批量抓取HTML页面上所有的元素及对应的XAPTH
工作3年多了,没写过博客,真是太失败了,我为自己的懒散、拖延感到懊悔。时间是挤出来的,以后要逼着自己一定要开始练习写博客。
废话不多说,简单描述一下背景:公司的一个部门在给一个打印机厂商做功能测试,其中的Web站点(打印机的内嵌Web服务)可以实现自动化测试,自动化工具开发出来了,但是问题也来了,自动化测试需要用到页面上元素对应的xpath(XML路径语言,标识页面上元素的位置),才能模拟人工操作,于是就有一个这样的需求,要求能够批量的抓取Web页面上所有的元素(包括字符串,按钮,文本框,下拉菜单 等等)以及该字符串对应的XPath(要求跟firebug抓取的一样(而且是相对路径例如://div[@id='content-home-tile-pgNetworkFolderAccounts']/div/div/span[2])),又要求能够自动抓取目标站点上的所有的页面并生成一份报表。
这里有个问题:1,我知道firebug是用js写的,但firebug是怎么抓取页面上元素的Xpath的,原理又是什么?我该如何抓取? 看了一下firebug的源码,头都大了,而且firebug插件不能批量抓取Xpath。时间紧迫,算了,想想别的办法。以前做开发的时候经常会去解析xml文件,得到想要的数据,也用到了Xpath,想着能否像解析XML一样去解析HTML文件呢?查了Web服务器用的HTML版本,发现用的是XHTML,真是喜出望外,平时用dom4j解析XML,于是立即试着解析一个XHTML文件,代码如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Set;
import java.util.Map.Entry;
import java.util.Stack;
import java.util.TreeMap;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFCellStyle;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.hssf.util.HSSFColor;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.VisitorSupport;
import org.dom4j.io.SAXReader;
public class XmlTra {
private File inputXml;
private List<Element> elementList = new ArrayList<Element>();
/**
* 解析html文件
*
* @return docuemnt
*/
private Document getDocument(String fileName) {
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(fileName);
} catch (DocumentException e) {
e.printStackTrace();
}
return document;
}
/**
* @description 得到根节点
* @return Element
*/
// private Element getRootElement(String fileName) {
// return getDocument(fileName).getRootElement();
// }
public void traversalDocumentByVisitor(String fileName) {
getDocument(fileName).accept(new VisitorSupport() {
@Override
public void visit(Element node) {
elementList.add(node);
}
});
}
/**
* @description 给同族的节点标签加上下标 eg:div[1] span[2]
* @param List
* <Element>
*/
private List<Object[]> getTagSequenceListByAgnate(List<Element> list) {
List<Object[]> tagSequenceList = new ArrayList<Object[]>();
List<String> tags = null;
if (list.size() != 0) {
tags = new ArrayList<String>();
for (Element element : list) {
int index = 1;
String tagName = element.getName();
for (String s : tags) {
if (tagName.equals(s)) {
index++;
}
}
tags.add(tagName);
Object[] tagSequence = new Object[2];
tagSequence[0] = element;
tagSequence[1] = new Integer(index);
tagSequenceList.add(tagSequence);
}
}
List<Object[]> _list = new ArrayList<Object[]>();
for (Object[] obj : tagSequenceList) {
Element element = (Element) obj[0];
int index = Integer.valueOf(obj[1].toString());
String tagName = element.getName();
int _index = 0;
if (index == 1) {
for (String str : tags) {
if (tagName.equals(str)) {
_index++;
}
}
if (_index == 1) {
index = 0;
}
obj[0] = element;
obj[1] = new Integer(index);
}
_list.add(obj);
}
return _list;
}
/**
* @description 将同族的节点分到一组
* @return List<Object>
*/
private List<Object[]> getAllTagSeqenceList() {
List<Object[]> allGroups = new ArrayList<Object[]>();
for (int i = 0; i < elementList.size(); i++) {
List<Element> elements = new ArrayList<Element>();
for (int j = 0; j < elementList.size(); j++) {
Element ele = elementList.get(i);
Element _ele = elementList.get(j);
if (!_ele.isRootElement() && _ele.getParent().equals(ele)) {
elements.add(_ele);
}
}
List<Object[]> groupElement = getTagSequenceListByAgnate(elements);
allGroups.addAll(groupElement);
}
return allGroups;
}
/**
* @description 将Eelement对象转化为TagBean,根据节点父子关系拼接封装xpath
* @return List
*/
List<TagBean> getAllTagBeans() {
List<Object[]> eleobjs = getAllTagSeqenceList();
if (eleobjs.size() == 0) {
// log.info("没有得到节点数据");
System.err.println("没有节点数据!");
throw new RuntimeException("没有得到节点!");
}
List<TagBean> tagList = new ArrayList<TagBean>();
for (int i = 0; i < eleobjs.size(); i++) {
Object[] obj = eleobjs.get(i);
Element element = (Element) obj[0];
TagBean bean = new TagBean();
if (element.getTextTrim() != null) {
bean.setText(element.getTextTrim());
} else {
bean.setText("");
}
bean.setTagName(element.getName());
if (element.attributeValue("value") != null) {
bean.setAttributeValue(element.attributeValue("value"));
bean.setText(element.attributeValue("value"));
} else {
bean.setAttributeValue("");
}
if (element.attributeValue("class") != null) {
bean.setClassValue(element.attributeValue("class"));
} else {
bean.setClassValue("");
}
if (element.attribute("type") != null) {
bean.setType(element.attributeValue("type"));
} else {
bean.setType("");
}
bean.setAlias(bean.getText());
String id = element.attributeValue("id");
if (id != null && id.length() > 0) {// 如果有Id
bean.setId(id);
if (id.indexOf("tmpId") > -1) {// 如果id中包含tmpId且有数字
// System.err.println(id);
boolean flag = true;
Element parentEle = null;
String parentId = null;
Stack<Element> stack = new Stack<Element>();
stack.push(element);
while (flag) {
parentEle = stack.peek().getParent();
if (parentEle != null) {
stack.push(parentEle);
parentId = parentEle.attributeValue("id");
if (parentId != null && parentId.length() > 0
&& parentId.indexOf("tmpId") == -1) {
flag = false;
}
} else {
flag = false;
}
}
Element ele = null;
StringBuffer relPath = new StringBuffer("//"
+ stack.peek().getName() + "[@id='");
String _id = stack.peek().attributeValue("id");
if (_id != null && _id.length() > 0) {// 如果父节点有id
relPath.append(_id).append("']").append("/");
stack.pop();
while (stack.size() != 0) {
ele = stack.pop();
int indexTag = 0;
for (Object[] o : eleobjs) {
Element e = (Element) o[0];
if (ele.equals(e)) {
indexTag = Integer.valueOf(o[1].toString());
}
}
if (indexTag == 0) {
relPath.append(ele.getName());
} else {
relPath.append(ele.getName()).append(
"[" + indexTag + "]");
}
if (!ele.equals(element)) {
relPath.append("/");
}
}
} else {
relPath.setLength(0);
relPath.append("/");
while (stack.size() != 0) {
ele = stack.pop();
int indexTag = 1;
for (Object[] o : eleobjs) {
Element e = (Element) o[0];
if (ele.equals(e)) {
indexTag = Integer.valueOf(o[1].toString());
}
}
if (indexTag == 0) {
relPath.append(ele.getName());
} else {
relPath.append(ele.getName()).append(
"[" + indexTag + "]");
}
relPath.append("/");
}
}
bean.setXpath(relPath.toString());
} else {// 若果不包含tmpId且没有数字
bean.setXpath("//" + bean.getTagName() + "[@id='" + id
+ "']");
}
} else {// 如果当前节点没有id
bean.setId("");
boolean flag = true;
Element parentEle = null;
String parentId = null;
Stack<Element> stack = new Stack<Element>();// stack,to store
// the element
// object
stack.push(element);
while (flag) {
parentEle = stack.peek().getParent();
if (parentEle != null) {// if this node has parentNode
stack.push(parentEle);
parentId = parentEle.attributeValue("id");
if (parentId != null && parentId.length() > 0
&& parentId.indexOf("tmpId") == -1) {// if this
// parentNode
// has
// id,not
// contains
// tmpId
flag = false;
}
} else {
flag = false;
}
}
// starting with the id of the parent node joining together,
// constitute the xpath
String _id = stack.peek().attributeValue("id");
Element ele = null;
StringBuffer relPath = new StringBuffer("//"
+ stack.peek().getName() + "[@id='");
if (_id != null && _id.length() > 0) {// if the parent node has
// id
relPath.append(_id).append("']").append("/");
stack.pop();
while (stack.size() != 0) {
ele = stack.pop();
int indexTag = 0;
for (Object[] o : eleobjs) {
Element e = (Element) o[0];
if (ele.equals(e)) {
indexTag = Integer.valueOf(o[1].toString());
}
}
if (indexTag == 0) {
relPath.append(ele.getName());
} else {
relPath.append(ele.getName()).append(
"[" + indexTag + "]");
}
if (!ele.equals(element)) {
relPath.append("/");
}
}
} else {// if the parent node has no id
relPath.setLength(0);
relPath.append("/");
while (stack.size() != 0) {
ele = stack.pop();
int indexTag = 0;
for (Object[] o : eleobjs) {
Element e = (Element) o[0];
if (ele.equals(e)) {
indexTag = Integer.valueOf(o[1].toString());
}
}
if (indexTag == 0) {
relPath.append(ele.getName());
} else {
relPath.append(ele.getName()).append(
"[" + indexTag + "]");
}
relPath.append("/");
}
}
bean.setXpath(relPath.toString());
}
tagList.add(bean);
}
return tagList;
}
}
最后写成报表:如图
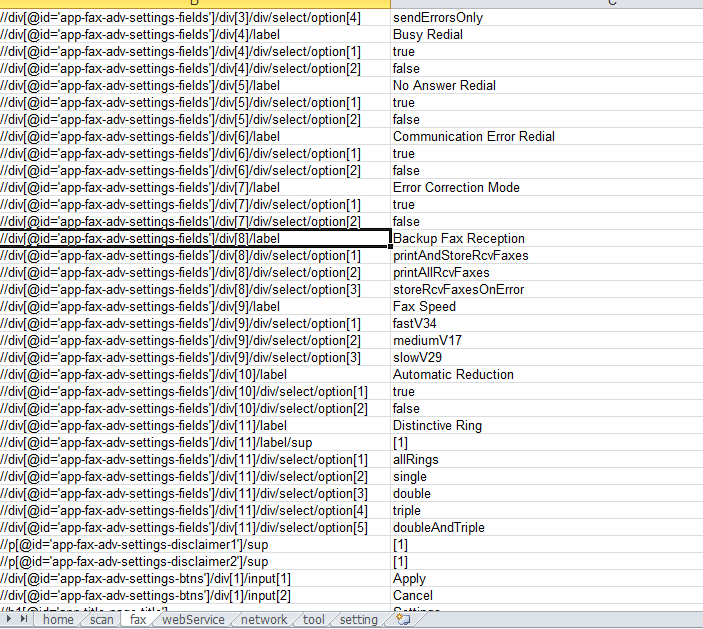
抓取Xpath的问题解决了,下面的问题是 2,如何自动抓取web服务中所有的二级页面,包括需要动态交互的页面?
用爬虫工具爬取?爬不完整,何况动态渲染的页面特别多,不好抓,这里浪费了很多时间,有点急了,跟自动化项目组的Leader沟通,他们建议使用Selenium2,于是花了一周的时间研究Selenium2,发现特别是WebDriver非常好用, 尝试抓取目标站点的页面,最后发现二级、三级页面必须要程序一步一步的操作(包括点击、键入有效的值等操作)才能抓取到完整的XHTML页面文件。
暂时就写到这儿吧。