0 bug 读后感
本书全名是 《
0 bug-
C/C++商用工程之道》,这是一本有争议的书,豆瓣链接:
http://book.douban.com/subject/4149139/ ,建议有一些商用的开发经验后再去阅读本书。
不过本书的标题有点诱人,相信作者在实战中也积累了一些干货,所以准备阅读一下,并且结合自己的经验总结一下里面的部分思想。
嵌入式设备
对于嵌入式设备的特性,应该在运行的时候保护自身,因为自己资源有限,像网络上的路由器这种设备,通常需要处理大量的数据并且做一些转发等操作。在此期间,路由器的内存可能会被占满,当有新数据来的时候,需要将其丢弃,不然的话机器就挂掉了。所以说这一笔业务失败不算bug,应该是系统资源太少导致的。举个例子,家用路由器不能放在核心网上面,不然Throughput会大大下降,因为处理能力有限,为了提高性能应该购买较高端的设备。对于类似的驱动代码,在cortex-m3上和x86平台上相比,肯定是x86平台能够得到的性能比较高,在cortex这种低功耗平台上面能够得到的wifi的Throughput就只能满足基本需求,因为其处理性能有限,内存也有限,没法alloc到一个大的buffer来处理数据,就算buffer很大,由于cpu的处理速率限制,也会达到一个处理的瓶颈。
在TCP的层面上来看,因为lwip在cortex设备上开辟的buffer有限,所以TCP宣告的窗口也受限制。
线程
线程可能在运行的时候申请资源或者在做一些操作(比如在写文件),一般不要去kill线程,对于外部的ctrl+c也要做好信号的捕获。在线程运行的时候一般会设置一个变量表明是否要继续线程的loop。其他线程给这个线程发消息或者将这个变量设置为false来停止线程。
线程在运行的时候需要强制释放一下时间片。对于FreeRTOS来说,一个高优先级的线程(task)如果一直在运行,不释放时间片,其他线程就无法运行。一个典型的例子就是优先级反转问题(低优先级的线程获得了资源,高优先级的线程死循环来等待资源,这时候只有高优先级的任务在运行,这样就造成了死锁)。
线程之间的通信可以使用socket,因为不仅仅使用起来比较方便,而且可以扩展到服务器集群,甚至可以扩展到不同的操作系统。因为机器之间的通讯使用socket也是可以的。但是在使用Qt做开发的时候,我发现使用信号-槽机制也能很好的通信,主要还是根据特殊的环境选择通信机制。
这个是有待探讨的,可能是作者的操作系统环境有这个限制:(不要一下子开大量线程,否则线程没法被schedule)
本人没有做过这样的应用,一般的高并发服务器应用才会有这样的需求,需要真机测试、long run才能得出结论。
对BUG做好防御
在程序里面需要做一些防御性的设计,就算遇到了bug,也能及时暴露出来。这种做法我也是深深受益。举一个linux kernel的例子:

这里当出现问题的时候就会调用panic,如果没有这样的设计的话,也许在系统运行的时候会直接花屏,而无从debug。
单元测试
如果一下子把代码全部都写好了,再使用,那么可能会有很多bug,因为许多函数流程的组合在自己的测试中可能不会被执行到,但是实际运行的时候可能会遇到,所以做好函数的单元测试可以有效地避免bug。
FOR循环
之前在其他书上也看到过,对于for循环,尽量使用这样的策略:
for (i = 0; i < MAX; i++) {
/* do something */
;
}
这里的i的左边界是0,右边界是MAX-1,对于常见的数组来说正好是这样遍历的,
而且数组的大小是MAX,一目了然。
goto 语句
虽然goto语句是洪水猛兽,可以让代码跑飞,但是合理使用它还是有用的。举一个linux kernel的例子( do_page_fault函数)
:

这里有很多标签,可以让程序阅读起来比较方便。但是使用goto的时候不能随心所欲地跳,作为
error handle还是有用的。因为程序员的脑力是有限的,如果不用goto,可能函数会比现在复杂地多。
增加函数的可读性可以大大解放程序员的思维。
指针的禁忌
指针的星号最好不要出现两个以上,我实际在阅读代码过程中也没有发现这样的问题,如果要引用两次的话,应该需要再声明一个变量。
指针不要参与运算。两个指针可能属于两个进程空间,所以减出来的数值是没有意义的。
内存问题
系统默认的字符串处理函数可能会产生内存问题,自己可以封装一个safe版本的,或者
采用现成的代码。(比如这个:http://c.biancheng.net/cpp/html/641.html)
调用内存申请和释放可能会有内存泄露等问题,自己封装一个内存统计模块,在你的程序和操作系统API之间,可以有效地了解当前是否有内存泄露。不过这个应该有现成的解决方案,不用自己写代码。
变量名、函数名
因为在开发过程中不见得会写很多注释,对于变量名字和函数名字要尽量写清楚,避免别人在看你的代码的时候非常疑惑。对于缩写,最好给一个注释,不然想破脑袋也猜不出这个变量意味着什么。
举一个简单的例子:
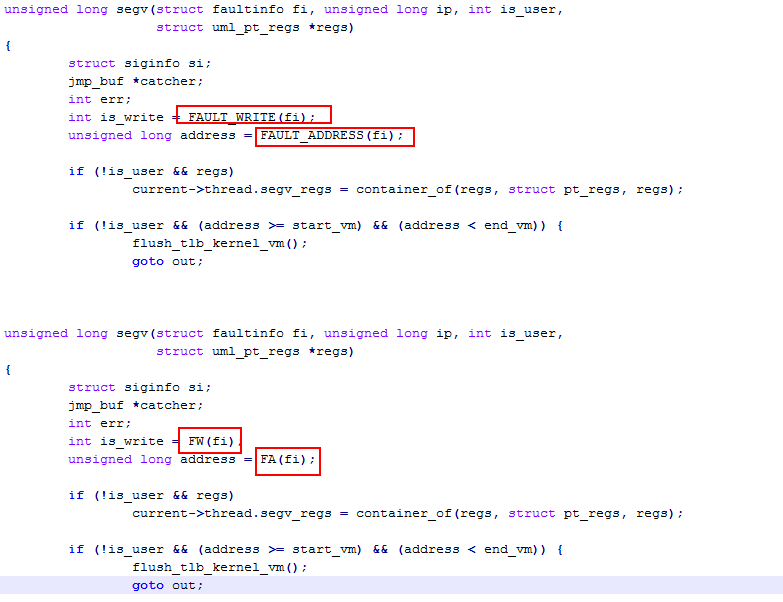
代码风格
代码要是写的简单,别人看起来也会很开心。代码要是一团乱麻,可能会遭人咒骂,而且出了问题很难debug。乱糟糟的代码会让整个团队的效率大大下降,除非是你自己一直维护这一个模块。
尽量避免代码行数过多的函数,用一些小函数代替,这样虽然降低了效率,但是后期维护的方便性超越了这里牺牲的效率,而且可以用inline来建议编译器来提高效率。
每一个变量不要用做其他用途,比如你计算一个sum,sum又用来存储当做平均值和标准差,这样会让人摸不着头脑而且容易出问题。
加锁解锁的代码要让人看得清楚,这两个动作之间的代码要简洁清晰,如果中间的代码太多,可以考虑
封装成一个函数,这样可以减小bug出现的几率。如果有可能,尽量不要用锁,因为锁是没办法才用的,而且会降低运行效率。
写程序要先写出功能,再优化, 避免到之后自己的代码变的很复杂而难以调试。
函数参数
参数过多的时候,尽量使用结构体来实现(当然是对于c语言来说的)
随便在linux kernel里面截取一下,这里不多说了:
语言高级特性
作者在使用C++的时候说明尽量使用聚合,不用重载。实际上作者的意思可能是扬长避短,使用自己熟悉的东西,对于容易用出问题的一些特性避免使用。而且作者提到,一些嵌入式设备的编译器可能无法支持一些C++的高级特性。
在linux kernel的设计中,结构体内将其他的结构体聚合起来也是常见的,随便举个例子:

重复造轮子
在文中作者有不少代码是和现成的技术类似的,比如作者提到的内存池管理技术,我觉得和linux内核的slab分配器的思想比较像,作者实现的读写锁也有现成的API。不过因为作者强调跨平台的应用,我觉得应该是作者对于跨平台的需求比较强烈,所以不使用现成的库,而是用自己测试好稳定的库用在所有平台上面,这样可以达到自己的需求。但是如果常年在一种平台上面开发,我觉得还是使用现成的、不断更新的高性能库比较适合。总的来说还是以需求做导向。
来自为知笔记(Wiz)