Es中使用sort,aggs的时候,出现fielddata超过heap问题
It is best to configure the circuit breaker with a relatively conservative value. Remember that fielddata needs to share the heap with the request circuit breaker, the indexing memory buffer, the filter cache, Lucene data structures for open indices, and various other transient data structures. For this reason, it defaults to a fairly conservative 60%. Overly optimistic settings can cause potential OOM exceptions, which will take down an entire node.
On the other hand, an overly conservative value will simply return a query exception that can be handled by your application. An exception is better than a crash. These exceptions should also encourage you to reassess your query: why does a single query need more than 60% of the heap?
这意思,就是默认可以,如果出现问题,我们想到的不应该是调整这个值,而是检查下我们的查询或者其他设置,为何导致这么大的问题。
https://www.elastic.co/guide/en/elasticsearch/guide/current/_limiting_memory_usage.html#circuit-breaker
In-memory模式中,fielddata受到heap内存大小限制,虽然这个问题可以通过集群的横向扩容解决——可需要经常增加节点——而且即使加了,你还是会发现在其他一些资源利用不充分的节点上,在排序和聚合查询的时候仍然会消耗你大量的heap空间。
fielddata字段数据默认下,会频繁的在内存当中加载。但这不是唯一的方法,在索引数据时,fielddata字段数据还可以被写在磁盘中,这种方式可以提供和加载到内存中的一样的功能,而不会占用heap的内存空间。
Docvalues是在1.0.0之后加入到elasticsearch中的。通过基准测试与性能分析,各类的瓶颈——无论是elasticsearch还是lucene,都已经被发现并且已经被移除了。但是直到现在还是远远慢于字段数据放内存的in-memory方式。
1、存放在磁盘代替存放内存,可以允许你的集群负载大量fielddata字段数据而不会超量使用内存。这样,你的heap space就可以设置小一些了,对垃圾回收的速度有所帮助,理所当然的,节点也会更稳定些。
2、DocValues是索引时建立的,而不是搜索的时候。当通过非反向的反向索引搜索时候,in-memort方式,内存中的字段数据必须被频繁的读写,而doc vales 是预先建立的,并能更快的初始化。
像trade-off这种索引量大的搜索,访问fielddata会比较缓慢,设置docvalues会有显著的效果,在大量请求的时候,你甚至不会注意到你的搜索会变慢。结合更快的垃圾回收机制和初始化时间,你会留意到搜索性能会得到有效提升。
文件系统的缓存空间越多,docvalue的性能会越好。如果文件都是docvalues并且都位于文件系统的缓存中,那么访问这些文件的速度几乎与访问内存媲美的。而文件系统缓存由内核控制而非JVM。
启动DocValues
numeric, date, Boolean, binary, and geo-point这些字段以及not_analyzed的字符串可以设置Docvalues属性。一般不处理analyze的字符串字段。Docvalues在mapping重的每个字段属性中定义,这样对于不同的字段,可以结合in-memory与docvalues使用。
PUT /music/_mapping/song
{
“properties” : {
“tag”: {
“type”: “string”,
“index” : “not_analyzed”,
“doc_values”: true
}
}
}
设置了docvalues之后,字段创建时,就是用磁盘存储fielddata而不是内存存储fielddata了。
就这样!不需要再配置其他东西,查询,聚合,排序,以及一般的功能脚本;他们现在都会用到docvalues了。
你可以随便的使用docvalues这参数。用得越多,你使用的heap内存空间就可以越少。在不久的将来,docvalues应该会变成默认的参数。
原文来自:http://www.elastic.co/guide/en/elasticsearch/guide/current/doc-values.html#_enabling_doc_values
PUT /music/_mapping/song { "properties" : { "tag": { "type": "string", "index" : "not_analyzed", "doc_values": true} } }
| |
Setting doc_values to true at field creation time is all that is required to use disk-based fielddata instead of in-memory fielddata |
===================================================
1. 产生Data too large异常
今早运行查询时,ES返回了如下报错:
{
"error": "... CircuitBreakingException[[FIELDDATA] Data too large, data for [proccessDate] would be larger than limit of [10307921510/9.5gb]]; }]",
"status": 500 }
再尝试其他查询也是如此。经排查,原来是ES默认的缓存设置让缓存区只进不出引起的,具体分析一下。
2. ES缓存区概述
首先简单描述一下ES的缓存机制。ES在查询时,会将索引数据缓存在内存(JVM)中:
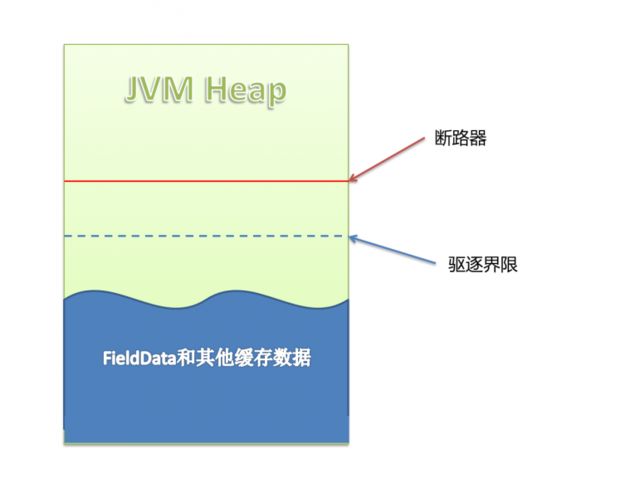
上图是ES的JVM Heap中的状况,可以看到有两条界限:驱逐线 和 断路器。当缓存数据到达驱逐线时,会自动驱逐掉部分数据,把缓存保持在安全的范围内。当用户准备执行某个查询操作时,断路器就起作用了,缓存数据+当前查询需要缓存的数据量到达断路器限制时,会返回Data too large错误,阻止用户进行这个查询操作。ES把缓存数据分成两类,FieldData和其他数据,我们接下来详细看FieldData,它是造成我们这次异常的“元凶”。
3. FieldData
ES配置中提到的FieldData指的是字段数据。当排序(sort),统计(aggs)时,ES把涉及到的字段数据全部读取到内存(JVM Heap)中进行操作。相当于进行了数据缓存,提升查询效率。
3.1 监控FieldData
仔细监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。
Fielddata缓存使用可以通过下面的方式来监控:
对于单个索引使用 {ref}indices-stats.html[indices-stats API]:
GET /_stats/fielddata?fields=*
对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]:
GET /_nodes/stats/indices/fielddata?fields=*
或者甚至单个节点单个索引
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
通过设置 ?fields=* 内存使用按照每个字段分解了.
在产生Data too large异常时,对集群FieldData监控的返回结果如下:

可以看到memory_size_in_bytes用到了整个JVM内存的60%(可用上限),而evictions(驱逐)为0。且经过一段时间观察,字段所占内存大小都没有变化。由此推断,当下的缓存处于无法有效驱逐的状态。
3.2 Cache配置
关于FieldData的配置在elasticsearch.yml中,也可以通过调用setting接口来修改。API文档里的介绍如下:
| Setting | Description |
|---|---|
| indices.fielddata.cache.size | The max size of the field data cache, eg 30% of node heap space, or an absolute value, eg 12GB. Defaults to unbounded. |
| indices.fielddata.cache.expire | [experimental] This functionality is experimental and may be changed or removed completely in a future release. A time based setting that expires field data after a certain time of inactivity. Defaults to -1. For example, can be set to 5m for a 5 minute expiry. |
简而言之:
indices.fielddata.cache.size 配置fieldData的Cache大小,可以配百分比也可以配一个准确的数值。cache到达约定的内存大小时会自动清理,驱逐一部分FieldData数据以便容纳新数据。默认值为unbounded无限。
indices.fielddata.cache.expire用于约定多久没有访问到的数据会被驱逐,默认值为-1,即无限。expire配置不推荐使用,按时间驱逐数据会大量消耗性能。而且这个设置在不久之后的版本中将会废弃。
看来,Data too large异常就是由于fielddata.cache的默认值为unbounded导致的了。
3.3 FieldData格式
除了缓存取大小之外,我们还可以控制字段数据缓存到内存中的格式。
在mapping中,我们可以这样设置:
{
"tag": {
"type": "string",
"fielddata": { "format": "fst" } } }
对于String类型,format有以下几种:
paged_bytes (默认)
使用大量的内存来存储这个字段的terms和索引。
fst
用`FST`的形式来存储terms。这在terms有较多共同前缀的情况下可以节约使用的内存,但访问速度上比paged_bytes 要慢。
doc_values
fieldData始终存放在disk中,不加载进内存。访问速度最慢且只有在index:no/not_analyzed的情况适用。
对于数字和地理数据也有可选的format,但相对String更为简单,具体可在api中查看。
从上面我们可以得知一个信息:我们除了配置缓存区大小以外,还可以对不是特别重要却量很大的String类型字段选择使用fst缓存类型来压缩大小。
4. 断路器
fieldData的缓存配置中,有一个点会引起我们的疑问:fielddata的大小是在数据被加载之后才校验的。假如下一个查询准备加载进来的fieldData让缓存区超过可用堆大小会发生什么?很遗憾的是,它将产生一个OOM异常。
断路器就是用来控制cache加载的,它预估当前查询申请使用内存的量,并加以限制。断路器的配置如下:
indices.breaker.fielddata.limit
这个 fielddata 断路器限制fielddata的大小,默认情况下为堆大小的60%。
indices.breaker.request.limit
这个 request 断路器估算完成查询的其他部分要求的结构的大小, 默认情况下限制它们到堆大小的40%。
indices.breaker.total.limit
这个 total 断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个部分使用的总内存不超过堆大小的70%。
断路器限制可以通过文件 config/elasticsearch.yml 指定,也可以在集群上动态更新:
PUT /_cluster/settings { "persistent" : { "indices.breaker.fielddata.limit" : 40% (1) } }
当缓存区大小到达断路器所配置的大小时会发生什么事呢?答案是:会返回开头我们说的Data too large异常。这个设定是希望引起用户对ES服务的反思,我们的配置有问题吗?是不是查询语句的形式不对,一条查询语句需要使用这么多缓存吗?
5. 总结
-
这次Data too large异常是ES默认配置的一个坑,我们没有配置indices.fielddata.cache.size,它就不回收缓存了。缓存到达限制大小,无法往里插入数据。个人感觉这个默认配置不友好,不知ES是否在未来版本有所改进。 - 当前fieldData缓存区大小 < indices.fielddata.cache.size
当前fieldData缓存区大小+下一个查询加载进来的fieldData < indices.breaker.fielddata.limit
fielddata.limit的配置需要比fielddata.cache.size稍大。而fieldData缓存到达fielddata.cache.size的时候就会启动自动清理机制。expire配置不建议使用。 -
indices.breaker.request.limit限制查询的其他部分需要用的内存大小。indices.breaker.total.limit限制总(fieldData+其他部分)大小。 -
创建mapping时,可以设置fieldData format控制缓存数据格式。