Windows x86 下的 静态代码混淆
0x00 前言
静态反汇编之王,毫无疑问就是Ida pro,大大降低了反汇编工作的门槛,尤其是出色的“F5插件”Hex-Rays可以将汇编代码还原成类似于C语言的伪代码,大大提高了可读性。但个人觉得“F5插件”只能作为一项辅助手段,在结合动态调试和静态分析之后,了解了整个函数的流程再利用F5看“C语言”代码才是最佳的手段。而这篇文章就是学习如何手写”花指令“,来干扰ida的静态分析和”F5插件“。
0x01 反汇编引擎
反汇编引擎就是将二进制程序翻译成了汇编的工具。主流的反汇编算法主要是两种:线性扫描反汇编和递归下降反汇编。
线性扫描算法是将一条指令的结束作为另一条指令的开始,从第一个字节开始,以线性模式扫描整个代码段,逐条反汇编每天指令,直到完成整个代码段的分析。主要优点是可以覆盖程序的所有代码段,但是却没有考虑到代码中可能混有的数据,容易出错。
递归下降算法依据程序的控制流,根据一条指令是否被另一条指令引用来决定是否对其进行反汇编。例如遇见条件跳转指令,反汇编器从true或者false两个分支处选择一个进行反汇编,如果是正常的代码,反汇编器优先选择true分支或者false分支,输出的汇编代码并没有任何区别,但是在遇见人工编码的”花指令“后,同一块代码的两个分支经常会产生不同的反汇编结果。当冲突时,反汇编器会优先选择信任的分支,而大多数面向程序控制流的反汇编器会首先选择false分支。
更多的具体关于反汇编引擎的介绍请参考看雪论坛的文章:
《各种开源引擎,反汇编引擎的对比》 :http://bbs.pediy.com/showthread.php?p=1401094#post1401094
0x02 欺骗“F5” Hex-Rays

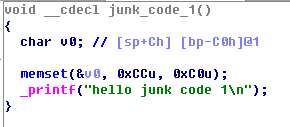
简单的”push+ret”组合(和jmp一样)根本不能骗过ida ,很轻易的就被f5还原出了”C语言”。而多出来的memset()函数是f5将编译器自动开辟栈的空间的代码还原了。
我们继续变化,将”push+ret”组合换成另一种形式:

结果令人有点失望,还是被f5直接还原了。

那我们继续修改,向下跳转后再向上跳转,ida会不会以为是循环?


好像是成功了,欺骗了ida的f5。但是稍微看一眼汇编代码就很容易看出这个循环跳转

但通过以上的例子可以总结出ida f5插件的一些特性:
(1)对于jmp指令的分析完全没有问题
(2)“push+ret”指令的组合直接当成jmp处理
(3)向下跳转再向上跳转,会认为是循环
(4)对于手动通过寄存器将值置于栈上的分析能力较弱,但简单的还是可以直接分析出。
之前都是在函数内部跳转,也可以改变跳转的方式,做函数间的长跳转。


而点进去saveregs会发现是这样的

很好,看来又成功欺骗了f5插件。但是读汇编代码会发现

双击进入_next,还是被发现了我们的真正的代码。
![]()
0x03 针对反汇编引擎
之前都是用跳转指令来迷惑”F5”插件,那可不可以让运行的结果和ida分析的汇编完全不同呢?这里我们就需要插入一些机器码来迷惑反汇编引擎,比如经常会用到在代码中间插入一些数据,让ida无法对数据和代码进行有效的区别,最普通的就是0xE8,因为这是call指令的第一个字节。
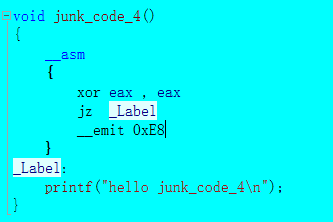
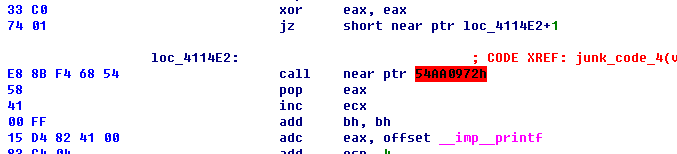
当”f5”还原时,弹出对话框,显示无法”Decompilation”。

反汇编的结果显示将0xE8作为call指令的第一个字节解释,然后成为了一个call指令,但是ida已经标注出为红色了,有经验的人一看就知道这块代码是被”加花”了的.
主要这里的xor eax , eax 和jz这两句,这本就是个跳转,为什么不直接写成jmp呢?因为之前说到过的面向控制流的反汇编引擎的策略是遇见jmp直接跳转,0xe8就会就被识别,这里人为的写成“条件跳转”,以此来达到混淆的目的。机器码的插入方法有很多,但一些机器码既可以作为前一条指令的结尾,又可以作为下条指令的开始,比如说刚刚的e8指令,尽量不要用在CPU可以执行的地方,不然很容易让程序崩溃。我们可以来看稍微复杂的指令插入

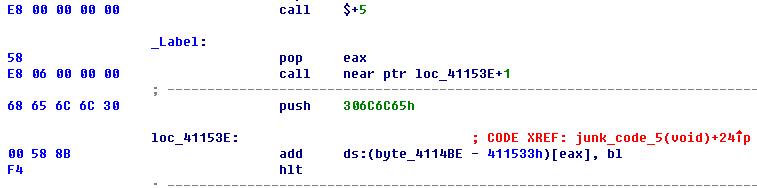
可以看到ida的分析结果有点令人失望,”f5”之后也没什么用。
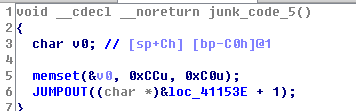
我们可以借助更多的机器码达到欺骗ida的目的

反汇编的汇编代码:

这里ida将0x66 0xb8识别为mov指令的前两个字节了,然后导致之后的分析错误。而在0xe8的中间还可以加入大量的其它花指令。
0x04 SEH
SEH 结构化异常处理,这里就不多做介绍了,可以阅读之前的文章Windows x86 SEH 学习,需要说明的是编译器实现的SEH和普通的不一样。


0x05 破坏栈帧分析
Ida试图分析一个函数来确定其栈帧结构,特别是遇到ret/retn就认为到达一个函数结尾,因此很容易伪造栈帧来阻止静态分析。给之前的代码加上一个ret 0xff

Ida f5 的结果,认为有63个参数。

还有就是在函数中改变esp的值:比如说这里的"cmp esp,0x1000",后面的"add esp , 0x102"是永远不会执行的,在这里可以改变esp,也可以做其他的很多混淆手段。

最后f5显示栈帧已经被破坏了,是不是很熟悉,和之前在函数中调用pop,eax的结果一样,都显示栈帧已经被破坏了。

0x06 小结
列举了非常基本的几种针对ida 和 f5插件的混淆代码,虽然很基础,但是可以将非常非常多的混淆代码进行叠加,形成庞大的”花指令”,花指令的目的就是增加分析的成本。编写混淆代码最重要的一点就是堆栈平衡。如果对于代码混淆,保护做更进一步学习,可以加入GitHub上的开源项目 WProtect 利用”虚拟机技术”来保护代码,也可以学习LLVM相关的知识,利用LLVM IR来保护代码。关于汇编的分析,个人还是觉得不能太依靠ida和Hex-Rays插件,要自己先动态走一遍流程,熟悉整个框架以后再借助ida 和"F5"插件来提高效率。
参考资料:
《IDA Pro 权威指南》
《恶意代码分析实战》
《加密与解密》