很有意思的组合
背景
在我们的系统架构中,Nginx作为所有HTTP请求的入口,是非常重要的一层。每天产生大量的Nginx Access Log,闲置在硬盘上实在是太浪费资源了。所以,能不能把Nginx日志利用起来,实时监控每个业务的访问趋势、用户行为、请求质量和后端异常呢,这就是本文要探讨的主题。
目的
- 错误码告警(499、500、502和504);
- upstream_response_time超时告警;
- request_time超时告警;
- 数据分析;
关于错误和超时监控有一点要考虑的是收到告警时,要能够快速知道是哪个后端服务节点出现了问题。
在这之前,我们都是通过随机进入一个Nginx节点tail log才能定位到,效率有些低。
架构
废话不多说,先上架构图。整体架构没太复杂的地方,随便画了一张,莫笑话我~
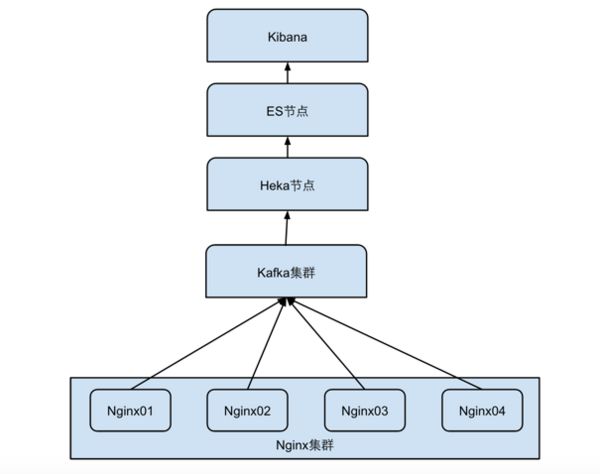
日志采集
这部分结合lua-resty-kafka使用Lua扩展将数据按照一定格式拼接后写入Kafka集群。Nginx+Lua的性能就不用多说了,这样一来完全可以关掉Nginx本身的日志开关,减少磁盘消耗;
消息队列
我们数据分析组的同事在这之前就已经建立Kafka集群,无需再搞一套消息队列服务。另外一个很重要的点是,我们不希望日志数据取完就删掉了,运维组除了要做监控告警之外,数据组也要读取数据做分析。因此,如Redis此类的消息队列就直接被我们pass掉了;
异常监控计算
这部分使用Heka来做,Heka使用Go语言编写,内置丰富的插件可以满足大部分的需求。若不满足需求,可以使用Go或者Lua自行开发扩展。之前使用过Logstash做业务日志收集,但它有时的CPU占用实在太吓人,不敢再在业务机上使用,并且感觉扩展不方便。就我们目前的应用来看,Heka 的性能和资源占用还是很不错的。
可以使用Filter做计算,有错误时向Heka消息流中写入告警消息,SMTPOuter匹配到告警消息后通过自定义的Encoder定制好邮件内容后再发送。
可视化
Heka层一方面做异常监控,另一方面使用Message Matcher Syntax匹配异常数据写入到Elasticsearch, 再架设一个Kibana。我们在收到告警邮件后,就可以进入Kibana后台查看异常的Log。
不足
- 邮件告警机制需要优化, 我们目前的设置是每分钟检查一次,发现错误就会一直告警。之后可以优化为发现异常时告警一次,异常结束时再发一次汇总邮件;
- Heka服务管理和进程监控需要优化,支持自动重启,不然进程挂了都不知道;
- Heka配置接入配置中心并支持自动重启(目前的配置主要是各业务的告警阀值,需要进入机器修改);
总结
整个开发过程还是比较顺利的,唯一比较耗时的是熟悉Heka的整个消息处理的流程和机制,以及如何开发扩展。另一个比较坑的是Heka的错误提示不全和调试不方便,有时完全靠猜,不过好在它本身并没有多复杂,有些问题看一看源代码就明白了。
关于消息队列的选择,前面已经提到我们已有Kafka集群就直接拿来用了。如果仅仅做异常监控,不需要消息留存, 倒可以考虑使用Redis之类轻量些的消息队列, Kafka未免有些重了。