我的架构演化笔记 9:ElasticSearch的分词器IK Analyzer动态添加分词
需求:动态添加词汇
先设计架构吧,这里用了单机Redis.

计划把词汇放在Redis里,然后ES里利用redis的pub/sub功能获取词汇。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
下面开始安装Redis,
吐个槽:Redis的版本更新还蛮快,我这1.0.2版本还不知道什么时候能够升级到最新版。。。
~~~~~~~
要想修改代码,需要对Lucene的原理有个大概的了解,知道分词器是什么时候以怎样的方式介入到索引过程中的。
为了描述方便,这里拿Lucene 4.0.0的源码作为例子,类---org.apache.lucene.index.DocumentWriter.
文件的140行有
// Tokenize field and add to postingTable
TokenStream stream = analyzer.tokenStream(fieldName, reader);
try {
for (Token t = stream.next(); t != null; t = stream.next()) {
position += (t.getPositionIncrement() - 1);
addPosition(fieldName, t.termText(), position++);
if (++length > maxFieldLength) break;
}
} finally {
stream.close();
}
那么咱们的IK分词器的Analyzer是哪个类呢?
看config/elasticsearch.yml配置来说,
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
package org.elasticsearch.index.analysis;
import org.elasticsearch.common.inject.Inject;
import org.elasticsearch.common.inject.assistedinject.Assisted;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.env.Environment;
import org.elasticsearch.index.Index;
import org.elasticsearch.index.settings.IndexSettings;
import org.wltea.analyzer.cfg.Configuration;
import org.wltea.analyzer.dic.Dictionary;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class IkAnalyzerProvider extends AbstractIndexAnalyzerProvider<IKAnalyzer> {
private final IKAnalyzer analyzer;
@Inject
public IkAnalyzerProvider(Index index, @IndexSettings Settings indexSettings, Environment env, @Assisted String name, @Assisted Settings settings) {
super(index, indexSettings, name, settings);
Dictionary.initial(new Configuration(env));
analyzer=new IKAnalyzer(indexSettings, settings, env);
}
@Override public IKAnalyzer get() {
return this.analyzer;
}
}
所以我认为真正的分词类是:org.wltea.analyzer.lucene.IKAnalyzer
接下来去看这个类的源码,看看有什么发现!
/** * IK 中文分词 版本 5.0.1 * IK Analyzer release 5.0.1 * * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * * 源代码由林良益([email protected])提供 * 版权声明 2012,乌龙茶工作室 * provided by Linliangyi and copyright 2012 by Oolong studio * */ package org.wltea.analyzer.lucene; import java.io.Reader; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.Tokenizer; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.env.Environment; /** * IK分词器,Lucene Analyzer接口实现 * 兼容Lucene 4.0版本 */ public final class IKAnalyzer extends Analyzer{ private boolean useSmart; public boolean useSmart() { return useSmart; } public void setUseSmart(boolean useSmart) { this.useSmart = useSmart; } /** * IK分词器Lucene Analyzer接口实现类 * * 默认细粒度切分算法 */ public IKAnalyzer(){ this(false); } /** * IK分词器Lucene Analyzer接口实现类 * * @param useSmart 当为true时,分词器进行智能切分 */ public IKAnalyzer(boolean useSmart){ super(); this.useSmart = useSmart; } Settings settings; Environment environment; public IKAnalyzer(Settings indexSetting,Settings settings, Environment environment) { super(); this.settings=settings; this.environment= environment; } /** * 重载Analyzer接口,构造分词组件 */ @Override protected TokenStreamComponents createComponents(String fieldName, final Reader in) { Tokenizer _IKTokenizer = new IKTokenizer(in , settings, environment); return new TokenStreamComponents(_IKTokenizer); } }
可以看到这个类直接继承了org.apache.lucene.analysis.Analyzer
寻找tokenStream方法没有找到,正在疑惑之际,看到了这个:
/**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , settings, environment);
return new TokenStreamComponents(_IKTokenizer);
}
看来Lucene1.4.3的版本和Lucene后续版本的接口已经有很多不同,但是原理肯定一样。
打开Lucene4.0.0版本的Analyser类一看,果然有一个方法:
protected abstract TokenStreamComponents createComponents(String fieldName,
Reader reader);
~~~~~~~~~~
也就是说,本质在于:
有可能是org.wltea.analyzer.lucene.IKAnalyzer.createComponents().getTokenStream()
而根据代码
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , settings, environment);
return new TokenStreamComponents(_IKTokenizer);
}
知道关键在于IKTokenizer类。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
IKTokenizer的源代码如下:
/** * IK 中文分词 版本 5.0.1 * IK Analyzer release 5.0.1 * * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * * 源代码由林良益([email protected])提供 * 版权声明 2012,乌龙茶工作室 * provided by Linliangyi and copyright 2012 by Oolong studio * * */ package org.wltea.analyzer.lucene; import org.apache.lucene.analysis.Tokenizer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.analysis.tokenattributes.TypeAttribute; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.env.Environment; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; import java.io.IOException; import java.io.Reader; /** * IK分词器 Lucene Tokenizer适配器类 * 兼容Lucene 4.0版本 */ public final class IKTokenizer extends Tokenizer { //IK分词器实现 private IKSegmenter _IKImplement; //词元文本属性 private final CharTermAttribute termAtt; //词元位移属性 private final OffsetAttribute offsetAtt; //词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量) private final TypeAttribute typeAtt; //记录最后一个词元的结束位置 private int endPosition; /** * Lucene 4.0 Tokenizer适配器类构造函数 * @param in */ public IKTokenizer(Reader in , Settings settings, Environment environment){ super(in); offsetAtt = addAttribute(OffsetAttribute.class); termAtt = addAttribute(CharTermAttribute.class); typeAtt = addAttribute(TypeAttribute.class); _IKImplement = new IKSegmenter(input , settings, environment); } /* (non-Javadoc) * @see org.apache.lucene.analysis.TokenStream#incrementToken() */ @Override public boolean incrementToken() throws IOException { //清除所有的词元属性 clearAttributes(); Lexeme nextLexeme = _IKImplement.next(); if(nextLexeme != null){ //将Lexeme转成Attributes //设置词元文本 termAtt.append(nextLexeme.getLexemeText().toLowerCase()); //设置词元长度 termAtt.setLength(nextLexeme.getLength()); //设置词元位移 offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition()); //记录分词的最后位置 endPosition = nextLexeme.getEndPosition(); //记录词元分类 typeAtt.setType(nextLexeme.getLexemeTypeString()); //返会true告知还有下个词元 return true; } //返会false告知词元输出完毕 return false; } /* * (non-Javadoc) * @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader) */ @Override public void reset() throws IOException { super.reset(); _IKImplement.reset(input); } @Override public final void end() { // set final offset int finalOffset = correctOffset(this.endPosition); offsetAtt.setOffset(finalOffset, finalOffset); } }
代码中有这么一句:
_IKImplement = new IKSegmenter(input , settings, environment);
再来看看IKSegmenter的类源代码:
/**
* 分词,获取下一个词元
* @return Lexeme 词元对象
* @throws java.io.IOException
*/
public synchronized Lexeme next()throws IOException{
Lexeme l = null;
while((l = context.getNextLexeme()) == null ){
/*
* 从reader中读取数据,填充buffer
* 如果reader是分次读入buffer的,那么buffer要 进行移位处理
* 移位处理上次读入的但未处理的数据
*/
int available = context.fillBuffer(this.input);
if(available <= 0){
//reader已经读完
context.reset();
return null;
}else{
//初始化指针
context.initCursor();
do{
//遍历子分词器
for(ISegmenter segmenter : segmenters){
segmenter.analyze(context);
}
//字符缓冲区接近读完,需要读入新的字符
if(context.needRefillBuffer()){
break;
}
//向前移动指针
}while(context.moveCursor());
//重置子分词器,为下轮循环进行初始化
for(ISegmenter segmenter : segmenters){
segmenter.reset();
}
}
//对分词进行歧义处理
this.arbitrator.process(context, useSmart);
//将分词结果输出到结果集,并处理未切分的单个CJK字符
context.outputToResult();
//记录本次分词的缓冲区位移
context.markBufferOffset();
}
return l;
}
终于找到了久违的next()函数,一切奥义尽在这个函数里。
~~~~~~~~
每个词元都是通过while((l = context.getNextLexeme()) == null ){...}
来完成的,继续看context.getNextLexeme()函数。
/**
* 返回lexeme
*
* 同时处理合并
* @return
*/
Lexeme getNextLexeme(){
//从结果集取出,并移除第一个Lexme
Lexeme result = this.results.pollFirst();
while(result != null){
//数量词合并
this.compound(result);
if(Dictionary.getSingleton().isStopWord(this.segmentBuff , result.getBegin() , result.getLength())){
//是停止词继续取列表的下一个
result = this.results.pollFirst();
}else{
//不是停止词, 生成lexeme的词元文本,输出
result.setLexemeText(String.valueOf(segmentBuff , result.getBegin() , result.getLength()));
break;
}
}
return result;
}
剩下的就是看
Dictionary.getSingleton()
看来使用了全局single instance模式。
那么词典是什么时候加载的呢?
/**
* 词典初始化
* 由于IK Analyzer的词典采用Dictionary类的静态方法进行词典初始化
* 只有当Dictionary类被实际调用时,才会开始载入词典,
* 这将延长首次分词操作的时间
* 该方法提供了一个在应用加载阶段就初始化字典的手段
* @return Dictionary
*/
public static Dictionary initial(Configuration cfg){
if(singleton == null){
synchronized(Dictionary.class){
if(singleton == null){
singleton = new Dictionary();
singleton.configuration=cfg;
singleton.loadMainDict();
singleton.loadSurnameDict();
singleton.loadQuantifierDict();
singleton.loadSuffixDict();
singleton.loadPrepDict();
singleton.loadStopWordDict();
return singleton;
}
}
}
return singleton;
}
也就是调用了Dictionary.initial()函数来加载词典。
那这个函数又是什么时候执行的呢?
~~~~~~~~
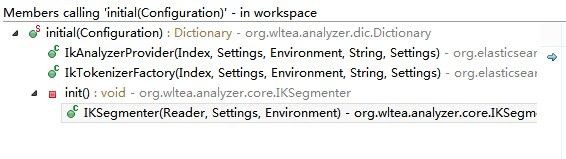
有好几个地方执行,当然每次执行都会判断之前是否执行过,这个通过
if(singleton == null){
synchronized(Dictionary.class){
if(singleton == null){
可以看出来。
~~~~~~~~~~~~~~~~
我猜测第1次应该是:
@Inject
public IkAnalyzerProvider(Index index, @IndexSettings Settings indexSettings, Environment env, @Assisted String name, @Assisted Settings settings) {
super(index, indexSettings, name, settings);
Dictionary.initial(new Configuration(env));
analyzer=new IKAnalyzer(indexSettings, settings, env);
}
下面回到任务:通过redis来发布词汇和停词。
思路:
1)修改es下面的elasticsearch-analysis-ik-1.2.6.jar,解压缩,将Dictionary.class反编译成java文件,添加如下2个函数
public void addMainWords(Collection<String> words)
{
if (words != null) {
for (String word : words) {
if (word != null) {
singleton._MainDict.fillSegment(word.trim().toLowerCase().toCharArray());
}
}
}
}
public void addStopWords(Collection<String> words)
{
if (words != null) {
for (String word : words) {
if (word != null) {
singleton._StopWords.fillSegment(word.trim().toLowerCase().toCharArray());
}
}
}
}
再打包回elasticsearch-analysis-ik-1.2.6.jar放到服务器里。
可以正常运行,说明这部分代码没有问题。获得了全局的词典集合句柄。
如何从Redis里获取数据呢?
一个办法是写一个线程
内容如下:
package org.wltea.analyzer.dic;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.Date;
import java.lang.Thread;
import redis.clients.jedis.Jedis;
import org.elasticsearch.common.logging.ESLogger;
import org.elasticsearch.common.logging.Loggers;
import org.wltea.analyzer.dic.Dictionary;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
public class DictThread extends Thread {
private static DictThread dt=null;
public static DictThread getInstance(){
DictThread result = null;
synchronized(DictThread.class){
if(null==dt){
dt = new DictThread();
result = dt;
}
}
return result;
}
private DictThread() {
this.logger = Loggers.getLogger("redis-thread");
this.init();
}
private Jedis jc=null;
private ESLogger logger = null;
public void run() {
while (true) {
this.logger.info("[Redis Thread]" + "*****cycle of redis");
init();
pull();
sleep();
}
}
public void pull() {
if (null == jc)
return;
// 从集合里拉取
ArrayList<String> words = new ArrayList<String>();
Set set = null;
// 1拉取主词
set = jc.smembers("ik_main");
Iterator t = set.iterator();
while (t.hasNext()) {
Object obj = t.next();
words.add(obj.toString());
}
Dictionary.getSingleton().addMainWords(words);
words.clear();
// 2拉取停词
set = jc.smembers("ik_stop");
t = set.iterator();
while (t.hasNext()) {
Object obj = t.next();
words.add(obj.toString());
}
Dictionary.getSingleton().addStopWords(words);
words.clear();
}
private void init() {
if (null == jc) {
////Set<HostAndPort> jedisClusterNodes = new HashSet<HostAndPort>();
// Jedis Cluster will attempt to discover cluster nodes
// automatically
//jedisClusterNodes.add(new HostAndPort("192.168.56.200", 6379));
//jc = new JedisCluster(jedisClusterNodes);
jc = new Jedis("192.168.56.200",6379);
}
}
private void sleep() {
// sleep 5 seconds,then loop to next
try {
Thread.sleep(5 * 1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
下面的问题就是启动这个线程!
package org.elasticsearch.index.analysis;
import org.elasticsearch.index.analysis.IkAnalyzerProvider;
import org.elasticsearch.common.inject.Inject;
import org.elasticsearch.common.inject.assistedinject.Assisted;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.env.Environment;
import org.elasticsearch.index.Index;
import org.elasticsearch.index.settings.IndexSettings;
import org.wltea.analyzer.cfg.Configuration;
import org.wltea.analyzer.dic.Dictionary;
import org.wltea.analyzer.lucene.IKAnalyzer;
import org.elasticsearch.common.logging.ESLogger;
import org.elasticsearch.common.logging.Loggers;
import org.wltea.analyzer.dic.DictThread;
public class SpecificIkAnalyzerProvider extends IkAnalyzerProvider {
private ESLogger logger = null;
@Inject
public SpecificIkAnalyzerProvider(Index index, @IndexSettings Settings indexSettings, Environment env, @Assisted String name, @Assisted Settings settings) {
super(index, indexSettings, env, name, settings);
//here, let us start our pull thread... :)
this.logger = Loggers.getLogger("SpecificIkAnalyzerProvider");
this.logger.info("[SpecificIkAnalyzerProvider] system start,begin to start pull redis thread...");
//new DictThread().start();
DictThread dt = DictThread.getInstance();
if(null!=dt){
dt.start();
}
}
}
上面的代码在获取redis那部分其实还有一部分工作要优化,以后有时间再弄吧。
然后修改配置文件,修改分词器为:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
修改为:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.SpecificIkAnalyzerProvider
PS:吐槽,这网上下的jar反编译工具把我坑惨了,浪费了很多时间!