JDBC处理器和BeanShell取样器的组合应用
序言:
一日做性能测试,遇到一个页面上的数据提取,一开始想着用正则表达式不就提取出来了。后来仔细一想不对,单一提取貌似还能凑合,动态不定个数的提取,又是拼接的,正则貌似写不出来,即使能写出来估计也是恶心的要死。仔细一看,这不就是数据库里面的东西吗?直接从数据库里查不就完了。遍寻各种处理器后发现,还真有个JDBC处理器貌似可以研究研究,经过一段时间的尝试,总算把这块整明白了。
对照一开始的需求,这不就是写个SQL查出数据,再将查询结果拼接在一起不就完了吗?绕了这么大一圈。业务不熟害死人。
一开始就只在JDBC处理器上钻牛角尖,希望写一个SQL就把问题解决,由于是多行,多列的数据组合,搞了半天也没搞出来,差点就放弃。后来经同事点醒,上一个BeanShell取样器不就结了,巴拉巴拉说了一下使用方法,总算明白过味儿来。研究了半天,总算把问题圆满解决。现在记录一下,省得老年痴呆记不住。废话不多说,开搞。
JDBC处理器
为保证说明的完整性,还是从JDBC连接配置一步一步来说吧。还是以HyperPacer为例。首先,先加一个JDBC连接配置,见下图:

配过数据库连接的同学们也不用多说,一个一个字段写上就行了。连接池名称稍微说一下,就是给这个数据库连接命个名,将来调用的时候好做区分,比如要发起多个不同数据库的JDBC请求的话,这块就显出用途来了,一会儿用到了再讲。连接池配置这种高级功能如果没啥特殊需求,就直接默认。后面的测试数据库连接就是在用的时候先试试能不能连上,貌似用处不大。另外一个要说的就是无论JDBC的连接配置在哪个节点下配的,它都可以在同一场景下全局使用。为避免重名引发的混乱,建议将所有的JDBC连接放在一处,方便管理。
连接配置好后,就该写SQL了,这块有两种选择:一个是JDBC预处理器,一个是JDBC后置处理器。两个功能上差不多,简单说就是一个在发送请求前执行,一个在发送请求后执行。这块貌似对当前处理的问题影响不是太大,就没做详细研究,待将来有时间再做细致研究。这块拿JDBC后置处理器做范例,见下图:
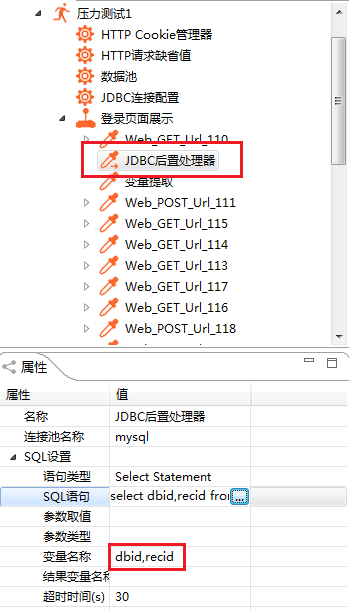
连接池名称:就是刚才配置的JDBC连接配置中写的那个名称。
语句类型:就是要执行哪种类型的语句,此次需要的就是写一个查询sql,所以就直接用默认的Select Statement。如果有跑到某个请求后需要更新数据库的,貌似就可以用用Update什么的,没有调查,没有发言权。
SQL语句:就是直接把写好的SQL粘过来就行,由于这块没有加语法检查,最好是在外面调试好后再粘过来,避免因为拼写错误什么的影响后续处理。
变量名称:就是针对查出来的数据给每一列一个别名。后面针对每一列数据进行引用的时候就要用到此处指派的名称。多列的用逗号隔开,还是那句老话,尽量用有意义的名称来命名变量,别跟老谭的C语言似的,到哪都是abc这种单个字母。(貌似暴露年龄了,呃!)剩下的几个参数暂时没用到,也就没去细究,待将来有空再来死磕。时间紧,任务重,你懂的。
这里配置好后,变量就能直接用了。比如要查询结果中第一行的recid,就可以写vars.get("recid_1"),第二行的dbid,就可以写vars.get("db_2")。可是咱要的是将多行进行拼接,更可恶的是不确定行数,这块就需要BeanShell显身手了。转下一个问题,BeanShell怎么玩儿?
BeanShell取样器
一开始不知道BeanShell是个什么东东,经同事一讲才知道,这才是真Java Script(注意空格),基本上Java能怎么写的东西,这里就能怎么来。
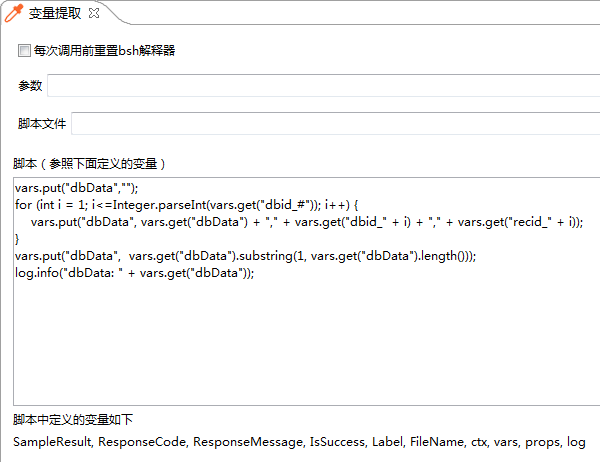
于是按照需求,在下面的框框里面,写下这么一段代码:
1 vars.put("dbData",""); 2 for (int i = 1; i<=Integer.parseInt(vars.get("dbid_#")); i++) { 3 vars.put("dbData", vars.get("dbData") + "," + vars.get("dbid_" + i) + "," + vars.get("recid_" + i)); 4 } 5 vars.put("dbData", vars.get("dbData").substring(1, vars.get("dbData").length())); 6 log.info("dbData: " + vars.get("dbData"));
技术上倒是没什么难点,就是有几个要(keng)注(le)意(wo)的地方,简单拎出来说一说。HyperPacer沿用了JMeter的变量配置方式,通过put设置变量,通过get获取变量。由于需要字符串拼接,懒癌末期,不想去研究StringBuffer那一堆东西。直接上String的连接。
和Java一样,对象要赋初值,若是直接用一个没赋初值的变量去连接的话,就是null转成的字符串。 (第一行)
因为是逐行数据连接,所以要上for循环。和java基本上一致,因为行号是从1开始的,所以i的初值是1。终止条件这里变成了Integer.parseInt(vars.get("dbid_#"))这么个恶心的东东,dbid_#是通过sql查询出来的dbid变量的个数。貌似是因为通过vars的get方法得到的都是字符串,所以要转成整型再用(要是动态语言就省事了)。(第二行)
循环体内部,通过指定的i,便可以对sql查出的不同行的数据依次进行连接了。"recid_" + i就是查询结果中recid列对应的第i行的数据。字符串连接就没啥好说的了,和Java是一样一样的。(第三行)
因为一开始有个多余的逗号乱入(为什么呢?你猜?),所以要取从第二个字符起的剩下的字符串再赋值回来。(第五行)
为了确保正确性,打印一下做个校验。JMeter里面的打印不是System.out.println()这种,要写long.info(),常用JMeter这算是基础知识了吧。(第六行)
至此相关的配置全部结束,在BeanShell取样器后面的所有的元件就都可以通过 vars.get("dbData")获取到了。
至于参数,脚本文件什么的配置,还是有机会再做研究吧,已经耗费不少时间了。
总结经验就是:工欲善其事,必先利其器。工具的掌握和灵活使用,才能使工作开展的灵活高效不认死理儿。