HBase Architecture(译):下
原文: http://ofps.oreilly.com/titles/9781449396107/architecture.html
译者:phylips@bmy 2011-10-1
出处:http://duanple.blog.163.com/blog/static/709717672011925102028874/
1. Read Path
HBase中的每个column family可能有多个文件,文件中包含实际的cells或者是KeyValue实例。当memstore中积累的更新被flush到磁盘上时这些文件就会创建出来。负责compaction的后台线程会通过将小文件合并成更大的文件来将文件数控制在一定水平上。Major compaction最终会将所有的文件集合压缩成一个,之后随着flush的进行,小文件又会出现。
因为所有的存储文件都是不可变的,所以就没法直接将一个值从它们里面删除,也没法对某个值进行覆盖。而只能通过写入一个墓碑式的标记,来代表某个cell或者某几个cell或者是整行都被删除了。
假设今天你在给定的一行里写了一个列,之后你一直不断的添加数据,那么你可能会为该行写入另一个列。问题是,假设最初的列值已经被持久化到了磁盘中,而新写入的列还在memstore中,或者已经被flush到了磁盘,那该行到底算存放到哪呢?换句话说,当你对该行执行一个get命令时,系统怎么知道该返回什么内容?作为一个客户端,你可能希望返回所有的列—看起来它们好像就是一个实体一样。但是实际的数据是存储在独立的KeyValue实例中的,而且可能跨越任意数目的存储文件。
如果你删除了最初的那个列值,然后再执行get操作,你希望该值已经不存在了,虽然实际上它还存在于某处,但是墓碑式的标记表明你已经把它删除了。但是该标记很有可能与你要删除的值是分开存储的。关于该架构更细节的内容参见the section called “Seek vs. Transfer”。
该问题是通过使用QueryMatcher以及一个ColumnTracker解决的。在读取所有的存储文件以找到一个匹配的记录之前,可能会有一个快速的排除检查,可以使用时间戳或者Bloom filter来跳过那些肯定不包含该记录的存储文件。然后,对剩余的存储文件进行扫描以找到匹配该key的记录。
为何Gets即Scans
在HBase之前的版本中,Get方法的确是单独实现的。最近的版本进行了改变,目前它内部已经和Scan API使用相同的源代码。
你可能会很奇怪,按理来说一个简单的Get应该比Scan快的。把它们区分对待,更容易针对Get进行某些优化。实际上这是由HBase本身架构导致的,内部没有任何的索引文件来支持对于某个特定的行或列的直接访问。最小的访问单元就是HFile中的一个block,为了找到被请求的数据,RegionServer代码和它的底层Store实例必须load那些可能包含该数据的blocks然后进行扫描。实际上这就是Scan的操作过程。换句话说,Get本质上就是对单个行的Scan,就是一个从start row到start row+1的scan。
Scan是通过RegionScanner类实现的,它会每个Store实例(每个代表一个column family)执行StoreScanner检索,如果读操作没有包含某个column family,那么它的Store实例就会被略过。
StoreScanner会合并它所包含的存储文件和memstore。同时这也是根据Bloomfilter或者时间戳进行排除性检查的时候,然后你可以跳过那些不需要的存储文件。参见the section called “Key Design”了解排除性检查的细节,以及如何利用它。
同时也是由StoreScanner持有QueryMatcher(这里是ScanQueryMatcher类)。它会记录下那些包含在最终结果中的KeyValue。
RegionScanner内部会使用一个KeyValueHeap类来按照时间戳顺序安排所有的Store scanners。StoreScanner也会采用相同的方式来对存储文件进行排序。这就保证了用户可以按照正确的顺序进行KeyValue的读取(比如根据时间戳的降序)。
在store scanners被打开时,它们会将自己定位到请求的row key处。准备进行数据读取。
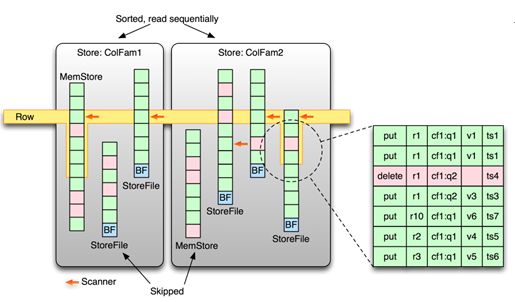
Figure 8.10. Rows are stored and scanned across different stores, on-disk or in-memory
|
对于一个get()调用,所有的服务器需要做的就是调用RegionScanner的next()。该调用内部会读取组成结果的所有内容。包括所有请求的版本,假设某列有三个版本,同时用户请求检索它们中所有的。这三个KeyValue可能分布在磁盘或内存中的存储文件。Next()调用会从所有的存储文件中读取直到读到下一行,或者直到读到足够的版本。
与此同时,它也会记录那些删除标记。当它扫描当前行的KeyValue时,可能会碰到这些删除标记,那些时间戳小于等于该删除标记的记录都会被认为是已经清除掉了。
图中展示了一个由一系列KeyValue组成的逻辑行,某些存储在相同的存储文件中,某些在其他文件上,包含了多个column family。由于时间戳或者Bloom filter的排除过程,某些存储文件和memstore可能会被跳过。最后一个存储文件中的删除标记可能会遮蔽掉所有的记录,但是它们仍然是同一行的一部分。这些scanners—实际上可以用一系列指向存储文件的箭头表示—要么指向文件中的第一个匹配点,要么是紧挨着所请求的key的那个点(如果没有直接匹配的点的话)。
在执行next调用时,只有那些具有匹配点的scanners才会被考虑。内部循环会从第一个存储文件到最后一个存储文件,按照时间地降序一个挨一个地读取其中的KeyValue,直到超出当前请求的key。
对于scan操作,则是通过在ResultScanner上不断的调用next(),直到碰到表的结束行或者为当前的batch读取了足够多的行时。
最终的结果是一个匹配了给定的get或者scan操作的KeyValue的列表。它会被发送给客户端,客户端就可以使用API函数来访问里面的列。
2. Region查找
为了让客户端能够找到持有特定的row key range的region server,HBase提供了两个特殊的元数据表:-ROOT-和.META.。
-ROOT-表用于保存.META.表的所有regions的信息。HBase认为只有一个root region,同时它永不会被split,这样就可以保证一个三层的类B+树查找模式:第一层是存储在ZooKeeper上的一个保存了root 表的region信息的节点,换句话说就是保存了root region的那个region server的名称。第二层需要到-ROOT-表中查找匹配的meta region,然后第三层就是到.META.表中检索用户表的region信息。
元数据表中的row key由每个region的表名,起始行,及一个ID(通常使用当前时间,单位是毫秒)。从HBase 0.90.0开始,这些key可能会有一个额外的与之关联的hash值。目前只是用于用户表中。
注:Bigtable论文指出,在.META.表的region大小限制在128MB的情况下,它可以寻址2^34个regions,如果按每个region 128MB大小算,就是2^61字节大小。因为region大小可以增加而不会影响到定位模式,因此根据需要这个值还可以增大。
尽管客户端会缓存region位置信息,但是客户端在首次查询时都需要发送请求来查找特定row key或者一个region也可能会被split,merge或者移动,这样cache可能会无效。客户端库采用一种递归的方式逐层向上地找到当前的信息。它会询问与给定的row key匹配的.META.表region所属的region server地址。如果信息是无效的,它就退回到上层询问root表对应的.META. region的位置。最后,如果也失败了,它就需要读取Zookeeper节点以找到root表region的位置。
最坏情况下,将会需要6次网络传输才能找到用户region,因为无效记录只有当查找失败时才能发现出来,当然系统假设这种情况并不经常发生。在缓冲为空的情况下,客户端需要三次网络传输来完成缓存更新。一种降低这种网络传输次数的方法是对位置信息进行预取,提前更新客户端缓存。具体细节见the section called “Miscellaneous Features”。
Figure 8.11. Starting with an empty cache, the client has to do three lookups.
|

一旦用户表region已知之后,客户端就可以直接访问而不需要进一步的查找。图中对查找进行了标号,同时假设缓存是空的。
2.1. Region生命周期
Region的状态会被master追踪,通过使用AssignmentManager类。它会记下region从offline状态开始的整个生命周期。表8.1列出了一个region的所有可能状态。
Table 8.1. Possible states of a region
State |
Description |
Offline |
The region is offline. |
Pending Open |
A request to open the region was sent to the server. |
Opening |
The server has started opening the region. |
Open |
The region is open and fully operational. |
Pending Close |
A request to close the region has been sent to the server. |
Closing |
The server is in the process of closing the region. |
Closed |
The region is closed. |
Splitting |
The server started splitting the region. |
Split |
The region has been split by the server. |
状态间的转换可能是由master引起,也可能是由持有它的那个region server引起。比如master可能将region分配给某个server,之后它会由该server打开。另一方面,region server可能会启动split过程,这会触发region打开和关闭事件。
由于这些事件本身的分布式属性,服务器使用ZooKeeper在一个专门的znode中记录各种状态。
3. ZooKeeper
从0.20.x开始,HBase使用ZooKeeper作为它的分布式协调服务。包括region servers的追踪,root region的位置及其他一些方面。0.90.x版引入了新的master实现,与ZooKeeper有了更紧密的集成。它使得HBase可以去除掉master和region servers之间发送的心跳信息。这些现在都通过ZooKeeper完成了,当其中的某一部分发生变化时就会进行通知,而之前是通过固定的周期性检查完成。
HBase会在它的根节点下创建一系列的znodes。根节点默认是”/hbase”,可以通过zookeeper.znode.parent进行配置。下面是所包含的znodes节点列表及其功用:
注:下面的例子使用了ZooKeeper命令行接口(简称CLI)来运行这些命令。可以通过如下命令启动CLI:
$ $ZK_HOME/bin/zkCli.sh -server <quorum-server>
/hbase/hbaseid
包含了集群ID,跟存储在HDFS上的
hbase.id
文件中的一致. 如下:
[zk: localhost(CONNECTED) 1] get /hbase/hbaseid
e627e130-0ae2-448d-8bb5-117a8af06e97
/hbase/master
包含了服务器名称, (具体参见the section called “Cluster Status Information” ). 如下:
[zk: localhost(CONNECTED) 2] get /hbase/master
foo.internal,60000,1309859972983
/hbase/replication
包含了replication的细节信息。相关细节参见 the section called “Internals”。
/hbase/root-region-server
包含了持有
-ROOT-
regions 的region server的服务器名称。在region查找过程中会用到它 (见 the section called “Region Lookups”). 如下:
[zk: localhost(CONNECTED) 3] get /hbase/root-region-server
rs1.internal,60000,1309859972983
/hbase/rs
作为所有region servers的根节点,会记录它们是何时启动。用来追踪服务器的失败。每个内部的znode节点是临时性的,以它所代表的region server的服务器名称为名。比如:
[zk: localhost(CONNECTED) 4] ls /hbase/rs
[rs1.internal,60000,1309859972983,rs2.internal,60000,1309859345233] /hbase/shutdown
该节点用于追踪集群状态。包含集群启动时间,当集群关闭时其内容为空。比如:
[zk: localhost(CONNECTED) 5] get /hbase/shutdown
Tue Jul 05 11:59:33 CEST 2011 /hbase/splitlog
用于所有log splitting相关协调的parent znode, 细节详见 the section called “Log Splitting” 。比如:
[zk: localhost(CONNECTED) 6] ls /hbase/splitlog
[hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Ffoo.internal%2C60020%2C \
1309850971208%2Ffoo.internal%252C60020%252C1309850971208.1309851636647,
hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Ffoo.internal%2C60020%2C \
1309850971208%2Ffoo.internal%252C60020%252C1309850971208.1309851641956,
...
hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Ffoo.internal%2C60020%2C \
1309850971208%2Ffoo.internal%252C60020%252C1309850971208.1309851784396]
[zk: localhost(CONNECTED) 7] get /hbase/splitlog/ \
\hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Fmemcache1.internal%2C \ 60020%2C1309850971208%2Fmemcache1.internal%252C60020%252C1309850971208. \ 1309851784396
unassigned foo.internal,60000,1309851879862
[zk: localhost(CONNECTED) 8] get /hbase/splitlog/ \ \hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Fmemcache1.internal%2C \ 60020%2C1309850971208%2Fmemcache1.internal%252C60020%252C1309850971208. \
1309851784396
owned foo.internal,60000,1309851879862
[zk: localhost(CONNECTED) 9] ls /hbase/splitlog [RESCAN0000293834, hdfs%3A%2F%2Flocalhost%2Fhbase%2F.logs%2Fmemcache1. \
internal%2C60020%2C1309850971208%2Fmemcache1.internal%252C \
60020%252C1309850971208.1309851681118, RESCAN0000293827, RESCAN0000293828, \
RESCAN0000293829, RESCAN0000293838, RESCAN0000293837]
这些例子列出了很多东西:你可以看到一个未被分配的log是如何被split的,之后又如何被一个region server所拥有。"RESCAN"节点表示那些workers,比如万一log split失败后可能被用于进一步的工作的region server。
/hbase/table
当一个表被禁用时,它会被添加到该节点下. 表名就是新创建的znode的名称,内容就是"DISABLED"。比如:
[zk: localhost(CONNECTED) 10] ls /hbase/table
[testtable]
[zk: localhost(CONNECTED) 11] get /hbase/table/testtable
DISABLED /hbase/unassigned
该znode是由 AssignmentManager 用来追踪整个集群的region状态的。它包含了那些未被打开或者处于过渡状态的regions对应的znodes,zodes的名称就是该region的hash。比如:
[zk: localhost(CONNECTED) 11] ls /hbase/unassigned
[8438203023b8cbba347eb6fc118312a7]
4. Replication
HBase replication是在不同的HBase部署之间拷贝数据的一种方式。它可以作为一种灾难恢复解决方案,也可以用于提供HBase层的更高的可用性。同时它也能提供一些更实用的东西:比如,可以作为从面向web的集群中拷贝最新的更新内容到MapReduce集群的简单方式,然后利用MapReduce集群对新老数据进行处理再自动地返回结果。
HBase replication采用的基本架构模式是:master-push;因为每个region server都有自己的write-ahead-log(即WAL或HLog),这样就很容易记录下从上次复制之后又发生了什么,非常类似于其他一些著名的解决方案,就像MySQL 的主从复制就只用了一个binary log来进行追踪。一个master集群可以向任意数目的slave集群进行复制,同时每个region server会参与复制它本身所对应的一系列的修改。
Replication是异步进行的,这意味着参与的集群可能在地理位置上相隔甚远,它们之间的连接可以在某段时间内是断开的,插入到master集群中的那些行,在同一时间在slave集群上不一定是可用的(最终一致性)。
在该设计中所采用的replication格式在原理上类似于MySQL的基于状态的replication。在这里,不是SQL语句,而是整个的WALEdits(由来自客户端的put和delete操作的多个cell inserts组成)会被复制以维持原子性。
每个region server的HLogs是HBase replication的基础,同时只要这些logs需要复制到其他的slave集群上,它们就需要保存在HDFS上。每个RS会从它们需要复制的最老的log开始读取,同时为简化故障恢复会将当前读取位置保存到ZooKeeper上。对于不同的slave集群来说,该位置可能是不同的。参与replication各集群大小可能不是对称的,同时master集群会通过随机化来尽量保证在slave集群上的replication工作流的平衡。
Figure 8.12. Overview on the replication architecture
|

4.1. Life of a Log Edit
下面的几节里会描述下来自客户端的一个edit从与master集群通信开始到到达另一个slave集群的整个生命历程。
4.1.1. 正常处理流程
客户端会使用HBase API将Put,Delete和Increment发送给region server。Key values会被region server转换为一个WALEdit对象。该edit对象会被append到当前的WAL上,同时之后会被apply到它的MemStore中。
通过一个独立的线程,将该edit对象从log中读出然后只保留那些需要复制的KeyValues(也就是说只保留那些在family schema中只属于GLOBAL作用域的family的成员,同时是非元数据也就是非.META和-ROOT-)。当buffer被填满或者读取者读到文件末尾后,该buffer会被随机发送到slave集群上的某个region server上。region server顺序地接受读到的这些edits,同时将它们按照table放到不同的buffers中。一旦所有的edits读取完毕,所有的buffer就会通过正常的HBase客户端进行flush。
回头再看master集群的region server,当前复制到的WAL偏移位置会注册到ZooKeeper上。
4.1.2. Non-responding Slave Clusters
Edit会以同样的方式进行插入。在独立的线程中,region server像正常处理过程那样进行读取,过滤以及对log edits进行缓存。假设现在所联系的那个slave集群的region server不再响应RPC了,这样master集群的region server会进行休眠然后等待一个配置好的时间段后再进行重试。如果slave集群的region server仍然没有响应,master集群的region server就会重新选择一个要复制到的region server子集,然后会重新尝试发送缓存的那些edits。
与此同时,WALs将会进行切换同时会被存储在ZooKeeper的一个队列中。那些被所属的region server归档(归档过程基本上就是把一个日志从它所属的region server的目录下移到一个中央的logs归档目录下)了的日志会更新它们在复制线程的内存队列中的路径信息。
当slave集群最终可用后,处理方式就又跟正常处理流程一致了。Master集群的region server就又开始进行之前积压的日志的复制了。
4.2. Internals
本节会深入描述下replication的内部操作机制。
4.2.1. 选择复制到的目标Region Servers
当一个master集群的region server开始作为某个slave集群的复制源之后,它首先会通过给定的集群key联系slave集群的ZooKeeper。
该key由如下部分组成:
hbase.zookeeper.quorum
zookeeper.znode.parent
hbase.zookeeper.property.clientPort。
之后,它会扫描/hbase/rs目录以找到所有可用的sinks(即那些可用接收用于复制的edits数据流的region servers)同时根据配置的比率(默认是10%)来选出它们中的一个子集。比如如果slave集群有150台机器,那么将会有15台选定为master集群的region server将要发送的edits的接受者。因为复制过程中,master的所有region server都会进行,这样这些slave集群的region server的负载就可能会很高,同时该方法适用于各种大小的集群。比如,一个具有10台机器的master集群向一个具有10%比率的5台集群的slave集群进行复制。意味着master集群的region servers每次都会随机选择一台机器,这样slave集群的重叠和总的使用率还是很高的。
4.2.2. 日志追踪
每个master集群的region server在replication znodes体系中都有自己的节点。同时节点下针对每个集群节点还会有一个znode(如果有5个slave集群,就会有5个znode创建出来),每个znode下又包含一个待处理的HLogs队列。这些队列是用来追踪由该region server创建的HLogs的,这些队列的大小可能有所不同。比如,如果某个slave集群某段时间不可用,那么这段时间的HLogs就不能被删除,因此它们就得呆在队列里(而其他的可能已经处理过了)。具体例子可以参考:the section called “Region Server Failover”。
当一个source被实例化时,它会包含region server当前正在写入的HLog。在log切换时,新的文件在可用之前就会被添加到每个slave集群的znode的队列中。这可以让所有的sources在该HLog可以append edits之前就能够知道一个新log已经存在了,但是该操作的开销目前是很昂贵的。当replication线程无法从文件中读出更多的记录之后(因为它已经读到了最后一个block),就会将它从队列中删除,此时要求队列中的还有其他文件存在{!还有其他文件存在就意味着这个文件是一个已经写完的日志文件,而不是正在写入的那个}。这就意味着如果一个source已是最新状态,同时复制进程已经到了region server正在写入的那个log,那么即使读到了当前文件的”end”部分,也不能将它从队列中删除{!如果该文件正在被写入,那么即使读到了末尾,也不能认为它已经结束}。
当一个log被归档后(因为它不再被使用或者是因为插入速度超过了region flushing的速度导致当前log文件数超过了hbase.regionserver.maxlogs的限制),它会通知source线程该log的路径已经发生改变。如果某个source已经处理完该log,会忽略该消息。如果它还在队列中,该路径会更新到相应的内存中。如果该log目前正在被复制,该变更会自动完成,读取者不需要重新打开该被移动的文件。因为文件的移动只是一个NameNode操作,如果读取者当前正在读取该log文件,它不会产生任何异常。
4.2.3. 读,过滤及发送Edits
默认情况下,一个source会尽量地读取日志文件然后将日志记录尽快地发送给一个sink。但是首先它需要对log记录进行过滤;只有那些具有GLOBAL作用域同时不属于元数据表的KeyValues才能保留下来。第二个限制是,附加在每个slave集群上所能复制的edits列表的大小限制,默认是64MB。这意味着一个具有三个slave集群的master集群的region server最多只能使用192MB来存储被复制的数据。
一旦缓存的edits大小达到上限或者读取者读到了log文件末尾,source线程将会停止读取然后随机选择一个sink进行复制。它会对选定的集群直接产生一个RPC调用,然后等待该方法返回。如果成功返回,source会判断当前的文件是否已经读完或者还是继续从里面读。如果是前者,它会将它从znode的队列中删除。如果是后者,它会在该log的znode中注册一个新的offset。如果PRC抛出了异常,该source在寻找另一个sink之前会重试十次。
4.2.4. 日志清理
如果replication没有开启,master的logs清理线程将会使用用户配置的TTL进行旧logs的删除。当使用replication时,这样是无法工作的,因为被归档的log虽然超过了它们自己的TTL但是仍可能在队列中。因此,需要修改默认行为,在日志超出它的TTL时,清理线程还要查看每个队列看能否找到该log,如果找不到就可以将该log删除。查找过程中它会缓存它找到的那些log,在下次log查找时,它会首先查看缓存。
4.2.5. Region Server故障恢复
只要region servers没有出错,ZooKeeper中的日志记录就不需要添加任何值。不幸的是,它们通常都会出错,这样我们就可以借助ZooKeeper的高可用性和它的语义来帮助我们管理队列的传输。
master集群的所有region servers相互之间都有一个观察者,当其中一个死掉时,其他的都能得到通知。如果某个死掉后,它们就会通过在死掉的region server的znode(该znode也包含它的队列)内创建一个称为lock的znode来进行竞争性选举。最终成功创建了该znode的region server会将所有的队列传输到它自己的znode下(逐个传输因为ZooKeeper并不支持rename操作)当传输完成后就会删掉老的那些。恢复后的队列的znodes将会在死掉的服务器的名称后加上slave集群的id来进行命名。
完成之后,master集群的region server会对每个拷贝出的队列创建一个新的source线程。它们中的每一个都会遵守read/filter/ship模式。主要的区别是这些队列不会再有新数据因为它们不再属于它们的新region server,同时意味着当读取者到达最后一个日志的末尾时,队列对应的znode就可以被删除了,同时master集群的region server将会关闭那个replication source。
比如,考虑一个具有3个region servers的master集群,该集群会向一个id为2的单个slave集群进行复制。下面的层次结构代表了znodes在某个时间点上的分布。我们可以看到该region servers的znodes都包含一个具有一个队列的peers znode。这些队列的znodes的在HDFS上的实际文件名称具有如下形式” address,port.timestamp”。
/hbase/replication/rs/
1.1.1.1,60020,123456780/
peers/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
peers/
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020, 123456630/
peers/
2/
1.1.1.3,60020.1280 (Contains a position)
现在我们假设1.1.1.2丢失了它的ZK会话,幸存者将会竞争以创建一个lock,最后1.1.1.3获得了该锁。然后它开始将所有队列传输到它本地的peers znode,同时在原有的名称上填上死掉的服务器的名称。在1.1.1.3清理老的znodes之前,节点分布如下:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
peers/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
lock
peers/
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020,123456630/
peers/
2/
1.1.1.3,60020.1280 (Contains a position)
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
一段时间后,但在1.1.1.3结束来自1.1.1.2的最后一个HLog的复制之前,我们假设它也死掉了(而且某些之前创建的新logs还在正常队列中)。最后一个region server会尝试锁住1.1.1.3的znode然后开始传输所有的队列。新的节点分布如下:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
peers/
2/
1.1.1.1,60020.1378 (Contains a position)
2-1.1.1.3,60020,123456630/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790-1.1.1.3,60020,123456630/
1.1.1.2,60020.1312 (Contains a position)
1.1.1.3,60020,123456630/
lock
peers/
2/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1312 (Contains a position)
Replication 目前还是一个处于实验阶段的feature。在将它应用到你的使用场景中时需要进行仔细地评估。
[83] See "B+ trees" on Wikipedia
[84] See LSM-Tree, O'Neil et al., 1996
[85] From "Open Source Search" by Doug Cutting, Dec. 05, 2005.
[86] See the JIRA issue HADOOP-3315 for details.
[87] For the term itself please read Write-Ahead Logging on Wikipedia.
[88] Subsequently they are referred to interchangeably as root table and meta table respectively, since for example
"-ROOT-"
is how the table is actually named in HBase and calling it root table is stating its purpose.
[89] See the online manual for details.