一次代码重构之旅---Java读取Excel(一)
最近工作需要一个读取excel文件的工具,结合网络资源写了一个工具类,初步实现了功能。好,老样子,先描述一下业务需求。(基于JFinal2.1版本)
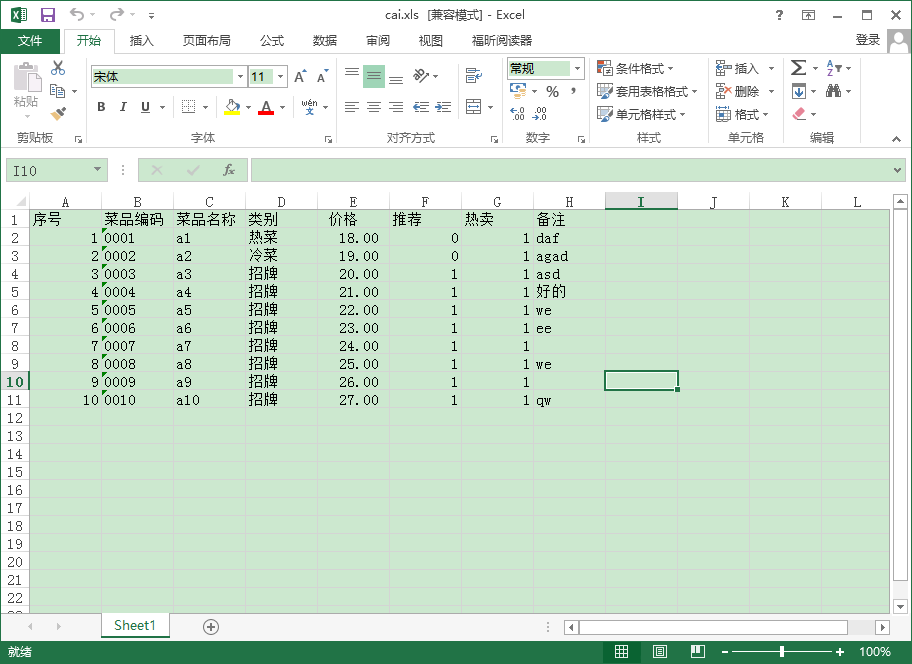
读取excel文件,双方约定此文件模板内容,具体见下图
后台处理读取数据并写库

分析了这个简单的需求,其实要做的事情还很多,下面就分步骤动手开始做:
读取excel数据
因为要写数据库,所以要按map这种键值对来匹配读取的数据
处理读取的数据
写库
读取excel文件数据
(看不明白没关系,先往下看)
/**
* 读取Excel2003-2007文件 .xls
* @param path
* @return
* @throws Exception
*/
public List<Map<String,String>> readXls(String path) throws Exception{
InputStream is = new FileInputStream(path);
//创建对象
HSSFWorkbook hssfWorkbook = new HSSFWorkbook(is);
List<Map<String,String>> lists = new ArrayList<Map<String,String>>();
//获取sheet工作表
for(int numSheet=0;numSheet<hssfWorkbook.getNumberOfSheets();numSheet++){
HSSFSheet hssfSheet = hssfWorkbook.getSheetAt(numSheet);
if(hssfSheet==null){
continue;
}
for(int rowNum=1;rowNum<=hssfSheet.getLastRowNum();rowNum++){
HSSFRow hssfRow = hssfSheet.getRow(rowNum);
if(hssfRow == null){
throw new Exception("第"+ (rowNum+1) +"行有空行");
}
int minColIndex = hssfRow.getFirstCellNum();
int maxColIndex = hssfRow.getLastCellNum();
getListMapBy2003(lists, hssfRow, minColIndex, maxColIndex);
}
System.out.println(JsonKit.toJson(lists));
}
return lists;
}
/**
* 按heads构建map
* @param lists
* @param hssfRow
* @param minColIndex
* @param maxColIndex
*/
private void getListMapBy2003(List<Map<String, String>> lists, HSSFRow hssfRow, int minColIndex, int maxColIndex) {
Map<String, String> map = new HashMap<String, String>();
String[] heads = getHead();
for(int colIndex=minColIndex;colIndex<maxColIndex;colIndex++){
HSSFCell cell = hssfRow.getCell(colIndex+1);
if(cell == null){//处理列为空
if(colIndex<heads.length){
map.put(heads[colIndex], "");
}
continue;
}
if(colIndex<heads.length){
map.put(heads[colIndex], getValue(cell));//构建map键值对
}
lists.add(map);
}
System.out.println(JsonKit.toJson(map));
}
设置key
public String[] getHead(){
String[] heads = new String[]{"code","name","cate","price","hot","pop","remark"};
return heads;
}
这里有必要解释一下为啥这么做
首先回头看约定好的excel文件内容,在插入数据库时第一列的【序号】是不需要写库的,只要将之后的每列数据匹配好就行,但是标题是中文不能直接用,因此我们就写上面这个方法来保存我们要用到的key,基本上我们需要拿到这样的数据:
{"code":"0001","name":"牛排","cate":"招牌菜","price":"22.00","hot":"1","pop":"1","remark":"隆重推荐"};
key就是heads数组的值,value就是我们读取的每一列数据。
处理读取的数据
private String getValue(XSSFCell xssfRow) {
if (xssfRow.getCellType() == xssfRow.CELL_TYPE_BOOLEAN) {
return String.valueOf(xssfRow.getBooleanCellValue());
} else if (xssfRow.getCellType() == xssfRow.CELL_TYPE_NUMERIC) {
return String.valueOf(xssfRow.getNumericCellValue());
} else {
return String.valueOf(xssfRow.getStringCellValue());
}
}
好,我们先把所做代码整体放出来
package com.feng.excel;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import com.jfinal.kit.JsonKit;
public class ReadExcel3 {
public static final String EXCEL2003 = "xls";
public static final String EXCEL2010 = "xlsx";
public static final String EMPTY = "";
public static String getFix(String path){
if(path.trim()!=null){
return path.substring(path.lastIndexOf(".")+1, path.length());
}
return EMPTY;
}
public String[] getHead(){
String[] heads = new String[]{"code","name","cate","price","hot","pop","remark"};
return heads;
}
/**
* 读取Excel2010文件 .xlsx
* @param path
* @return
* @throws Exception
*/
public List<Map<String,String>> readXlsx(String path) throws Exception{
InputStream is = new FileInputStream(path);
//创建对象
XSSFWorkbook xssfWorkbook = new XSSFWorkbook(is);
List<Map<String,String>> lists = new ArrayList<Map<String,String>>();
//获取sheet工作表
for(XSSFSheet xssfSheet : xssfWorkbook){
if(xssfSheet == null){
continue;
}
//遍历除标题外所有的行
for(int rowNum=1;rowNum<=xssfSheet.getLastRowNum();rowNum++){
XSSFRow row = xssfSheet.getRow(rowNum);
if(row == null){
throw new Exception("第"+ (rowNum+1) +"行有空行");
}
int minColIndex = row.getFirstCellNum();
int maxColIndex = row.getLastCellNum();
getListMapBy2010(lists, row, minColIndex, maxColIndex);
}
System.out.println(JsonKit.toJson(lists));
}
return lists;
}
/**
* 读取Excel2003-2007文件 .xls
* @param path
* @return
* @throws Exception
*/
public List<Map<String,String>> readXls(String path) throws Exception{
InputStream is = new FileInputStream(path);
//创建对象
HSSFWorkbook hssfWorkbook = new HSSFWorkbook(is);
List<Map<String,String>> lists = new ArrayList<Map<String,String>>();
//获取sheet工作表
for(int numSheet=0;numSheet<hssfWorkbook.getNumberOfSheets();numSheet++){
HSSFSheet hssfSheet = hssfWorkbook.getSheetAt(numSheet);
if(hssfSheet==null){
continue;
}
for(int rowNum=1;rowNum<=hssfSheet.getLastRowNum();rowNum++){
HSSFRow hssfRow = hssfSheet.getRow(rowNum);
if(hssfRow == null){
throw new Exception("第"+ (rowNum+1) +"行有空行");
}
int minColIndex = hssfRow.getFirstCellNum();
int maxColIndex = hssfRow.getLastCellNum();
getListMapBy2003(lists, hssfRow, minColIndex, maxColIndex);
}
System.out.println(JsonKit.toJson(lists));
}
return lists;
}
/**
* 按heads构建map
* @param lists
* @param hssfRow
* @param minColIndex
* @param maxColIndex
*/
private void getListMapBy2003(List<Map<String, String>> lists, HSSFRow hssfRow, int minColIndex, int maxColIndex) {
Map<String, String> map = new HashMap<String, String>();
String[] heads = getHead();
for(int colIndex=minColIndex;colIndex<maxColIndex;colIndex++){
HSSFCell cell = hssfRow.getCell(colIndex+1);
if(cell == null){//处理列为空
if(colIndex<heads.length){
map.put(heads[colIndex], "");
}
continue;
}
if(colIndex<heads.length){
map.put(heads[colIndex], getValue(cell));//构建map键值对
}
lists.add(map);
}
System.out.println(JsonKit.toJson(map));
}
/**
* 按heads构建map
* @param lists
* @param row
* @param minColIndex
* @param maxColIndex
*/
private void getListMapBy2010(List<Map<String,String>> lists, XSSFRow xssfRow, int minColIndex, int maxColIndex){
Map<String, String> map = new HashMap<String, String>();
String[] heads = getHead();
for(int colIndex=minColIndex;colIndex<maxColIndex;colIndex++){
XSSFCell cell = xssfRow.getCell(colIndex+1);
if(cell == null){//处理列为空
if(colIndex<heads.length){
map.put(heads[colIndex], "");
}
continue;
}
if(colIndex<heads.length){
map.put(heads[colIndex], getValue(cell));//构建map键值对
}
lists.add(map);
}
System.out.println(JsonKit.toJson(map));
}
@SuppressWarnings("static-access")
private String getValue(XSSFCell xssfRow) {
if (xssfRow.getCellType() == xssfRow.CELL_TYPE_BOOLEAN) {
return String.valueOf(xssfRow.getBooleanCellValue());
} else if (xssfRow.getCellType() == xssfRow.CELL_TYPE_NUMERIC) {
return String.valueOf(xssfRow.getNumericCellValue());
} else {
return String.valueOf(xssfRow.getStringCellValue());
}
}
@SuppressWarnings("static-access")
private String getValue(HSSFCell hssfCell) {
if (hssfCell.getCellType() == hssfCell.CELL_TYPE_BOOLEAN) {
return String.valueOf(hssfCell.getBooleanCellValue());
} else if (hssfCell.getCellType() == hssfCell.CELL_TYPE_NUMERIC) {
return String.valueOf(hssfCell.getNumericCellValue());
} else {
return String.valueOf(hssfCell.getStringCellValue());
}
}
public static void main(String[] args) {
String path = "E:\\cai.xlsx";
try {
if(getFix(path).equals(EXCEL2003)){
System.out.println("读取2003Excel文件");
new ReadExcel3().readXls(path);
}else if(getFix(path).equals(EXCEL2010)){
System.out.println("读取2010Excel文件");
new ReadExcel3().readXlsx(path);
}else{
System.out.println("读取失败:请上传xls或xlsx文件!");
}
System.out.println("读取结束");
} catch (Exception e) {
e.printStackTrace();
}
}
}
虽然以上代码已经实现了读取excel文件数据,但是看到一些重复的代码,是不是很恶心?OK,那么我们就开始重构他,让这些代码更简洁!