【数据压缩】Huffman编码
1. 数据压缩编码概述
数据压缩在日常生活极为常见,平常所用到jpg、mp3均采用数据压缩(采用Huffman编码)以减少占用空间。编码\(C\)是指从字符空间\(A\)到码字表\(X\)的映射。数据压缩编码指编码后信息的长度较于原始信息要短。本文试图探讨Huffman编码是如何保证唯一可译性、如何压缩、以及压缩效率如何?
前缀码
前缀码的任意一码字均不为其他码字的前缀,此保证了编码的唯一可译性。比如码字表{0, 01, 11, 1},0为01的前缀,1为11的前缀;当遇到字符文本011100,是应分隔为01-11-0-0还是0-11-1-0-0等?若采用前缀码编码,码字表为{0, 10, 11},则字符文本011100可即时分隔为0-11-10-0可译,所以前缀码亦被称为即时码。同时,前缀码保证了编码的唯一可译性,即字符空间\(A\)到码字表\(X\)的映射为一一映射。本文探讨的Huffman编码即为前缀码。
根据码字长度,编码分为等长编码与变长编码。等长编码即字母表中所有码字的长度均相等,最为常见的是字长7位的ASCII码。变长编码则是码字的长度可能存在不相等。
前缀码可表示为叶子节点为码字的编码二叉树,如图所示。
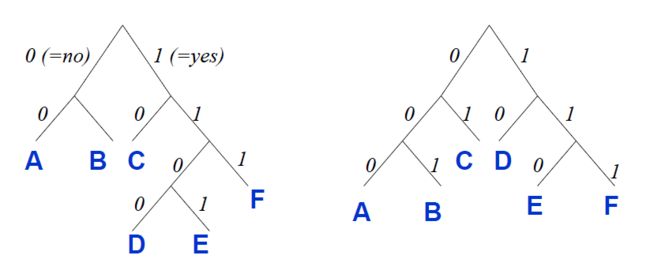
期望编码长度
如上图所示的两种变长编码,哪一种编码压缩效率比较好?显然,若信息编码之后的长度越小,则编码的压缩效率越好。为此,我们引出刻画量度期望编码长度。
首先我们定义字符空间\(A = \lbrace a_1,a_2, \cdots ,a_n \rbrace\),即信息文本中有n个字符,且字符\(a_i\)的长度为\(l_i\),出现频率(即概率)为\(p_i\);则期望编码长度为
\[ L = \sum\limits_{i = 1}^n {p_i*l_i} \]
若要期望编码长度\(L\)越小,学过数学的都知道,则高概率的码字字长应不长于低概率的码字字长,即满足
\[\forall i,j \ \ \ p_i \ge p_j \Leftrightarrow l_i \le l_j\]
最优编码
对于二元编码(01)的前缀码,满足McMillan-Kraft不等式
\[\sum\limits_{i = 1}^n {{2^{ - l_i}}} \le 1\]
具体的证明参看[3]。McMillan-Kraft不等式从整体上限制编码长度的下界。
如下图所示的前缀码即满足McMillan-Kraft不等式。
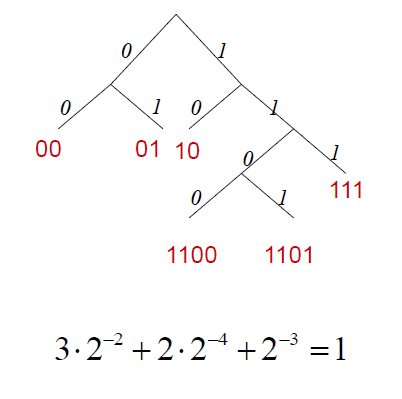
最优编码指期望编码长度最小的编码,求解最优编码等价于数学问题:
\begin{align}
& \min \sum\limits_{i = 1}^n {{p_i}*{l_i}} \cr
& s.t. \ \sum {{2^{ - {l_i}}}} \le 1 \label{eq:kraft}
\end{align}
运用拉格朗日乘子法,构造目标函数
\begin{equation}
J = \sum {p_i*l_i + \lambda (\sum {{2^{ - l_i}}} } )
\end{equation}
对\(l_i\)求偏导,
\[{{\partial J} \over {\partial l_i}} = p_i - \lambda {2^{ - l_i}}\ln 2\]
令偏导为0,得到
\[{2^{ - l_i}} = {{p_i} \over {\lambda \ln 2}}\]
将其代入McMillan-Kraft不等式\eqref{eq:kraft}中,得到\(\lambda = {1 \over {\ln 2}}\),最优编码的码字长度
\begin{equation}
l_i = - \log _{2}p_i
\end{equation}
最优编码的期望码字长度即为字符空间的熵:
\begin{equation}
\sum\limits_{i} {p_il_i = - \sum\limits_{i} {p_i \log p_i} } = H(A)
\end{equation}
由此,定义编码的冗余度(Redundancy of a code),表示编码的冗余描述:
\begin{equation}
\rho = L - H(A)
\end{equation}
可以证明,前缀码的编码长度满足不等式
\begin{equation}
H(A) \le L \le H(A) + 1
\end{equation}
因此,前缀码的冗余度满足\(0 \le \rho \le 1\)。
2. Huffman编码
Huffman编码采用小顶堆来优化编码二叉树的建立过程,确保低概率的码字字长不短于高概率的码字,具体编码过程如下:
- 将字符空间的字符以概率为关键值建立小顶堆;
- 依次取堆顶元素两次,将该两个字符合成一棵二叉树,根节点的关键值为两个字符的概率相加;然后将该新合成的二叉树做为节点插入到小顶堆中;
- 重复步骤2直至小顶堆中只有一个节点,此节点即为编码二叉树。
编码二叉树建立过程如图所示
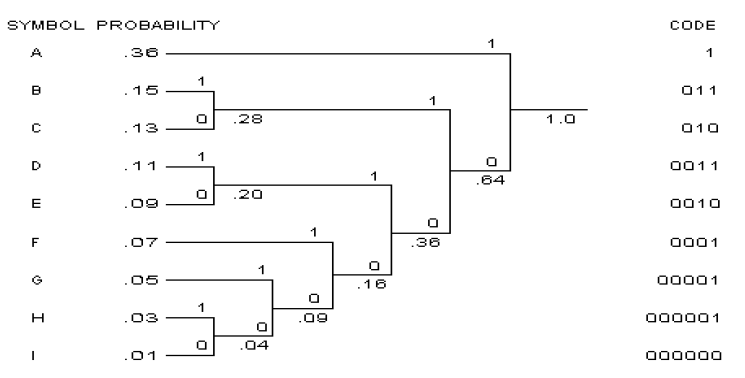
此字符空间有9个字符,采用等长编码则需要\(4\) bit;Huffman编码的期望字长则为\(2.77\) bit;字符空间的熵为\(2.69\) bit;冗余度为\(2.77-2.69=0.08\) bit.
关于Huffman编码的Python实现,请参看[4]。
3. 参考资料
[1] DAVID A. HUFFMAN, A Method for the Construction of Minimum-Redundancy Codes.
[2] Bernd Girod, EE398A Image and Video Compression.
[3] Cover T M, Thomas J A, Elements of Information Theory, 2nd edition[J].
[4] rosettacode, Huffman_coding#Python.