通过亚马逊电影评论的数据包抓取电影名称---Perl多线程同步及DBI编程
原创博客,转载请联系博主!
题外话:perl文档大部分都是英文,而且很少有完整中文的使用手册,希望我的perl代码可以帮助喜爱perl且希望进步的人!
读这篇文章你可以了解:
1.Perl多线程同步并行的几种方法及实现
2.Perl与mysql/mariadb的通信
3.如何利用Perl处理串的优势,直接快速锁定HTML文档中的目标,避免庞杂的HTML树结构搭建过程
你也会同时了解到以下的Perl编程技巧:
(1)利用perl的内置哈希结构迅速实现“去重”
(2)滑窗法/栈法实现线程并行
(3)分段法实现线程并行
(4)如何解决can't locate object method '_uric_escape'..报错
(5)如何利用HTML::TreeBuilder创建一个完整描述一份HTML文档的数据结构
任务目标:
这其实是斯坦福大学计算机专业的一次课程作业:http://snap.stanford.edu/data/web-Movies.html
在以上的链接中的 movies.txt.gz 文件大小为3G左右,解压后的电影评论有9G左右,我们需要做的事情就是围绕这个解压后的movies.txt文件中的内容而展开的!
先大概介绍下具体要做的是什么事情:
1. 首先需要从movies.txt文件中扫描出来所有的叫做productId的字符串,这里有一个去重的过程,再导入数据库,文件中的格式大致是这个样子的。
product/productId: B00006HAXW
review/userId: A1RSDE90N6RSZF
review/profileName: Joseph M. Kotow
review/helpfulness: 9/9
review/score: 5.0
review/time: 1042502400
review/summary: Pittsburgh - Home of the OLDIES
review/text: I have all of the doo wop DVD's and this one is as good or better than the 1st ones. Remember once these performers are gone, we'll never get to see them again.Rhino did an excellent job and if you like or love doowop and Rock n Roll you'll LOVE this DVD !!
2. 扫描得到的productId(如上例中的 B00006HAXW)和一个(http://amazon.com/dp/)前缀组合起来会成为一个指向一份亚马逊电影商品的HTML资源的URL(http://amazon.com/dp/B00006HAXW),我们需要在这份HTML文档中抓到电影的名字,不同的productId还有可能指向名字相同的电影名,有的相同的电影也有可能在网页上的名字不同(例如:Film 和 Film:director..actor..[VHS]),最后统计并且得到所有电影的名字。
技术铺垫:
(1)Perl-DBI-mysql简单搭建 #Perl-DBI其实真正实践并没有使用,不想看的朋友可以直接忽略
使用Perl-DBI的原因是为了处理更大规模的数据,甚至达到硬盘规模的数据。这里只是一个数据存放位置的区别,由于本次需要处理的数据最大初始规模就是9G+,所以可以交付给文件系统处理,甚至可以直接放入内存之中(虚拟内存),事实上在后面统计效率的时候就是直接在内存之中进行处理的,好我们先假设数据规模大到文件系统无法处理,开始使用DBI进行数据处理,我们的表的格式很简单:
drop table TestTable; create table TestTable( id int primary key auto_increment, name varchar(200) not null );
其实表的结构中,可以直接用name用来做为主键,这样的话就间接完成了一个去重的过程(数据库主键不能重复)。在Perl-DBI中我们需要使用到两个模块,如果没有安装,windows下请使用ppm安装,linux下直接使用cpan客户端进行安装。
use DBI; use DBD::mysql;
创建和mysql数据的互联,只需要如下一句perl脚本:
1 my $ddesc="DBI:mysql:test:127.0.0.1:3306"; 2 my $usr="root"; 3 my $passwd="jinmin"; 4 5 my $dbh=DBI->connect($ddesc,$usr,$passwd,{RaiseError=>0,PrintError=>1}) or die "Cannot Open Database!";
所有的sql数据操作语句包括“增删改查”,下例不妨就使 my $sql="select * from testtable where testtable.id=?";
1 my $stmt=$dbh->prepare($sql); 2 3 $stmt->execute(1) or die "Cannot Prepare SQL Statement!";
执行完之后,调用$stmt对象的fetchrow_array方法会返回一个引用数组包含所有的查询结果!在执行完所有的数据操作之后就可以断开连接,用以下代码做收尾工作:
1 $dbh->disconnect();
(2)Perl-多线程编程及并行处理
说到Perl多线程就不得不说到线程间互斥并行,而Perl对多线程的支持确实不够强大,而且中文文档也非常少,所以以下介绍几种比较常见的实现perl线程互斥实现多线程并行的策略。
0. perl内置的多线程支持
Perl内置关键字async来实现多线程互斥,但是这里的多线程更多的指的是外部解释命令行的fork或者c程序中的fork函数,这样在脚本顺序执行的时候到达用async包裹的程序块就可以使其互斥地进入从而避免一些错误,这有点类似于java中的synchronized关键字,顺便带上一个我写的一个简单多线程并行的实现样例脚本:http://files.cnblogs.com/files/guguli/multi_thread_concurrency.rar
(这一段是个人的经验没有深入考究,没有兴趣请忽略)Perl另外一个关键字的组合也可以用来就是state和shared关键字,使用之前需要如下的声明:
1 use feature qw/state/; 2 use threads::shared;
具体的使用在上一个链接的压缩文件中的脚本中有体现!
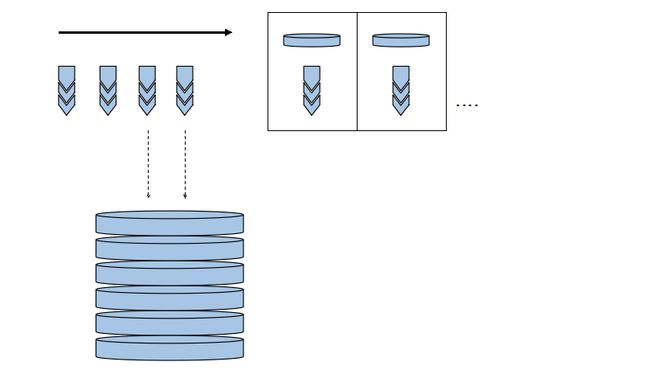
1. 滑窗法/栈法实现多线程并行
栈法的实现非常简单,实质就是维持一个全局的栈,由于perl中内置支持的数组,又由于shift/unshift和push/pop,使得间接内置支持了队列和栈结构,整个栈法的结构大概如下图所示:
滑窗法的实现相对复杂一点,但是用户是最广的,复杂到波普分析之中的滑窗算法,到TCP协议栈中的TCP滑窗包处理,在perl的多线程实现中使用滑窗法的结构大概如下图所示:

使用滑窗法可以从以下几个方面相对栈法进行改进:
a. 防止有某一个线程阻塞,夸张假设有一个线程等待函数调用返回而阻塞的,而其他线程没有阻塞的情况下,会导致图中的“窗宽越来越大”,处理的数据高度不同步,再假设有若干个线程“永远“阻塞的情况下,会使得线程池中的线程越来越小,线程上限不变的情况下阻塞死的线程越多则实际工作的线程数量就越少。
b. 在滑窗法的支持下,可以实现多线程同步写入文件这个过程!(什么?多线程同步写入文件多简单?这还用讲?)其实,实践之后就会发现,perl中的多线程共享变量:shared是不可以给文件句柄使用的,所以在perl中同时处理文件的应该是这样实现的,多线程时设置共享一个数组/哈希结构,在多线程代码调用的时候,对一个全局共享的数组/哈希结构进行增删处理,然后单独设立一个处理一个数据结构的线程(最好是主线程)来进行文件IO操作。具体实现细节这里我就不体现了,有兴趣的朋友欢迎留言。
2.分段法实现多线程并行
这种方法的原理也非常清晰,就是将数据结构(一般按长度)拆分为若干个小型的数据结构,每一个线程创建的时候接收到的参数,就是这个分段后的数据组,然后分别对其进行处理,原理大致如下所示:
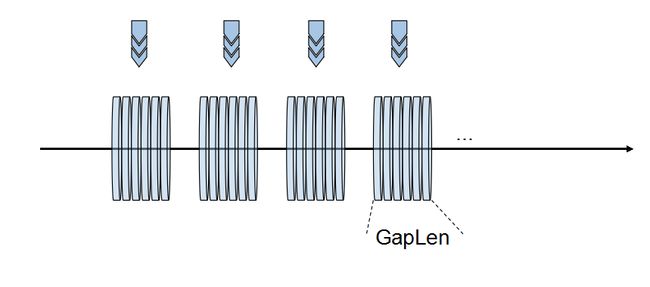
与之前算法不同的是,分段法过程"不存在循环",我们要做的事将整个数据分好的段直接交付给线程,线程创建之后就直接进入阻塞等待线程结束的join方法。
(3)Perl正则匹配HTML
这里应该是perl开发学习者用起来应该最有底气的一段,大多数情况下解析静态HTML文档的过程是将HTML代码解析为树节点,然后进行一次遍历找到符合条件的节点。这种方法在perl中应该使用HTML::TreeBuilder模块,一次简单的代码实现如下:
1 use warnings; 2 use diagnostics; 3 4 use HTML::TreeBuilder; 5 use LWP::Simple; 6 use Data::Dumper; 7 8 use utf8; 9 10 my $html=LWP::Simple::get("https://www.amazon.com/dp/B003AI2VGA"); 11 12 print $html; 13 14 my $tree=HTML::TreeBuilder->new; 15 16 $tree->ignore_ignorable_whitespace(0); 17 $tree->parse ($html); 18 $tree->eof(); 19 20 #Scanning HTML Tree 21 22 sub untag_html{ 23 my $html=shift; 24 return $html unless ref $html; 25 26 my $text=''; 27 for my $item (@{$html->{"_content"}}){ 28 $text.=untag_html($item); 29 } 30 return $text 31 } 32 33 binmode STDOUT,":utf8"; 34 35 print &untag_html($tree);
上述代码中的每个树节点都是一个哈希引用,其中的'_tag'键代表该标签的名字,而'_content'键是代表这个标签包夹的内容,另外有'attr'代表标签的属性,也是一个哈希引用,具体使用这里也不详谈。
对于本次任务目标,目前我想到最好的办法是抓取<html>下的<head>中的一个<div>标签,既然我们使用的是perl,何必麻烦?直接匹配正则吧!
抓取movies.txt中的productId /.+productId:\s+(\S+) /x
抓取一个粗略的电影名字的范围 /<meta name="title" content="(.*)"/
有的电影名字前面可能多一个前缀'Amazon.com:'也可能有个后缀'[VHS]' /Amazon.com:\s*(.*?):/ /(.*?)\s*\[VHS\]/
由于perl对于正则的强大支持,几乎每一份html是几毫秒就可以分析得到,最后可以几乎可以完满在亚马逊的电影商品中抓取到电影名字。
运行结果及效率分析
1. 不知为何在windows上跑perl脚本的速度远远慢于在linux上的速度,Linux上执行差不多可以节约5到6倍的时间,可能是因为windows对于多线程的支持不够全面吧?
2. 在实践中,我使用的是栈法实现多线程并行,这样平均2~3分钟可以处理完1000个的URL-HTTP请求。
3. 在多线程中使用LWP::Simple模块的get方法的时候会报一个can't locate object method '_uric_escape'..报错(大概字面上是这样),解决的办法其实目前没有的,根本原因还是LWP::Simple模块对于多线程的支持不够理想,但是补救的办法有一个,也是在google上论坛深处发现的--在创建线程方法之前加一句'sleep 1'语句就可以让这个错误消失!
具体的代码,我过几天会提交到github上面,因为自己还要进行一些地方的优化。之前想要看的朋友请留下你们的邮箱,我会马上回复!