自学习 与 无监督特征学习
基本内容
在之前课程的基础上,本章的内容很好理解。
比如要对手写数字进行识别,我们拥有大量未标注的和少量已标注的手写数字图片。图片是灰度图,尺寸是 28×28(=784),可以将 784 维向量直接作为输入,但此时模型复杂度较高,也没有减小噪音和次要特征的影响。所以如果能提取原数据的主要特征作为输入,可以提高预测的准确度。
稀疏自动编码器就是一个很好的特征选择算法。
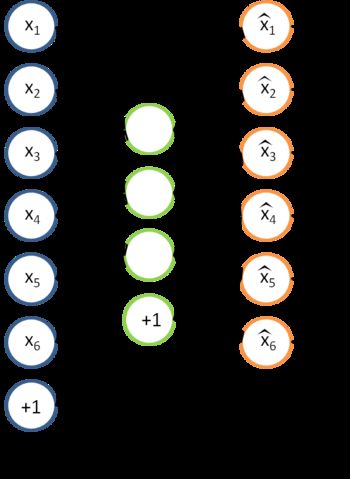
经过训练,隐藏层的输出(Features)可以替代原数据作为分类算法的输入。
基本概念就这么多,本章的难点在于理论与实践的结合。
课后作业
先吐槽一下 oschina 博客的代码插件,没有 Matlab 选项却有 Google Go,oschina 认为 Go 比 Matlab 应用更广泛吗?
![]()
这也是我在这个系列文章里不贴代码只给链接的原因。
主要代码及运算结果
代码地址
stlExercise.m - 程序的入口和主线


稀疏自编码器可视化:

使用提取出的特征训练 Softmax 分类器,测试结果:
![]()
使用原数据训练 Softmax 分类器,测试结果:
![]()
加入数据白化
如果在交给稀疏自编码器提取特征之前,对原数据做一些预处理结果会怎样?
我们知道对图像数据做白化处理可以平滑去噪、减小特征之间的相关性。下面就看看加入数据白化后的结果。



图1是原始图像、图2是白化后的图像、图3是稀疏自编码器学到的特征。
预测准确度为:
![]()
白化的准确度反而略低,原因可能是:
自然图片场景复杂、噪音多且局部特征高度相关,这些因素对模型训练起到负面影响,干扰了模型对目标物体的识别,所以零均值化和白化等预处理常用于自然图片。
而 MNIST 所提供的手写数字图片构图很简单:只有深色背景和浅色数字,且噪音很少。即使背景与数字内部的像素灰度各自高度相关,但这种相关恰好把主要信息与无关信息区分开来,所以不做预处理是可行的。相反,白化使图像更平滑,反而模糊了数字边界。
关于自然图像的白化,推荐 一篇文章。
稀疏自动编码器与分类器使用同一组数据
之前作业中使用标记为 {5,6,7,8,9} 的数据训练稀疏自编码器,然而模型的目标是对 {0,1,2,3,4} 进行识别。直观上,使用数据集 A 训练的稀疏自编码器所提取的特征与 A 较相关,此时,用它来对数据集 B 做特征提取更可能导致数据失真。
为了验证这个想法,稀疏自编码器和分类器都使用标记为 {0,1,2,3,4} 的数据来训练:
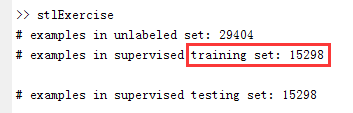
之前的 unlabeled data 有 29404 之多,而现在使用 training data 只有 15298,且 autoencoder 与 softmax 共用,只不过 autoencoder 不使用相应的 training labels。
计算结果:
![]()
可以看到在训练数据减半的情况下预测准确度依然小有提升。
总结
对于手写数字识别,白化并无必要;训练稀疏自编码器的无标记数据对特征自动提取有一定影响,但不大。如果考虑到手写数字的倾斜,也可对图片做纠偏(deskewing),使数字的纵向主轴保持垂直。
下面是将一些不同的神经网络模型应用在 MNIST 数据上的计算结果:

我所截取的几条都是较接近本文所采用模型的方法,其中表现最好的模型的预测准确度在 98%-99% 之间(表格第2列给出预处理方法;表格第3列给出错误率)。
补充说明:MNIST 包括一个 training set 和 一个 test set,截图中的模型均使用 training set 训练,使用 test set 测试。而本文将 training set 等分成两个子集 S1 和 S2,其中 S1 包含所有 {5,6,7,8,9},用来训练 autoencoder,S2包含所有 {0,1,2,3,4};S2 再做2等分,一个训练分类器,一个做测试,并未用到 MNIST 中的 test set。