏览器负责生成和维护的。但是在Native这边来看,原本属于浏览器的任务也逃不掉要自己做。那么这件事情由谁来做最合适?苹果给出的答案是:UIViewController。
鉴于苹果在这一层做了很多艰苦卓绝的努力,让iOS工程师们不必亲自去实现这些内容。而且,它把所有的功能都放在了UIView上,并且把UIView做成不光可以展示UI,还可以作为容器的一个对象。
看到这儿你明白了吗?UIView的另一个身份其实是容器!UIViewController中自带的那个view,它的主要任务就是作为一个容器。如果它所有的相关命名都改成ViewContainer,那么代码就会变成这样:
- (void)viewContainerDidLoad
{
[self.viewContainer addSubview:self.label];
[self.viewContainer addSubview:self.tableView];
[self.viewContainer addSubview:self.button];
[self.viewContainer addSubview:self.textField];
}
... ...
仅仅改了个名字,现在是不是感觉清晰了很多?如果再要说详细一点,我们平常所认为的服务端MVC是这样划分的:
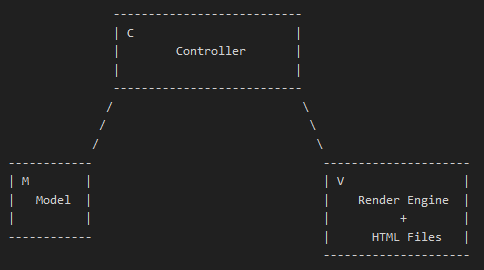
但事实上,整套流程的MVC划分是这样:
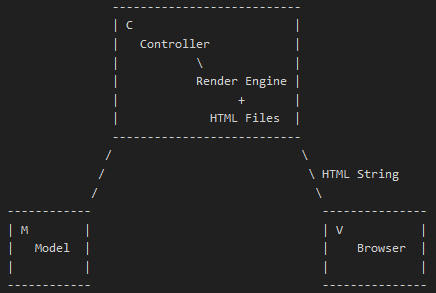
由图中可以看出,我们服务端开发在这个概念下,其实只涉及M和C的开发工作,浏览器作为View的容器,负责View的展示和事件的监听。那么对应到iOS客户端的MVC划分上面来,就是这样:

唯一区别在于,View的容器在服务端,是由Browser负责,在整个网站的流程中,这个容器放在Browser是非常合理的。在iOS客户端,View的容器是由UIViewController中的view负责,我也觉得苹果做的这个选择是非常正确明智的。
因为浏览器和服务端之间的关系非常松散,而且他们分属于两个不同阵营,服务端将对View的描述生成之后,交给浏览器去负责展示,然而一旦view上有什么事件产生,基本上是很少传递到服务器(也就是所谓的Controller)的(要传也可以:AJAX),都是在浏览器这边把事情都做掉,所以在这种情况下,View容器就适合放在浏览器(V)这边。
但是在iOS开发领域,虽然也有让View去监听事件的做法,但这种做法非常少,都是把事件回传给Controller,然后Controller再另行调度。所以这时候,View的容器放在Controller就非常合适。Controller可以因为不同事件的产生去很方便地更改容器内容,比如加载失败时,把容器内容换成失败页面的View,无网络时,把容器页面换成无网络的View等等。
在iOS开发领域中,怎样才算是MVC划分的正确姿势?
这个问题其实在上面已经解答掉一部分了,那么这个问题的答案就当是对上面问题的一个总结吧。
M应该做的事:
给ViewController提供数据
给ViewController存储数据提供接口
提供经过抽象的业务基本组件,供Controller调度
C应该做的事:
管理View Container的生命周期
负责生成所有的View实例,并放入View Container
监听来自View与业务有关的事件,通过与Model的合作,来完成对应事件的业务。
V应该做的事:
响应与业务无关的事件,并因此引发动画效果,点击反馈(如果合适的话,尽量还是放在View去做)等。
界面元素表达
我通过与服务端MVC划分的对比来回答了这两个问题,之所以这么做,是因为我知道有很多iOS工程师之前是从服务端转过来的。我也是这样,在进安居客之前,我也是做服务端开发的,在学习iOS的过程中,我也曾经对iOS领域的MVC划分问题产生过疑惑,我疑惑的点就是前面开篇我猜测的点。如果有人问我iOS中应该怎么做MVC的划分,我就会像上面这么回答。
MVCS
苹果自身就采用的是这种架构思路,从名字也能看出,也是基于MVC衍生出来的一套架构。从概念上来说,它拆分的部分是Model部分,拆出来一个Store。这个Store专门负责数据存取。但从实际操作的角度上讲,它拆开的是Controller。
这算是瘦Model的一种方案,瘦Model只是专门用于表达数据,然后存储、数据处理都交给外面的来做。MVCS使用的前提是,它假设了你是瘦Model,同时数据的存储和处理都在Controller去做。所以对应到MVCS,它在一开始就是拆分的Controller。因为Controller做了数据存储的事情,就会变得非常庞大,那么就把Controller专门负责存取数据的那部分抽离出来,交给另一个对象去做,这个对象就是Store。这么调整之后,整个结构也就变成了真正意义上的MVCS。
关于胖Model和瘦Model
我在面试和跟别人聊天时,发现知道胖Model和瘦Model的概念的人不是很多。大约两三年前国外业界曾经对此有过非常激烈的讨论,主题就是Fat model, skinny controller。现在关于这方面的讨论已经不多了,然而直到今天胖Model和瘦Model哪个更好,业界也还没有定论,所以这算是目前业界悬而未解的一个争议。我很少看到国内有讨论这个的资料,所以在这里我打算补充一下什么叫胖Model什么叫瘦Model。以及他们的争论来源于何处。
什么叫胖Model?
胖Model包含了部分弱业务逻辑。胖Model要达到的目的是,Controller从胖Model这里拿到数据之后,不用额外做操作或者只要做非常少的操作,就能够将数据直接应用在View上。举个例子:
Raw Data: timestamp:1234567 FatModel: @property (nonatomic, assign) CGFloat timestamp; - (NSString *)ymdDateString; // 2015-04-20 15:16 - (NSString *)gapString; // 3分钟前、1小时前、一天前、2015-3-13 12:34 Controller: self.dateLabel.text = [FatModel ymdDateString]; self.gapLabel.text = [FatModel gapString];
把timestamp转换成具体业务上所需要的字符串,这属于业务代码,算是弱业务。FatModel做了这些弱业务之后,Controller就能变得非常skinny,Controller只需要关注强业务代码就行了。众所周知,强业务变动的可能性要比弱业务大得多,弱业务相对稳定,所以弱业务塞进Model里面是没问题的。另一方面,弱业务重复出现的频率要大于强业务,对复用性的要求更高,如果这部分业务写在Controller,类似的代码会洒得到处都是,一旦弱业务有修改(弱业务修改频率低不代表就没有修改),这个事情就是一个灾难。如果塞到Model里面去,改一处很多地方就能跟着改,就能避免这场灾难。
然而其缺点就在于,胖Model相对比较难移植,虽然只是包含弱业务,但好歹也是业务,迁移的时候很容易拔出萝卜带出泥。另外一点,MVC的架构思想更加倾向于Model是一个Layer,而不是一个Object,不应该把一个Layer应该做的事情交给一个Object去做。最后一点,软件是会成长的,FatModel很有可能随着软件的成长越来越Fat,最终难以维护。
什么叫瘦Model?
瘦Model只负责业务数据的表达,所有业务无论强弱一律扔到Controller。瘦Model要达到的目的是,尽一切可能去编写细粒度Model,然后配套各种helper类或方法来对弱业务做抽象,强业务依旧交给Controller。举个例子:
Raw Data:
{
"name":"casa",
"sex":"male",
}
SlimModel:
@property (nonatomic, strong) NSString *name;
@property (nonatomic, strong) NSString *sex;
Helper:
#define Male 1;
#define Female 0;
+ (BOOL)sexWithString:(NSString *)sex;
Controller:
if ([Helper sexWithString:SlimModel.sex] == Male) {
...
}
由于SlimModel跟业务完全无关,它的数据可以交给任何一个能处理它数据的Helper或其他的对象,来完成业务。在代码迁移的时候独立性很强,很少会出现拔出萝卜带出泥的情况。另外,由于SlimModel只是数据表达,对它进行维护基本上是0成本,软件膨胀得再厉害,SlimModel也不会大到哪儿去。
缺点就在于,Helper这种做法也不见得很好,这里有一篇文章批判了这个事情。另外,由于Model的操作会出现在各种地方,SlimModel在一定程度上违背了DRY(Don't Repeat Yourself)的思路,Controller仍然不可避免在一定程度上出现代码膨胀。
我的态度?嗯,我会在本门心法这一节里面说。
说回来,MVCS是基于瘦Model的一种架构思路,把原本Model要做的很多事情中的其中一部分关于数据存储的代码抽象成了Store,在一定程度上降低了Controller的压力。
MVVM
MVVM去年在业界讨论得非常多,无论国内还是国外都讨论得非常热烈,尤其是在ReactiveCocoa这个库成熟之后,ViewModel和View的信号机制在iOS下终于有了一个相对优雅的实现。MVVM本质上也是从MVC中派生出来的思想,MVVM着重想要解决的问题是尽可能地减少Controller的任务。不管MVVM也好,MVCS也好,他们的共识都是Controller会随着软件的成长,变很大很难维护很难测试。只不过两种架构思路的前提不同,MVCS是认为Controller做了一部分Model的事情,要把它拆出来变成Store,MVVM是认为Controller做了太多数据加工的事情,所以MVVM把数据加工的任务从Controller中解放了出来,使得Controller只需要专注于数据调配的工作,ViewModel则去负责数据加工并通过通知机制让View响应ViewModel的改变。
MVVM是基于胖Model的架构思路建立的,然后在胖Model中拆出两部分:Model和ViewModel。关于这个观点我要做一个额外解释:胖Model做的事情是先为Controller减负,然后由于Model变胖,再在此基础上拆出ViewModel,跟业界普遍认知的MVVM本质上是为Controller减负这个说法并不矛盾,因为胖Model做的事情也是为Controller减负。
另外,我前面说MVVM把数据加工的任务从Controller中解放出来,跟MVVM拆分的是胖Model也不矛盾。要做到解放Controller,首先你得有个胖Model,然后再把这个胖Model拆成Model和ViewModel。
那么MVVM究竟应该如何实现?
这很有可能是大多数人纠结的问题,我打算凭我的个人经验试图在这里回答这个问题,欢迎交流。
在iOS领域大部分MVVM架构都会使用ReactiveCocoa,但是使用ReactiveCocoa的iOS应用就是基于MVVM架构的吗?那当然不是,我觉得很多人都存在这个误区,我面试过的一些人提到了ReactiveCocoa也提到了MVVM,但他们对此的理解肤浅得让我忍俊不禁。嗯,在网络层架构我会举出不使用ReactiveCocoa的例子,现在举我感觉有点儿早。
MVVM的关键是要有View Model!而不是ReactiveCocoa
注:MVVM要有ViewModel,以及ReactiveCocoa带来的信号通知效果,在ReactiveCocoa里就是RAC等相关宏来实现。另外,使用ReactiveCocoa能够比较优雅地实现MVVM模式,就是因为有RAC等相关宏的存在。就像它的名字一样Reactive-响应式,这也是区分MVVM的VM和MVC的C和MVP的P的一个重要方面。
ViewModel做什么事情?就是把RawData变成直接能被View使用的对象的一种Model。举个例子:
Raw Data:
{
(
(123, 456),
(234, 567),
(345, 678)
)
}
这里的RawData我们假设是经纬度,数字我随便写的不要太在意。然后你有一个模块是地图模块,把经纬度数组全部都转变成MKAnnotation或其派生类对于Controller来说是弱业务,(记住,胖Model就是用来做弱业务的),因此我们用ViewModel直接把它转变成MKAnnotation的NSArray,交给Controller之后Controller直接就可以用了。
嗯,这就是ViewModel要做的事情,是不是觉得很简单,看不出优越性?
安居客Pad应用也有一个地图模块,在这里我设计了一个对象叫做reformer(其实就是ViewModel),专门用来干这个事情。那么这么做的优越性体现在哪儿呢?
安居客分三大业务:租房、二手房、新房。这三个业务对应移动开发团队有三个API开发团队,他们各自为政,这就造成了一个结果:三个API团队回馈给移动客户端的数据内容虽然一致,但是数据格式是不一致的,也就是相同value对应的key是不一致的。但展示地图的ViewController不可能写三个,所以肯定少不了要有一个API数据兼容的逻辑,这个逻辑我就放在reformer里面去做了,于是业务流程就变成了这样:
这么一来,原本复杂的MKAnnotation组装逻辑就从Controller里面拆分了出来,Controller可以直接拿着Reformer返回的数据进行展示。APIManager就属于Model,reformer就属于ViewModel。具体关于reformer的东西我会放在网络层架构来详细解释。Reformer此时扮演的ViewModel角色能够很好地给Controller减负,同时,维护成本也大大降低,经过reformer产出的永远都是MKAnnotation,Controller可以直接拿来使用。
然后另外一点,还有一个业务需求是取附近的房源,地图API请求是能够hold住这个需求的,那么其他地方都不用变,在fetchDataWithReformer的时候换一个reformer就可以了,其他的事情都交给reformer。
那么ReactiveCocoa应该扮演什么角色?
不用ReactiveCocoa也能MVVM,用ReactiveCocoa能更好地体现MVVM的精髓。前面我举到的例子只是数据从API到View的方向,View的操作也会产生"数据",只不过这里的"数据"更多的是体现在表达用户的操作上,比如输入了什么内容,那么数据就是text、选择了哪个cell,那么数据就是indexPath。那么在数据从view走向API或者Controller的方向上,就是ReactiveCocoa发挥的地方。
我们知道,ViewModel本质上算是Model层(因为是胖Model里面分出来的一部分),所以View并不适合直接持有ViewModel,那么View一旦产生数据了怎么办?扔信号扔给ViewModel,用谁扔?ReactiveCocoa。
在MVVM中使用ReactiveCocoa的第一个目的就是如上所说,View并不适合直接持有ViewModel。第二个目的就在于,ViewModel有可能并不是只服务于特定的一个View,使用更加松散的绑定关系能够降低ViewModel和View之间的耦合度。
那么在MVVM中,Controller扮演什么角色?
大部分国内外资料阐述MVVM的时候都是这样排布的:View <-> ViewModel <-> Model,造成了MVVM不需要Controller的错觉,现在似乎发展成业界开始出现MVVM是不需要Controller的。的声音了。其实MVVM是一定需要Controller的参与的,虽然MVVM在一定程度上弱化了Controller的存在感,并且给Controller做了减负瘦身(这也是MVVM的主要目的)。但是,这并不代表MVVM中不需要Controller,MMVC和MVVM他们之间的关系应该是这样:
(来源:http://www.sprynthesis.com/2014/12/06/reactivecocoa-mvvm-introduction/)
View <-> C <-> ViewModel <-> Model,所以使用MVVM之后,就不需要Controller的说法是不正确的。严格来说MVVM其实是MVCVM。从图中可以得知,Controller夹在View和ViewModel之间做的其中一个主要事情就是将View和ViewModel进行绑定。在逻辑上,Controller知道应当展示哪个View,Controller也知道应当使用哪个ViewModel,然而View和ViewModel它们之间是互相不知道的,所以Controller就负责控制他们的绑定关系,所以叫Controller/控制器就是这个原因。
前面扯了那么多,其实归根结底就是一句话:在MVC的基础上,把C拆出一个ViewModel专门负责数据处理的事情,就是MVVM。然后,为了让View和ViewModel之间能够有比较松散的绑定关系,于是我们使用ReactiveCocoa,因为苹果本身并没有提供一个比较适合这种情况的绑定方法。iOS领域里KVO,Notification,block,delegate和target-action都可以用来做数据通信,从而来实现绑定,但都不如ReactiveCocoa提供的RACSignal来的优雅,如果不用ReactiveCocoa,绑定关系可能就做不到那么松散那么好,但并不影响它还是MVVM。
在实际iOS应用架构中,MVVM应该出现在了大部分创业公司或者老牌公司新App的iOS应用架构图中,据我所知易宝支付旗下的某个iOS应用就整体采用了MVVM架构,他们抽出了一个Action层来装各种ViewModel,也是属于相对合理的结构。
所以Controller在MVVM中,一方面负责View和ViewModel之间的绑定,另一方面也负责常规的UI逻辑处理。
VIPER
VIPER(View,Interactor,Presenter,Entity,Routing)。VIPER我并没有实际使用过,我是在objc.io上第13期看到的。
但凡出现一个新架构或者我之前并不熟悉的新架构,有一点我能够非常肯定,这货一定又是把MVC的哪个部分给拆开了(坏笑,做这种判断的理论依据在第一篇文章里面我已经讲过了)。事实情况是VIPER确实拆了很多很多,除了View没拆,其它的都拆了。
我提到的这两篇文章关于VIPER都讲得很详细,一看就懂。但具体在使用VIPER的时候会有什么坑或者会有哪些争议我不是很清楚,硬要写这一节的话我只能靠YY,所以我想想还是算了。如果各位读者有谁在实际App中采用VIPER架构的或者对VIPER很有兴趣的,可以评论区里面提出来,我们交流一下。
编后语
为了更好地向读者输出更优质的内容,InfoQ将精选来自国内外的优秀文章,经过整理审校后,发布到网站。本篇文章作者为田伟宇,原文链接为Casa Taloyum。本文已由原作者授权InfoQ中文站转载。