关于hadoop 2.7.1 集群安装及其平台上的实验
转载请标明出处:
http://blog.csdn.net/zwto1/article/details/50206861;
本文出自:【明月的博客】
版本:
hadoop-2.7.1 下载地址:http://hadoop.apache.org/releases.html
安装:
这里不细细说如何解压之类的步骤,主要是配置这块看下,从头开始安装的话,可以参考这几篇文章:
http://blog.csdn.net/zwto1/article/details/44002083
http://blog.csdn.net/zwto1/article/details/44020263
http://blog.csdn.net/zwto1/article/details/45647643
1.配置各种site文件,文件存放在etc/Hadoop/下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这几个文件。
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
</configuration>yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop:8088</value>
</property>
</configuration>2.配置namenode,修改env环境变量文件
配置之前要确保已安装java7或者以上版本的jdk,并且java的环境变量已经配置好。将hadoop-env.sh、mapred-env.sh、yarn-env.sh这几个文件中的JAVA_HOME改为/usr/local/jdk ,否则启动不起来。
3. slaves文件配置,增加如下两行内容:
hadoop1
hadoop2
4.向节点服务器hadoop1、hadoop2复制我们在hadoop主节点服务器上配置好的hadoop
scp –r hadoop root@hadoop1:/usr/local/
scp –r hadoop root@hadoop2:/usr/local/5.格式化namenode,在主节点上执行如下命令:
bin/hdfs namenode -format 只要出现“successfully formatted”就表示成功了。
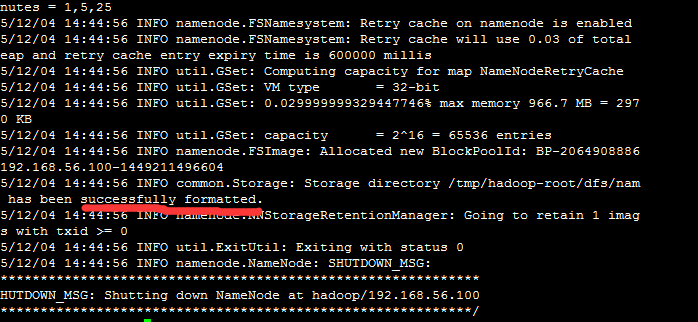
6.启动hadoop
在主结点hadoop上进行操作:
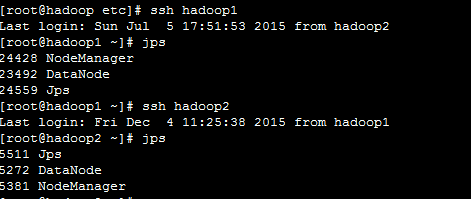
sbin/start-all.sh7.用jps检验各后台进程是否成功启动
hadoop:

hadoop1、hadoop2:
8、可以查看webUI:
hadoop: 50070 进行节点的管理
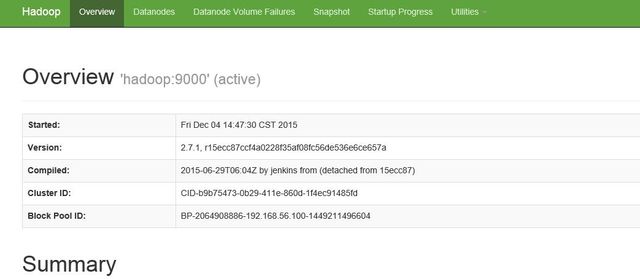
hadoop:8088 显示集群状态

错误信息及解决方案:
1>
recommended: ssh: Could not resolve hostname recommended: Temporary failure in name resolutionssh无法解析主机名,该问题的出现是因为环境变量没有设置好,进行如下配置:
vi /etc/profile
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"让环境变量生效:
source /etc/profile修改好后注意要把文件覆盖掉 hadoop1 和hadoop2 节点的profile:
scp -r /etc/profile root@hadoop1:/etc/
scp -r /etc/profile root@hadoop2:/etc/2>
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable这个问题不影响使用,staticoverflow 是这么回答的:
I assume you’re running Hadoop on 64bit CentOS. The reason you saw that warning is the native Hadoop library $HADOOP_HOME/lib/native/libhadoop.so.1.0.0 was actually compiled on 32 bit.
Anyway, it’s just a warning, and won’t impact Hadoop’s functionalities.
Here is the way if you do want to eliminate this warning, download the source code of Hadoop and recompile libhadoop.so.1.0.0 on 64bit system, then replace the 32bit one.
Steps on how to recompile source code are included here for Ubuntu:
http://www.ercoppa.org/Linux-Compile-Hadoop-220-fix-Unable-to-load-native-hadoop-library.htm
http://www.csrdu.org/nauman/2014/01/23/geting-started-with-hadoop-2-2-0-building/
从上面可以知道,并不影响我们使用,如果想解决这个警告,需要重新编译libhadoop.so.1.0.0这个文件,这里先放下,不做编译。
3>
mkdir: Cannot create directory /tmp. Name node is in safe mode这个问题,查了很长时间,终于在stackoverflow找到解决方案,stackoverflow一个很牛逼的网站。
问答地址:http://stackoverflow.com/questions/13729510/safemodeexception-name-node-is-in-safe-mode?newreg=201bb5a7ead1459286d9629c573963f8#
回答如下:
NameNode is in safemode until configured percent of blocks reported to be online by the data nodes. It can be configured by parameter dfs.namenode.safemode.threshold-pct in the hdfs-site.xml
For small / development clusters, where you have very few blocks - it makes sense to make this parameter lower then its default 0.9999f value. Otherwise 1 missing block can lead to system to hang in safemode.
从上面我们知道dfs.namenode.safemode.threshold-pct默认值为0.9999f,我们要设置比它更小的值。
我们需要重新设置hdfs-site.xml的相关参数,我设置如下:
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0</value>
</property>在各个节点,都要加上这个参数配置,然后重启hadoop,问题解决。
实验:
1>向hadoop集群系统提交第一个mapreduce任务
bin/hdfs dfs -mkdir /tmp 在虚拟分布式文件系统上创建一个测试目录tmp
bin/hdfs dfs -copyFromLocal /test.txt /tmp 将根目录下的test.txt文件复制到虚拟分布式文件系统中
bin/hdfs dfs -ls /tmp 查看文件系统中是否存在我们所复制的文件
![]()
运行如下命令向hadoop提交单词统计任务
bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /tmp/test.txt /tmp-output运算结果显示如下:
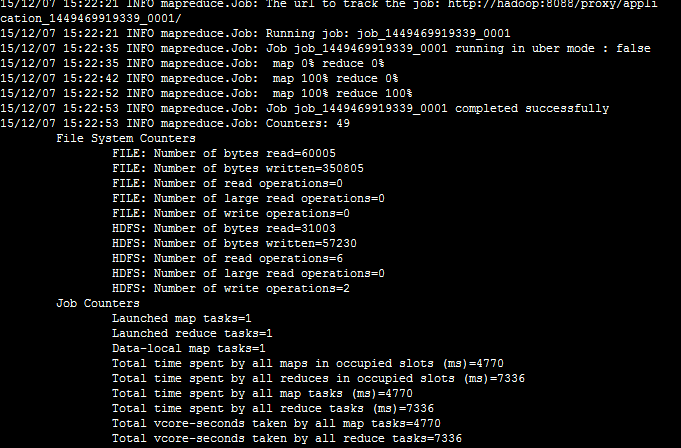
注意:
在你重新格式化分布式文件系统之前,需要将文件系统中的数据先清除,否则,datanode将创建不成功。
hadoop2.7.1 成功搭建完毕,完成第一个分布式计算任务。接下来就可以尽情的玩它了!
参考:
1.http://stackoverflow.com/questions/13729510/safemodeexception-name-node-is-in-safe-mode?newreg=201bb5a7ead1459286d9629c573963f8
2.http://stackoverflow.com/questions/19943766/hadoop-unable-to-load-native-hadoop-library-for-your-platform-warning
3.http://www.07net01.com/2015/07/874408.html