Solr4.10和ANSJ 中文分词集成
1. 具体代码
1.1 ANSJTokenizerFactory 工厂类
package org.ansj.solr;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeFactory;
import java.io.IOException;
import java.io.Reader;
import java.util.Map;
public class ANSJTokenizerFactory extends TokenizerFactory {
private ThreadLocal<ANSJTokenizer> tokenizerLocal = new ThreadLocal<ANSJTokenizer>();
/** Creates a new ANSJTokenizerFactory */
public ANSJTokenizerFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
if (!args.isEmpty()) {
throw new IllegalArgumentException("Unknown parameters: " + args);
}
}
@Override
public ANSJTokenizer create(AttributeFactory factory, Reader input) {
ANSJTokenizer tokenizer = tokenizerLocal.get();
if(tokenizer == null) {
tokenizer = newTokenizer(factory, input);
}
try {
tokenizer.setReader(input);
} catch (IOException e) {
tokenizer = newTokenizer(factory, input);
}
return tokenizer;
}
private ANSJTokenizer newTokenizer(AttributeFactory factory, Reader input) {
ANSJTokenizer tokenizer = new ANSJTokenizer(factory, input);
tokenizerLocal.set(tokenizer);
return tokenizer;
}
}
1.2 ANSJTokenizer类
package org.ansj.solr;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.Reader;
import java.io.Writer;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.util.AttributeFactory;
import org.ansj.domain.Term;
import org.ansj.splitWord.Analysis;
import org.ansj.splitWord.analysis.ToAnalysis;
public final class ANSJTokenizer extends Tokenizer {
Analysis udf = null;
private int offset = 0, bufferIndex=0, dataLen=0;
private final static int MAX_WORD_LEN = 255;
private final static int IO_BUFFER_SIZE = 1024;
private final char[] buffer = new char[MAX_WORD_LEN];
private final char[] ioBuffer = new char[IO_BUFFER_SIZE];
private int length;
private int start;
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
private final TypeAttribute typeAtt = (TypeAttribute)addAttribute(TypeAttribute.class);
public ANSJTokenizer(Reader in) {
super(in);
}
public ANSJTokenizer(AttributeFactory factory, Reader in) {
super(factory, in);
}
public Analysis getAnalysis()
{
udf = new ToAnalysis(input);
return udf;
}
private final boolean flush() {
if (length>0) {
//System.out.println(new String(buffer, 0,
//length));
termAtt.copyBuffer(buffer, 0, length);
offsetAtt.setOffset(correctOffset(start), correctOffset(start+length));
return true;
}
else
return false;
}
@Override
public boolean incrementToken() throws IOException {
clearAttributes();
if(udf == null)
{
udf = getAnalysis();
}
Term term = udf.next();
if(term != null) {
termAtt.copyBuffer(term.getName().toCharArray(), 0, term.getName().length());
//if the text has newline, then the first word in the newly started line will have start position 1, which will
//cause the if condition failed, in original code, it can cause serious problem.
if(term.getTo().getOffe() < term.getOffe() || term.getTo().getOffe() < 0)
{
offsetAtt.setOffset(term.getOffe(), term.getOffe() +term.getName().length());
typeAtt.setType("word");
return true;
}
//added by xiao for debugging
else
{
offsetAtt.setOffset(term.getOffe(), term.getTo().getOffe());
typeAtt.setType("word");
return true;
}
} else {
end();
return false;
}
}
@Override
public final void end() throws IOException {
super.end();
// set final offset
final int finalOffset = correctOffset(offset);
this.offsetAtt.setOffset(finalOffset, finalOffset);
}
@Override
public void reset() throws IOException {
super.reset();
offset = bufferIndex = dataLen = 0;
udf = new ToAnalysis(input);
}
@Override
public void close() throws IOException {
super.close();
offset = bufferIndex = dataLen = 0;
}
}
2. 打包ansj工程,将导出的jar包添加到solr.war中的WEB-INF\lib\目录,同样将ansj依赖的nlp-lang.jar包添加,不然会报错。
3. 将ansj下的resources目录拷贝到solr的example目录,不然运行solr时会说找不到词性文件。有其他配置方法,但我没想到。
4. 修改solr自带例子的schema.xml文件,添加如下两行
<field name="chinese_ansj_text" type="text_cn" indexed="true" stored="true" /> <fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.ansj.solr.ANSJTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.ansj.solr.ANSJTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
修改solr的exampledocs中的gb18030-example,增加一行
<add> <doc> <field name="id">GB18030TEST</field> <field name="name">Test with some GB18030 encoded characters</field> <field name="features">No accents here</field> <field name="features">这是一个功能</field> <field name="features">This is a feature (translated)</field> <field name="features">这份文件是很有光泽</field> <field name="features">This document is very shiny (translated)</field> <field name="price">0</field> <field name="inStock">true</field> <field name="chinese_ansj_text">这份文件是很有光泽</field> </doc> </add>
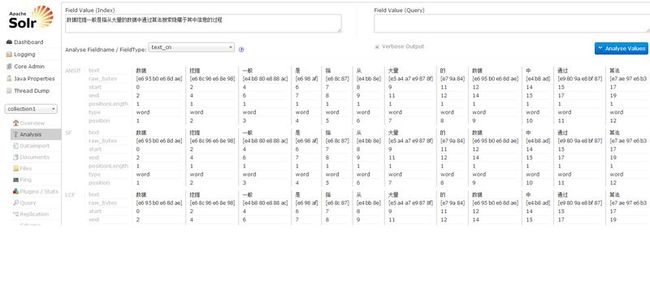
5.做实验,在solr的analysis页面中输入“数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程”,点击analyze,显示
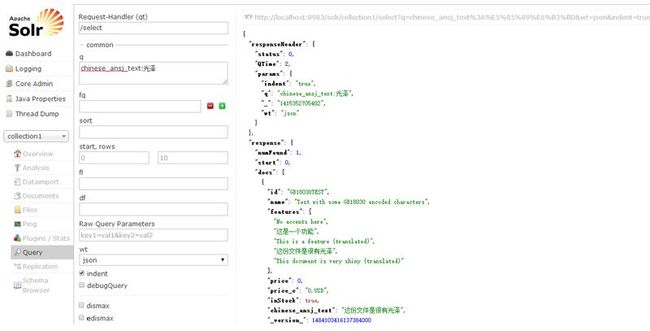
在Solr管理端的Query输入chinese_ansj_text:光泽,点击查询,显示结果