比较目的
衡量每种分词的指标,内存消耗、CPU消耗,得到一个在Lucene中比较好的分词版本。
分词源代码介绍
-
paoding: 庖丁解牛最新版在 https://code.google.com/p/paoding/ 中最多支持Lucene 3.0,且最新提交的代码在 2008-06-03,在svn中最新也是2010年提交,已经过时,不予考虑。
-
mmseg4j:最新版已从 https://code.google.com/p/mmseg4j/ 移至 https://github.com/chenlb/mmseg4j-solr,支持Lucene 4.10,且在github中最新提交代码是2014年6月,从09年~14年一共有:18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
-
IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
-
ansj_seg:最新版本在 https://github.com/NLPchina/ansj_seg tags仅有1.1版本,从2012年到2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个由CRF(条件随机场)算法所做的分词算法。
-
imdict-chinese-analyzer:最新版在 https://code.google.com/p/imdict-chinese-analyzer/ , 最新更新也在2009年5月,下载源码,不支持Lucene 4.10 。是利用HMM(隐马尔科夫链)算法。
-
Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。利用mmseg算法。
测试环境:
Ubuntu 14.04 64位, 内存 32GB, CPU Intel® Core™ i7-4770K CPU @ 3.50GHz × 8
分词算法衡量指标及测试代码
黄金标准/Golden standard
评价一个分词器分词结果的好坏,必然要有一份“公认正确”的分词结果数据来作为参照。 SIGHAN(国际计算语言学会(ACL)中文语言处理小组)举办的国际中文语言处理竞赛Second International Chinese Word Segmentation Bakeoff(http://sighan.cs.uchicago.edu/bakeoff2005/)所提供的公开数据来评测,它包含了多个测试集以及对应的黄金标准分词结果。在所有分词器都使用同一标准来评测的情况下,也就会很公平,并不会影响到最终的结论,所以本文用此测评标准,并针对创建索引,做了些改动。
评价指标
-
精度(Precision):精度表明了分词器分词的准确程度。
-
召回率(Recall):召回率也可认为是“查全率”。
-
F值(F-mesure):F值综合反映整体的指标。
-
错误率(Error Rate --ER)(带选项):分词器分词的错误程度。
公式
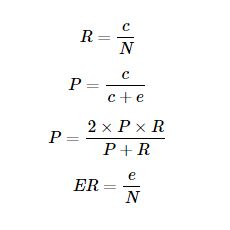
公式参数说明N:黄金标准分割的单词数; e:分词器错误标注的单词数; c:分词器正确标注的单词数.
总结:P、R、F越大越好,ER越小越好。一个完美的分词器的P、R、F值均为1,ER值为0。
正确及错误标注的计数算法要先计算出e和c,才能计算出各指标值。e和c是按如下算法来统计的: 在“黄金标准”和“待评测的结果”中,理论上,除了分词后添加的空格之外,它们所有的文字都是相同的;唯一的不同就在于那些有差异的分词结果的位置上。例如,“计算机 是个 好东西”(黄金标准)与“计算机 是 个 好东西”(待评测的结果)的差异就在于“是个”与“是 个”的差异,其余分词结果都是相同的。因此,只需要找到这种差异的个数,就可以统计出分词器正确标注了多少个词、错误标注了多少个词。为了完成测试指标,同时,对应Lucene的检索实际需要对黄金标准的 *_test_gold和分词结果做了如下改动:
-
去掉标点符号
-
统一对一些虚词作停词处理
-
没有分开句子,结果都是一个比较集。
#!/usr/bin/perl if (@ARGV != 2) { print "No param which will be read!"; exit; } open (FpStopDir, $ARGV[0]) or die "The stopping dictionary($ARGV[0]) cannot open!$!\n"; %dict = (); while(<FpStopDir>){ chop; s/^\s*//;#remove start space char s/\s*$//;#remove the space char in the end of string $dict{$_} = 1; } close(FpStopDir); open(FpDeal, $ARGV[1]) or die "The file ($ARGV[1]) which will be dealed cannot open! $!\n"; my@DealedWord; while (<FpDeal>){ @Word = split /\s+/, $_; foreach $AWord(@Word){ if(1 != $dict{$AWord}){ print "$AWord "; } } } close(FpDeal);Java测试代码
package com.hansight; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.cjk.CJKAnalyzer; import org.apache.lucene.analysis.core.SimpleAnalyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.lionsoul.jcseg.analyzer.JcsegAnalyzer4X; import org.lionsoul.jcseg.core.*; import org.wltea.analyzer.lucene.IKAnalyzer; import com.chenlb.mmseg4j.analysis.ComplexAnalyzer; import java.io.*; public class TestChineseAnalyzer { private static int PER_TIME_READ_LEN = 1024; //每次读入文件流长度 private TestChineseAnalyzer() {} public static void printTerms(Analyzer analyzer, String content){ try{ TokenStream ts = analyzer.tokenStream("content", new StringReader(content)); CharTermAttribute term = ts.addAttribute(CharTermAttribute.class); ts.reset(); StringBuffer buf = new StringBuffer(); while (ts.incrementToken()) { buf.append(term.toString()); buf.append(" "); } System.out.println(buf.toString()); System.out.println(analyzer.getClass().getName() + " done\n"); }catch (IOException ex){ System.out.println("Segment word fail. " + ex.getMessage()); } } public static void main(String[] args){ if (0 == args.length){ System.err.println("No Inputing param"); System.exit(1); } try { FileInputStream in = new FileInputStream(new File(args[0])); byte[] perRead = new byte[PER_TIME_READ_LEN]; String strContent = " "; int rst = in.read(perRead, 0, PER_TIME_READ_LEN); while (-1 != rst){ strContent = strContent.concat(new String(perRead)); rst = in.read(perRead, 0, PER_TIME_READ_LEN); } printTerms(new JcsegAnalyzer4X(JcsegTaskConfig.COMPLEX_MODE), strContent); printTerms(new IKAnalyzer(true), strContent); printTerms(new CJKAnalyzer(), strContent); printTerms(new SimpleAnalyzer(), strContent); printTerms(new StandardAnalyzer(), strContent); printTerms(new ComplexAnalyzer(), strContent); } catch (Exception ex) { ex.printStackTrace(); } } }
运行Java通过重定向到一个txt文件,再将彼此分开,如上所示,没有看过Lucene本身的分词的烂,所以自己也查看了一下,果然很烂。 通过对结果的处理(用上面的Perl脚本,统一对标准和对结果的处理)。再利用 黄金标准中的Perl评分脚本。
Table 1. 评分结果| msr | IK | 0.660 | 0.708 | 0.683 |
| Jcseg | 0.766 | 0.757 | 0.761 | |
| mmseg4j | 0.718 | 0.711 | 0.714 | |
| puk | IK | 0.642 | 0.730 | 0.683 |
| Jcseg | 0.735 | 0.767 | 0.750 | |
| mmseg4j | 0.694 | 0.720 | 0.707 |
此结果并没有按照黄金标准正确用法来用(主要没有用黄金标准来训练,且评分本身是一句一句的评分,最后是综合得分。 而本文是所有内容一起评分,会有一定误差)。同时:现在的分词,比较而言更加智能,能将数量词等(一位,同志们)分在一起,是以前可能没能想过的。 虽然,有诸多误差,但是本文只是比较相对值,只要在统一的相对正确的标准下也就能达到效果了。
分词算法内存和cup测试
在一个大的语料库中,所有文档加入Lucene索引的时间,测试内存使用情况,就将索引建立在磁盘中; 若是测试CPU使用情况,就将所以建立的内存中减小IO读写对CPU的影响。利用VisualVM查看CPU利用率、内存利用率,得到他们的时间序列图。
Java程序如下package com.hansight; import org.apache.lucene.store.RAMDirectory; import org.lionsoul.jcseg.analyzer.JcsegAnalyzer4X; import com.chenlb.mmseg4j.analysis.ComplexAnalyzer; import org.apache.lucene.document.*; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; import org.lionsoul.jcseg.core.JcsegTaskConfig; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.*; import java.nio.charset.StandardCharsets; public class FileIndexTest { private FileIndexTest() {} private IndexWriterConfig conf = null; public FileIndexTest(IndexWriterConfig conf) { this.conf = conf; } public void indexFilesInDir(String docsPath, String indexPath, boolean createIfNotExists){ final File docDir = new File(docsPath); if (!docDir.exists() || !docDir.canRead()) { System.out.println("Document directory '" +docDir.getAbsolutePath()+ "' does not exist or is not readable, please check the path"); System.exit(1); } long start = System.currentTimeMillis(); try { System.out.println("Indexing into directory '" + indexPath + "'..."); Directory dir = null != indexPath ? FSDirectory.open(new File(indexPath)): new RAMDirectory(); if (createIfNotExists) { conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE); } else { conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); } IndexWriter writer = new IndexWriter(dir, conf); indexDocs(writer, docDir); writer.close(); System.out.println(System.currentTimeMillis() - start + " total milliseconds"); } catch (IOException ex) { ex.printStackTrace(); } } public static void indexDocs(IndexWriter writer, File file) throws IOException { if (file.canRead()) { if (file.isDirectory()) { String[] files = file.list(); if (files != null) { for (int i = 0; i < files.length; i++) { indexDocs(writer, new File(file, files[i])); } } } else { FileInputStream fis; try { fis = new FileInputStream(file); } catch (FileNotFoundException fnfe) { return; } try { Document doc = new Document(); Field pathField = new StringField("path", file.getPath(), Field.Store.YES); doc.add(pathField); doc.add(new LongField("modified", file.lastModified(), Field.Store.NO)); doc.add(new TextField("contents", new BufferedReader(new InputStreamReader(fis, StandardCharsets.UTF_8)))); if (writer.getConfig().getOpenMode() == IndexWriterConfig.OpenMode.CREATE) { // New index, so we just add the document (no old document can be there): System.out.println("adding " + file); writer.addDocument(doc); } else { System.out.println("updating " + file); writer.updateDocument(new Term("path", file.getPath()), doc); } } finally { fis.close(); } } } } public static void main(String[] args) { String usage = "java org.apache.lucene.demo.IndexFiles" + " [-index INDEX_PATH] [-docs DOCS_PATH] [-update]\n\n" + "This indexes the documents in DOCS_PATH, creating a Lucene index" + "in INDEX_PATH that can be searched with SearchFiles"; String indexPath = null; String docsPath = null; boolean create = true; for (int i = 0; i < args.length; i++) { if ("-index".equals(args[i])) { indexPath = args[i + 1]; i++; } else if ("-docs".equals(args[i])) { docsPath = args[i + 1]; i++; } else if ("-update".equals(args[i])) { create = false; } } if (docsPath == null) { System.err.println("Usage: " + usage); System.exit(1); } /*IKAnalyzer*/ FileIndexTest test = new FileIndexTest(new IndexWriterConfig(Version.LUCENE_4_10_2, new IKAnalyzer())); test.indexFilesInDir(docsPath, indexPath, create); /*Jcseg*/ FileIndexTest test1 = new FileIndexTest(new IndexWriterConfig(Version.LUCENE_4_10_2, new JcsegAnalyzer4X(JcsegTaskConfig.COMPLEX_MODE))); test1.indexFilesInDir(docsPath, indexPath, create); /*mmseg*/ FileIndexTest test2 = new FileIndexTest(new IndexWriterConfig(Version.LUCENE_4_10_2, new ComplexAnalyzer())); test2.indexFilesInDir(docsPath, indexPath, create); } }
如上所示:IK-analyzer、Jcseg、mmseg4j都是用统一接口,测试,就将其他两个给注释掉。 同时:当测试内存消耗量时, 我们需要将索引建立在磁盘中测试jar包的命令例子如下:
java -jar indexFile.jar -docs ~/resource/ -index ~/index/
当测试CPU消耗时,我们尽量减小IO的消耗,那么可以将索引建立在内存中,测试jar包的命令例子如下:
java -jar indexFile.jar -docs ~/resource/s
得到如下面所有图所示的结果:
 Figure 1. IK-Analyzer分词消耗内存
Figure 1. IK-Analyzer分词消耗内存
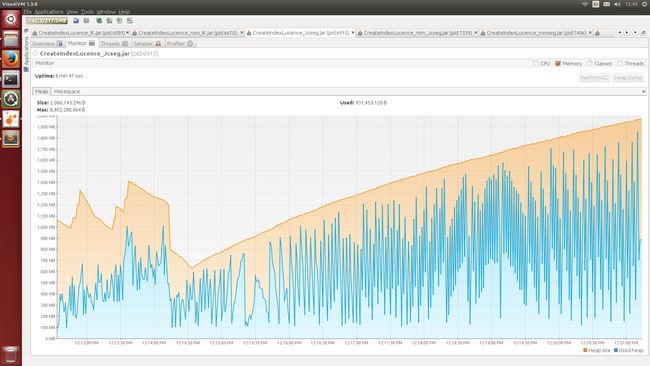 Figure 2. Jcseg分词消耗内存
Figure 2. Jcseg分词消耗内存
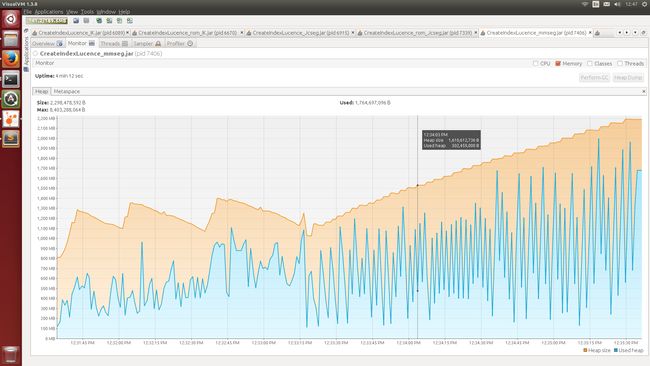 Figure 3. mmseg4j分词消耗内存
Figure 3. mmseg4j分词消耗内存
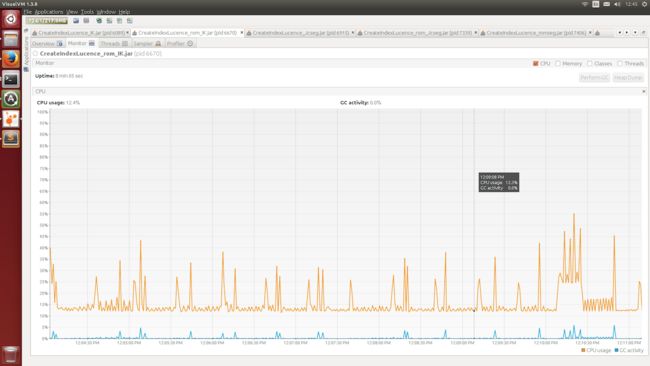 Figure 4. IK-Analyzer分词CPU使用率
Figure 4. IK-Analyzer分词CPU使用率
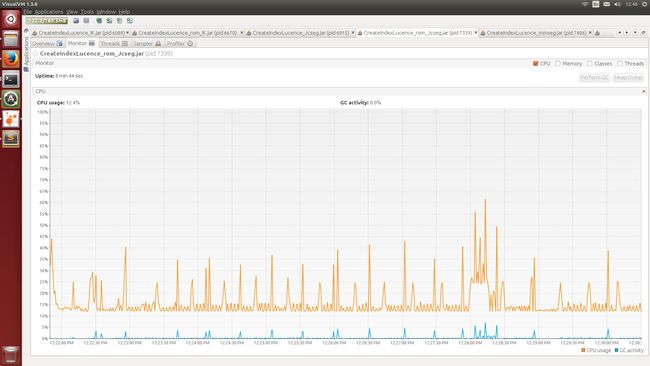 Figure 5. Jcseg分词CPU使用率
Figure 5. Jcseg分词CPU使用率
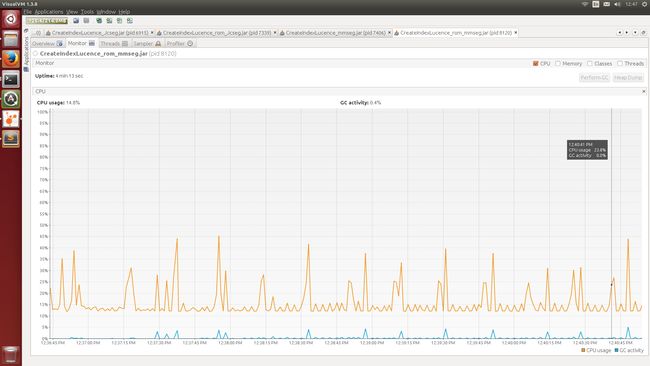 Figure 6. mmseg4j分词CPU使用率
Figure 6. mmseg4j分词CPU使用率
从几个指标对比来看:IK-analyzer的准确度稍差,Jcseg的时间消耗稍差
时间消耗上:在索引创建1,003,057 items, totalling 2.8 GB的文件:
将其索引放入磁盘 Jcseg + Lucene建索引消耗: 516971 total milliseconds mmseg4j + Lucene建索引消耗: 256805 total milliseconds IK-Analyzer + Lucene建索引消耗: 445591 total milliseconds Standard + Lucene建索引消耗: 184717 total milliseconds 内存消耗最大不过650M多 CPU消耗减小不大 (磁盘数据仅仅增加0.2G~0.3G左右) 将索引放在内存中 Jcseg + Lucene 建索引消耗: 510146 total milliseconds mmseg4j + Lucene建索引消耗: 262682 total milliseconds IK-Analyzer + Lucene建索引消耗: 436900 total milliseconds Standard + Lucene建索引消耗: 183271 total milliseconds CUP的高峰值频率明显增多
综上所有因素:
-
准确率为:Jcseg > mmseg4j > IK-Analyzer。
-
内存消耗和CPU使用率上,几个都在一个数量级上,很难分出胜负。
-
但是在时间消耗上明显mmseg4j的优势非常突出。
-
从活跃度来看,mmseg4j的活跃度也是非常可喜的。