PREFIX_TREE(HBASE-4676)是HBase 0.96版本中新增加的一种DataBlock Encode算法。
1.什么是PREFIX_TREE
关于前缀树的介绍可以参考维基百科http://zh.wikipedia.org/wiki/Trie
当然其的实现会有差别
2.HBase中的DataBlock
DataBlock是KeyValue的集合,是Hfile中存储数据的结构体,可以搜索Hfile了解之
3.什么是DataBlock Encode
DataBlock Encode是HBase 0.94版本引入的特性,可以将重复的row/family/qualifier/进行压缩,减少block的空间占用,提高内存使用率,可以通过http://zjushch.iteye.com/blog/1585066了解更多
4.PREFIX_TREE提升从DataBlock中查找数据的效率
在没有PREFIX_TREE之前,无论是否开启DataBlock Encode,都是按照KeyValue的排序,将其一条条顺序地写入到Block中,所以从block中查找数据,只能采用遍历的方式。而开启了PREFIX_TREE后,DataBlock中的数据存储不再是简单的将KeyValue按照顺序进行堆压,而是按照特有的方式进行组织,可以在解析时生成前缀树,并且树节点的儿子是排序的,所以从block中查找数据,其效率至少在二分查找以上。
5.作者提供的DataBlock查找性能对比
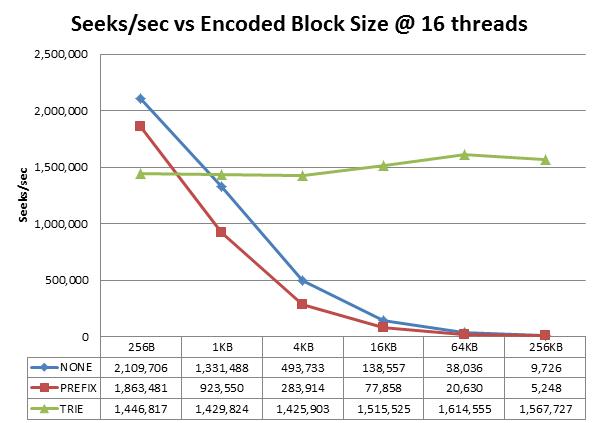
说明:
1.作者没有指出单条KV的平均大小
2.NONE 指的是不启用DataBlock Encode;PREFIX指的是PREFIX Encode算法;TRIE才是前缀树block压缩算法。
3. 前缀树压缩算法在不同的block size下查找性能都很稳定,而NONE和PREFIX由于是用遍历的方式查找数据,所以查找性能随着blocksize直线下降。对于我们默认的64K的block大小,性能相差40+倍
4.NONE比PREFIX算法性能好,是由于PREFIX算法需要解压
6.HBase中的PREFIX_TREE结构
PREFIX_TREE会分别对KeyValue中的row family qualifier形成三颗树,以Row为例,插入aa、aac、bb、bc、bc的过程如图
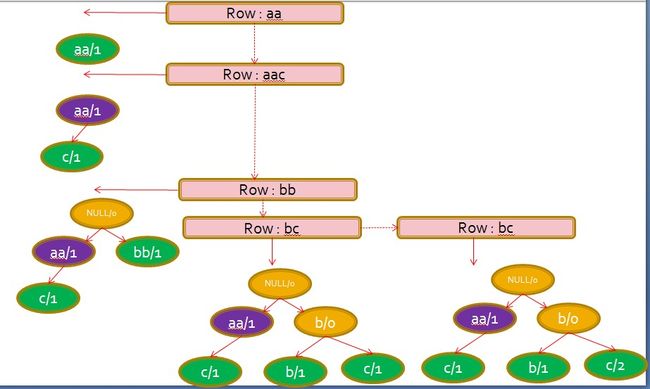
树上的节点分为3类:
branch(黄色): 内部节点,不代表实际数据,必定含有子节点
leaf(绿色):一个叶子节点,没有子节点,代表着实际数据
nub(紫色):branch与leaf的混合,既代表了实际数据,又含有子节点
节点中的数字代表该节点对应的实际数据的数目,如果一个row下有多条KeyValue,那么每条KeyValue对应的qualifier、family、timestamp等都会在encode时进行记录
7.Encode/Decode
PREFIX_TREE的encode算法,相对而言比较复杂,简单地说,它会按顺序向Block中写入ptBlockMeta、所有的row、所有的family、所有的qualifier、所有的timestamp、所有的value。可以看出,这与之前按照keyvalue顺序写入的block结构有很大的不同。 ptBlockMeta里面维护了decode时重建树结构所需要的元数据,以及一些为了压缩所需要的数据。整个encode/decode的过程还是直接看代码为好。
8.实际性能测试
测试环境:
16核CPU,HBase-0.94 version,单客户端200线程,单regionserver,BlockCache命中率100%
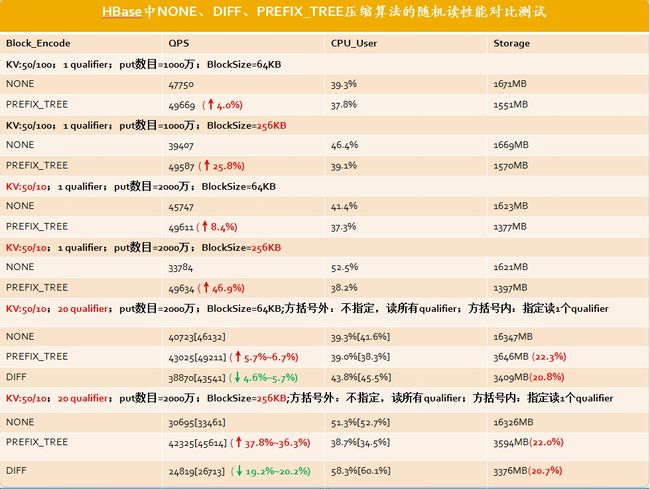
说明:
1.在加大BlockSize后,开启PREFIX_TREE,QPS基本无变化,而对于NONE/DIFF而言,QPS影响很大
2.PREFIX_TREE的空间压缩效果接近于DIFF算法
3.DIFF/FAST_DIFF等block encoding算法是以CPU计算换取空间,在不计较空间的情形下,即命中率都为100%,那么开启DIFF/FAST_DIFF,相比于NONE,其性能是反而会下降的,从测试case看大概有5%~20%的下降
个人结论:
PREFIX_TREE在压缩空间的基础上又可以减少CPU,不仅可以取代其他block encoding算法了,像是PREFIX、DIFF、FAST_DIFF都可以退役了,足以成为标配
9.适用场景
a.随机读(Get)
b.一Row多qualifier
c.Key/Value 很小
d.除了scan场景有待测试外,其实对于所有的随机读场景,都可以开启,因为副作用小于正作用(DIFF/FAST_DIFF算法,对于数据无法压缩的场景,会加重CPU,带来副作用)
10.More
之前的顺序存储的Block结构下,逆序scan十分困难(只有后继,没有前继指针),而PREFIX_TREE则可以支持逆序scan,等0.96发布PREFIX_FREE普及后,相信逆序scan功能随之而来