storm元数据总体交互
1、$rootPath/workerbeats/$topology_id/$node_port
存储由node和port指定worker的运行状态和一些统计信息。
包括:topologyId、worker上executor统计信息(发送消息数,接收消息数等)、worker启动时间、最后一次更新时间。
2、$rootPath/storms/$topology_id
存储topology的本身信息:名字、启动时间、运行状态、要使用的worker数以及组件并行度设置,运行过程中不会变化。
3、$rootPath/assignments/$topology_id
存储任务分配信息:topology在nimbus的存储目录、分配到supervisor机器到主机名的映射关系、每个executor运行在哪个worker以及每个worker的启动时间。运行过程中数据会变化。
4、$rootPath/supervisors/$supervisor_id
存储supervisor机器本身运行统计信息:最近一次更新时间、主机名、supervisorId、已经使用的端口列表、所有端口列表以及运行时间。运行过程中数据会变化。
5、$rootPath/errors/$topology_id/$commponent_id/$sequential_id
存储运行过程中每个组件发生的错误信息,sequential_id是递增的序列号,每一个组件最多只会保留最近的10条错误信息,他运行过程中是不会变,可能会被删除。
二>、storm元数据交互
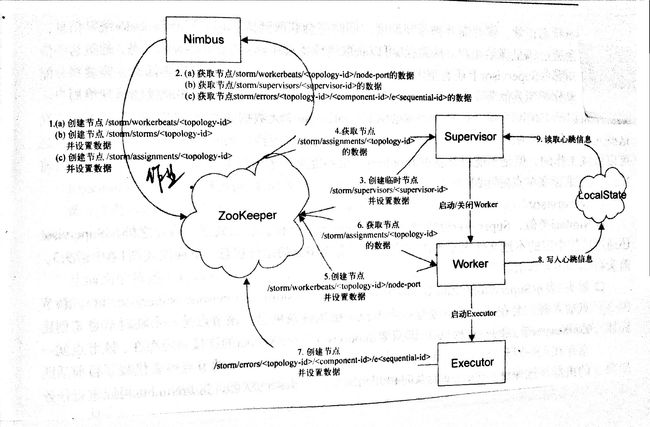
1、nimbus
nimbus既需要在zookeeper创建元数据,也需要从zookeeper中获取数据。
箭头1表示由nimbus创建的路径:
a. /storm/workerbeats/$topology_id
b. /storm/storms/$topology_id
c. /storm/assignments/$topology_id
nimbus提交数据时会创建a、b路径,a路径不写数据,b路径会写数据;
nimbus分配任务时会创建c路径的同时设置数据,任务分配计划有变,Nimbus会更新内容。
箭头2表示由nimbus需要获取数据的路径:
a. /storm/workerbeats/$topology_id/$node_port
b. /storm/supervisors/$supervisor_id
c. /storm/errors/$topoloty_id/$component_id/$sequential_id
nimbus从a路径读取当前已经被分配的worker的运行状态,根据worker状态确定是否需要重新调度,还可以获取到该worker的executor的运行统计信息。
路径b获取集群supervisor的的状态,通过这些信息确认哪些空闲资源可用,哪些supervisor不再活跃,需要分配到其他节点上。
路径c数据通过storm ui提供给用户看。
2、supervisor
箭头3 /storm/supervisors/$supervisor_id,表示supervisor在zookeeper中创建的路径,新节点加入集群会创建一个节点。节点是临时的,一旦断开连接节点就会自动被zookeeper删除。这能保证nimbus能及时获取集群的节点信息,为容错&扩展提供基础。
箭头4 /storm/assignments/$topology_id表示supervisor需要获取的路径,nimbus将分配信息的信息写入zookeeper,supervisor从zookeeper获取分配的任务,supervisor本地保存上次任务的信息,比较两次分配信息是否有变化,如果有变化,需要移除所对应的的worker,并创建新worker。
箭头9表示supervisor会从localStae获取本机所有启动的worker的心跳信息,如果发现心跳信息超时会杀掉worker,原本分配的这个worker任务也会被nimbus重新分配。
3、worker
箭头5中/storm/workerbeats/$topology_id/$node_port表示worker启动时会创建一个与其对应的节点,相当于注册。nimbus 在提交topology是会创建一个根路径/storm/workerbeats/$topology_id,不会设置数据。
箭头6表示worker需要获取数据的路径/storm/assignments/$topology_id,worker获取到数据并根据取到的信息执行。
箭头8表示worker在localState中保存心跳信息,localState实际上每隔几秒将心跳信息保存到本地文件中,worker和supervisor属于不同进程,通过本地文件来传递心跳。
4、executor
executor只会利用zookeeper来记录自己的运行报错信息,会保存到以下目录
/storm/errors/$topology_id/$component_id/$sequential_id