snort 快速匹配引擎的构建
概述
snort作为一个网络入侵检测工具,与同类工具拥有相似的处理流程,如下所示:
基本数据初始化
回调函数注册
读取规则建立临时结构
使用临时结构建立最终便于匹配的结构,该过程也可称为编译过程。
进入循环获取报文进行处理
而报文的处理又经历如下流程
拆包
预处理
匹配
动作
前面文章已经分析了规则的读取:
http://my.oschina.net/u/572632/blog/290351
这里就将继续分析如何建立匹配结构,建立匹配结构的过程又可称为编译过程,目地是将读取规则后建立的便于收集数据的结构转换为专门用于匹配的结构。
代码分析
构建临时结构
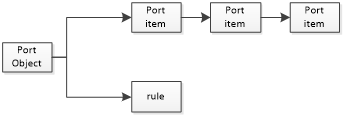
如下图所示,当端口初次解析的过程中snort使用如下的方式存放解析出的端口对象。
按照端口所属规则的协议类型将其分为tcp, udp等几类
每一类协议包含anyany_object, src_table, dst_table
如果这条规则的源和目地端口都为any则直接将该规则的规则索引加入anyany_object持有的规则链表中。
如果该规则的源端口非any,则将该规则的源端口对象入src_table中,并将该规则对应的索引加入源端口对象持有的规则链中。如果该规则的数据流是双向的则还需要将源端口对象加入dst_table中。
如果该规则的目地端口非any,则将该规则的目地端口对象入dst_table中,并将该规则对应的索引加入目地端口对象持有的规则链中。如果该规则的数据流是双向的则还需要将源端口对象加入dst_table中。

构建快速匹配结构
存在必有其理由,代码也一样,作者的处理必然有其原因,因此这里先分析下目前的状况。
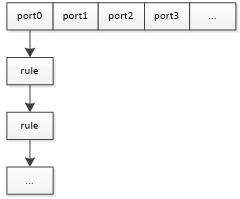
现在我们的anyany_object表现的很良好,但在src_table或者dst_table中会有多个port_object,当读取规则完成后在src_table或dst_table中的portObject目前如下图。这会带来下面几个问题。
port item在前面的文章做过分析,他可能是一个端口,也可能是端口范围,甚至可能是其包含的端口取反,更糟糕的是port Object是他持有的端口条目综合得出的。
即使我们为port object处理了port item集合后,在port object之间也可能出现重复的问题,极端情况可能6000个端口指向同一个port object而我们却保留了6000个副本,这是相当糟糕的。
因此在这里的匹配结构我们希望是下面这样的,每个端口下面是匹配上该端口的规则集合。
所以这里的代码所需的工作就是从上面的结构转换为下面的结构。
实际构建的快速匹配结构和上面的类似,快速匹配主要是构建了两点
端口,即上面所述的端口覆盖范围交错等问题
模式匹配,主要是针对uri, url等较长字串的模式匹配,需要注意的是这里匹配的具体方式是从多个方案中选择的,选择哪个要看具体配置
下面结合图示对其构建的结构具体的分析下。
整体结构是呈现一个树状,即在每一层针对某一特性将所有的被匹配结构进行分类,不断的重复这种方案所构成的树状结构再匹配时就能通过路径选择较少不必要的数据扫描。
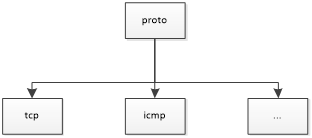
最顶层是使用协议区分,如下:
每一个PORT_RULE_MAP代表一种协议
/* The port-rule-maps map the src-dst ports to rules for * udp and tcp, for Ip we map the dst port as the protocol, * and for Icmp we map the dst port to the Icmp type. This * allows us to use the decode packet information to in O(1) * select a group of rules to apply to the packet. These * rules may have uricontent, content, or they may be no content * rules, or any combination. We process the uricontent 1st, * then the content, and then the no content rules for udp/tcp * and icmp, than we process the ip rules. */ PORT_RULE_MAP *prmIpRTNX; PORT_RULE_MAP *prmTcpRTNX; PORT_RULE_MAP *prmUdpRTNX; PORT_RULE_MAP *prmIcmpRTNX;
接下来是每个协议集合,即PORT_RULE_MAP中主要包含什么?
如下所示,PORT_RULE_MAP中主要是存放PORT_GROUP结构,每个端口都存放一个该结构,即
prmSrcPort 和prmDstPort数组中下标代表端口号,而其中存放的是规则集合。
需要注意的是any group 图示和代码不一致,这是因为any 的规则集合被放入了每一个端口,因为any代表全部端口匹配。
typedef struct {
int prmNumDstRules;
int prmNumSrcRules;
int prmNumGenericRules;
int prmNumDstGroups;
int prmNumSrcGroups;
PORT_GROUP *prmSrcPort[MAX_PORTS];
PORT_GROUP *prmDstPort[MAX_PORTS];
/* char prmConflicts[MAX_PORTS]; */
PORT_GROUP *prmGeneric;
} PORT_RULE_MAP ;

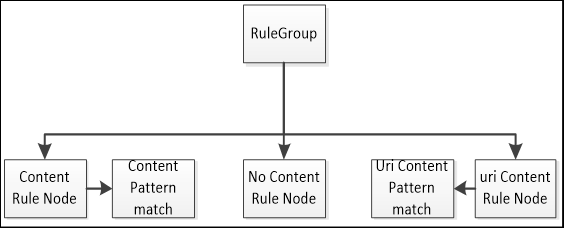
最后是PORT_GROUP结构分析了,PORT_GROUP结构中主要是负责模式匹配,因此对于非HTTP的协议PORT_GROUP中的内容就不太重要了,还是结合代码说明.
如下,将规则集合再次分为三种, content, no-content 和 uri-content. 即content匹配,不含content, uri匹配。
规则集合有了,图示中对应的模式匹配结构呢?
模式匹配结构再pgPms, 还需注意上面说明, MPSE如果对模式匹配感兴趣呀可以重点阅读该部分代码。
typedef struct {
/* Content List */
RULE_NODE *pgHead, *pgTail, *pgCur;
int pgContentCount;
/* No-Content List */
RULE_NODE *pgHeadNC, *pgTailNC, *pgCurNC;
int pgNoContentCount;
/* Uri-Content List */
RULE_NODE *pgUriHead, *pgUriTail, *pgUriCur;
int pgUriContentCount;
/* Pattern Matching data structures (MPSE) */
void *pgPms[PM_TYPE__MAX];
/* detection option tree */
void *pgNonContentTree;
int avgLen;
int minLen;
int maxLen;
int c1,c2,c3,c4,c5;
/*
* Not rule list for this group
*/
NOT_RULE_NODE *pgNotRuleList;
/*
** Count of rule_node's in this group/list
*/
int pgCount;
int pgNQEvents;
int pgQEvents;
}PORT_GROUP;
总结
snort快速匹配的核心思想是使用规则集合中的某个特征不断将规则拆分为更小的子类,从而构建出树状结构,减少匹配路径。
对于像URI这样的字串匹配做专门的模式串构建,snort的匹配结构构建方式是多选一的,超酷.