生产环境的hadoop搭建
Hadoop生产环境搭建,这个搭建还是跟咱们平时练习的完全分布式搭建还是有区别的。我这篇文章的思路是这样的:
1:先构建Hadoop集权从软件,硬件选择上说起
2:先搭建平时练习搭建的分布式的集群
3:演示动态的增加,删除节点
4:然后把namenode,secondarynamenode和jobstaracker单独运行一个主机(这个是真实的大的集群的需求)
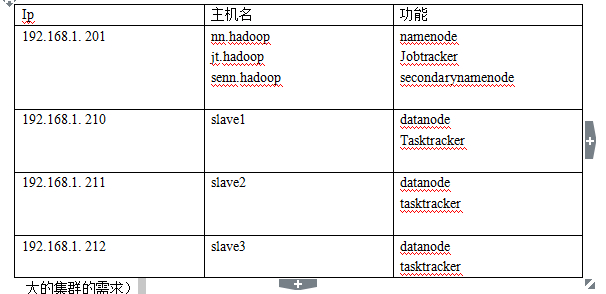
一:软件,硬件的选择
硬件选择的原则
1:尽可能使用相同类型的硬件来运行datanode,保持集群主机性能和存储容量一致
2:对于datanode节点,要求有比较大的存储空间
3:对于namenode,jobtracker节点,要求性能好,内存大,并且硬件的稳定性要高,尽量使用nfs来保
持namenode数据,方便恢复
4:如果我们的集群大的话,我们还是喜欢将namenode,secondary和 jobtracker放到不同的主机上,而且我们的namenode放的主机上最好用64位的,避免32位系统Java堆内存3Gb的限制。
软件的选择
1:Enterprise Redhat Linux
2:Oracle JRE 1.6以上
3:保持所有节点操作系统和软件版本一致
4:Hadoop 1.x 稳定版本
二:练习时分布式集群的搭建
1:先从一台主机上搭建Hadoop伪分布模式
A:选择192.168.1. 201机,创建一个用户组叫hadoop,添加一个用户叫hadoop
B:然后用户修改主机名,还有hosts文件要与上面的网络规划对应起来(Linux,windows)
C:然后在用户的宿主名录下编辑.bashrc文件,配置好jdk的路径,如果主机名不能完全显示的话还要配置.bashrc来让主机名完全显示(PS1=’ [\u@\H] \S’,单独写一行就可以了)。
D:做免密码登陆操作(hadoop用户自己到hadoop用户自己的免密码登陆,非root用户,在做免密码登陆的时候需要对免密码登陆的文件权限进行修改)
E:我们当前的目录是/hadoop/home
然后我们把Hadoop的tar包添加进来,开始解压。我们把解压生成的目录里面的conf目录给复制出来(/hadoop/home)原因:在生成环境中不要包含特定版本的内容,然后我们给bin目录做个软链接,也在当前目录。
然后我们需要更给.bashrc文件了,
export HADOOP_CONF_DIR=/home/hadoop/conf(单独写一行就行)
export HADOOP_HAOME=/home/hadoop/bin添加到path里面去。
每次修改.bashrc都要运行一次.bashrc
F:配置conf.site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nn.hadoop:9000</value>
<description>change your own hostname</description>
</property>
</configuration>
然后配置hdfs.site.xml
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/data/namenode</value>
<description>change your own hostname</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data/datanode</value>
<description>change your own hostname</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
然后配置mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>jb.hadoop:9001</value>
<description>change your own hostname</description>
</property>
然后修改
hadoop-env.xml
把日志目录改到我们想要看到的地方。一般我们是把弄到/haoop/home下
然后修改masters
添加:nn.hadoop
然后修改slaves
添加:nn.hadoop
然后格式化namenode后启动集群,如果没有什么错,那么就说明,伪分布模式的集群已经搭建好了
2:增加slave1和slave2,把伪分布,给成完全分布模式。
1:把刚刚弄好的系统复制两份,分别给系统修改主机名,IP
2:做免密码登陆,进入到nn.hadoop的hadoop用户下:
scp ~/.ssh/id_dsa.pub hadoop@slave1:.ssh/authorized_keys
3:masters文件不需要改变,slaves文件天剑slave1和slave2
4:启动集群,我们发生会有错误,这是因为刚刚是复制了两个一模一样的datanode,我们知道datanode有个ID是要不一样的,分别登录到两台主机,把data目录下的datanode下的东西删除了,重新启动就可以了,不需要格式化namenode。
5:重启,就可以成功了
三:动态添加,删除节点
1:添加节点
1:复制上面的一个系统,然后修改iP,修改主机名(slave3)
2:进入到namenode系统,做到slave3的免密码登陆
3:修改slaves的文件,添加slave3
4:将步骤3的修改同步的salve1,salve2,salve3
rsync -r ~/conf hadoop@slave1:./
rsync -r ~/conf hadoop@slave2 :./
rsync -r ~/conf hadoop@slave3:./
5:接着运行
hadoop dfsadmin -refreshNodes
6:进入到slave3分布启动,tasktracker,datanode
hadoop-daemon.sh start datanode手动的把datanode启动起来
hadoop-daemon.sh start tasktracker
7:这个过程是不需要重启hadoop集群的。做上面的操作就OK了。
2:删除节点
1:到现在为止,我们完成了一开始看到的网络布局,现在接着做的是删除salve3节点,进入nn.hadoop修改hdfs-site.xml文件
添加配置:
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/conf/hosts.exclude</vlaue>
</property>
2:重启Hadoop集群
3:在conf目录里面编写hosts.exclude这个文件,这个文件里面写你要删除的节点的名字。
4:hadoop dfsadmin -refreshNodes
5:如果被我们删除的这个节点上有很多数据,那么我们先在web的管理界面上观察一下,等数据移动完了以后我们才能做其它操作。(被删除的这个节点一开始会在Decommissioning里等数据移动完以后就会被归类到到deadNodes里)
6:上面步骤完成后进入到slave3运行 :
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop tasktracker
7:OK了
四:让jobtracker和secondelyname单独运行
1:让jobtracker单独运行
1:copy一个主机,修改IP,主机名,还要修改hosts文件里面jb.hadoop对应的IP为
192.168.1. 202
2:进入到nn.hadoop,也是要修改hosts文件,然后同步到其它的主机
rsync /etc/hosts root@slave1:/etc/hosts
rsync /etc/hosts root@slave2 :/etc/hosts
3:这是我手动的把jobtracker移动出去了,是需要重启hadoop集群的,这是不好的,所以一开始搭建的时候我们就应该规划好,有必要就让jobtracker,secondarynamenode单独跑一个主机,运行hadoop-all.sh
4:进入到jb.hadoop
hadoop-daemon.sh start jobtracker
5:OK 了
2:让secondarynamenode单独运行
1:copy一个主机,修改IP,主机名,还要修改hosts文件里面seen.hadoop对应的IP为
192.168.1. 203
2:进入到nn.hadoop,也是要修改hosts文件,然后同步到其它的主机
3:修改一下hdfs-site.xml文件,在后面添加两个配置
<property>
<name>dfs.http.address</name>
<value>nn.hadoop:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>senn.hadoop:50090</value>
</property>
配置好以后做一个同步。
4:启动start-all.sh,但是这样发现其实我们还是没有启动secondarynamenode
所以我们登陆到seen.hadoop上手动 的把启动起来。
5:大功告成!