SVD 笔记
SVD(Singular Value Decomposition, 奇异值分解) 是从噪声数据中提取相关特征的强大工具; 与 PCA 类似, SVD 同样也是降维的有效手段, 区别在于 PCA 是通过特征值进行降维, SVD 通过奇异值进行降维.
| 优点 | 简化数据, 去除噪声, 提高算法的结果 |
| 缺点 | 数据的转换可能难以理解 |
| 适用数据类型 | 数值型 |
基础概念
1. 特征值 (出处)
如果说一个向量 v 是方阵 A 的特征向量, 则一定可以表示成下面的形式:
![]()
这时候 λ 就被称为特征向量 v 对应的特征值, 一个矩阵的一组特征向量是一组正交向量.
2. 特征值分解 (出处)
特征值分解可以得到特征值和特征向量, 特征值表示的是这个特征到底有多得要, 而特征向量表示的是这个特征是以, 可以将每一个特征向量理解为一个线性的子空间. 特征值分解将一个矩阵分解成下面的形式:
![]()
特征值分解的局限在于变换的矩阵必须是方阵.
3. 奇异值分解 (出处)
由于特征值分解只适用于方阵, 所以当我们需要描述 m*n 的矩阵的重要特征时, 可以使用奇异值分解, 它能适用于任意矩阵的分解:
![]()
上述分解会构建出矩阵 Σ ,该矩阵只有对角元素, 其他元素均为0.
4. 奇异值
将 3 中的矩阵 Σ 的对角元素就称之为奇异值; 与特征值一样, 这些奇异值标识了数据集中的重要特征. 奇异值和特征值的关系为: 奇异值是矩阵 Data * DataT 特征值的平方根.
SVD算法描述
1. SVD 分解过程
假设根据奇异值分解公式对矩阵进行分解后, 将奇异值按从大到小进行排列, Σ 的值为:
![]()
可以看到, 前 3 个数值远大于后 2 个, 所以我们可以把后 2 个值去掉, 则原始数据集可以按以下结果近似:
![]()
近似计算的示意图可以表示如下: (矩阵 Data 被分解, 浅灰色区域为原始数据, 深灰色区域是矩阵近拟计算仅需要的数据)

2. 奇异值数目选取策略
在以上示例中, 我们可以肉眼看到前 3 个奇异值明显大于后 2 个, 所以我们保留前 3 个奇异值. 在计算机运算时, 有两种典型的实现:
(1). 保留矩阵 90% 的能量信息, 将奇异值求平方和, 直接累加到总值的 90% 为止.
(2). 对于上万个奇异值时, 保留前面 2000 或 3000 个. 需要基于用户对数据值的了解来做出假设.
推荐引擎算法描述
推荐引擎一般步骤为以下3步:
(1). 寻找用户没有评分过的物品 (代码 97 行)
(2). 预测用户对这些没有评分过的物品的评分
(3). 按预测评分从高到低返回这些推荐物品
根据第 (2) 步的不同, 可分为【基于物品相似度的推荐】和【基于 SVD 的推荐】
1. 基于物品相似度
(1). 设现在要评价的物品为 i, 此用户为 u, 此用户还评价了物品 j, 评分为 r
(2). 找到一个同时评价了物品 i 与 j 的用户, 计算他对 i, j 的评分的相似度 s
(3). 则此用户对 i 的预测评分计算应为 s*r
(4). 对此用户评价的其他物品, 循环 (1)->(2)->(3), 最后再进行归一化, 即为用户 u 对 物品 i 的评分
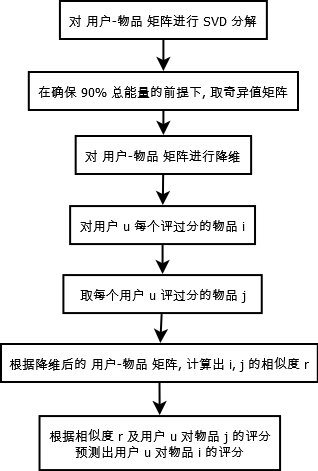
2. 基于 SVD
(1). 对 用户-物品 矩阵进行 SVD 分解
(2). 在保持总能量 90% 前提下, 构建奇异矩阵, 将 用户-物品 矩阵降维
(3). 设现在要评价的物品为 i, 此用户为 u, 此用户还评价了物品 j, 评分为 r
(4). 根据降维后的矩阵, 计算出物品 i 与 物品 j 的相似度为 j
(5). 则此用户对 i 的预测评分计算应为 s*r
(6). 对此用户评价的其他物品, 循环 (3)->(4)->(5), 最后再进行归一化, 即为用户 u 对 物品 i 的评分
推荐引擎算法流程图
1. 基于物品相似度

2. 基于 SVD
代码
# -*- coding: utf-8 -*
from numpy import *
from numpy import linalg as la
# 载入数据 (用户-菜肴矩阵)
# 行为 用户, 列为希肴, 表示用户对某个菜肴的评分
def loadExData2():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 计算两个评分的 欧氏距离
def ecludSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB))
# 计算两个评分的 皮尔逊相关系数 (Pearson Correlation)
def pearsSim(inA,inB):
if len(inA) < 3 : return 1.0
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
# 计算两个评分的 余弦相似度 (Cosine similarity)
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
# 基于物品相似度, 计算用户对物体的评分估计值
# 参数 simMeas 为 相似度计算方法
# 参数 user 为用户编号
# 参数 item 为物品编号
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1] # 矩阵列数, 即物品数
simTotal = 0.0;
ratSimTotal = 0.0
# 遍历每个物品
for j in range(n):
userRating = dataMat[user,j] # 用户对 j 物品的评分, 取不为 0 的计算相似度
if userRating == 0: continue
# overLap 为某个用户都评分的两个物品
# 即某个用户在评分了物品 item 后, 还评分了物品 j, 返回找到的第一个用户
# 把第 item 列与 j 列求 与, 并取第一个不为 0 的行作为 overLap
overLap = nonzero(logical_and(dataMat[:,item].A>0, dataMat[:,j].A>0))[0]
if len(overLap) == 0: similarity = 0
else:
# 计算两个物品评分的相似度
similarity = simMeas(dataMat[overLap,item], dataMat[overLap,j])
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal # 归一化
# 基于 SVD, 计算用户对物体的评分估计值
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0;
ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat) # SVD 分解
# 构建对角距阵, 这里只取前 4 个奇异值, 4 是额外计算出来的, 确保包含能量高于总能量 90%
Sig4 = mat(eye(4)*Sigma[:4])
xformedItems = dataMat.T * U[:,:4] * Sig4.I # 将高维转为低维, 构建转换后的物品
for j in range(n):
userRating = dataMat[user,j] # 用户对 j 物品的评分, 取不为 0 的计算相似度
if userRating == 0 or j==item: continue
# 计算两个物品评分的相似度
similarity = simMeas(xformedItems[item,:].T, xformedItems[j,:].T)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
# 推荐引擎
# 即寻找用户未评分的物品, 并基于物品相似度进行评分
# 对用户评过分的物品, 自然是以他自己的评分为主
# 参数 N 为按推荐分数从高到低返回前 N 个推荐的物品
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
# 寻找用户未评分的物品
unratedItems = nonzero(dataMat[user,:].A==0)[1]
if len(unratedItems) == 0: return 'you rated everything'
itemScores = []
for item in unratedItems:
# 获取用户对物品 item 的评分的估计值
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
# 按推荐分数从高到低返回前 N 个推荐的物品
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
if __name__ == "__main__":
myMat = mat(loadExData2())
# print recommend(myMat, 1, estMethod=standEst)
print recommend(myMat, 1, estMethod=svdEst)
运行结果
1. 基于物品相似度
![]()
2. 基于 SVD
![]()
说明
本文为《Machine Leaning in Action》第十四章(Simplifying data with the singular value decomposition)读书笔记, 代码稍作修改及注释.
好文参考
1.《机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用》
2.《推荐系统相关算法(1):SVD》