CNN for NLP (CS224D)
斯坦福课程CS224d: Deep Learning for Natural Language Processing
lecture13:Convolutional neural networks -- for sentence classification
主要是学习笔记,卷积神经网络(CNN),因为其特殊的结构,在图像处理和语音识别方面都有很出色的表现。这里主要整理CNN在自然语言处理的应用和现状。
一、RNNs to CNNs
学过前面lecture的朋友,应该比较清楚。RNNs一般只能获得符合语法规则的短语的向量,对于RecursiveNN,需要依赖parser将句子进行解析,获得语法树结构,而对于RecurrentNN,需要依赖前面的词来获得短语向量,可以认为训练过程将句子的语义压缩在最后的词向量中(个人理解)。
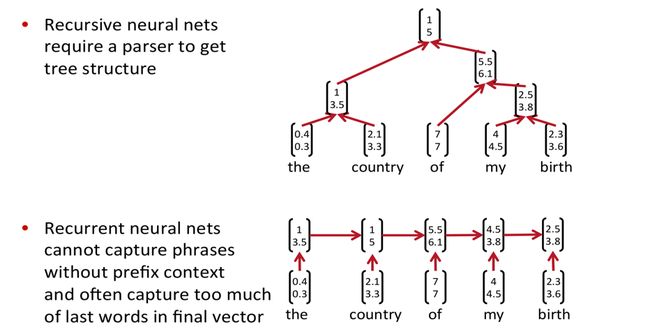
而CNN考虑的是能否为所有可能的短语组合生成向量,不在乎是否符合语法,自然也就不需要parser。比如“The country of my birth”,计算所有可能出现的短语的向量:the country、country of、of my、my birth、the country of、country of my、of my birth、the country of my、 country of my birth。
二、CNN
1. 什么是Convolution(卷积)?
数学上定义的卷积:函数f 与g 的卷积记作,它是其中一个函数翻转并平移后与另一个函数的乘积的积分,是一个对平移量的函数。
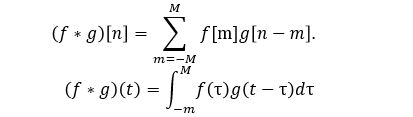
个人对于一维变量的卷积是这么理解的,可以认为是多项式系数乘积。例如f(x)=(x^2+3x+2), g(x)=(2x+5), 则f(x)对应系数向量(2,3,1),g(x)对应(5,2),f(x)与g(x)卷积可认为是系数向量不断内积,对g(x)向量做个翻转后不断左移,与f(x)重叠部分向量做内积。

在图像处理中,对图像用一个卷积核进行卷积运算,实际上就是一个滤波过程。例如下图,绿色表示输入的图像,可以是一张黑白图片,0是黑色像素点,1是白色像素点。黄色就表示滤波器(filter),也叫卷积核(kernal)或特征检测器(feature detector)。通过卷积,对图片的像素点进行加权,作为这局部像素点的响应,获得图像的某种特征。
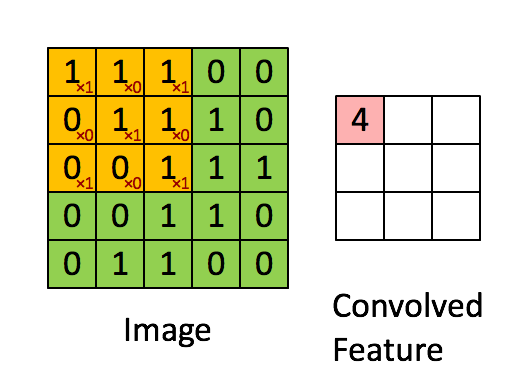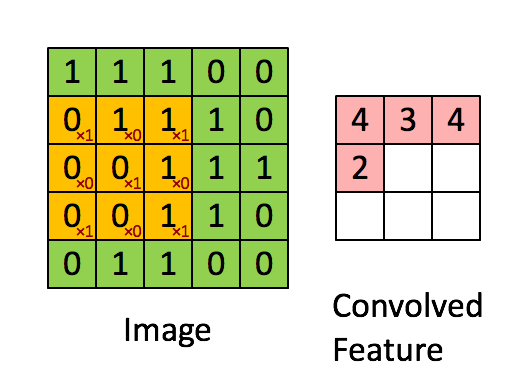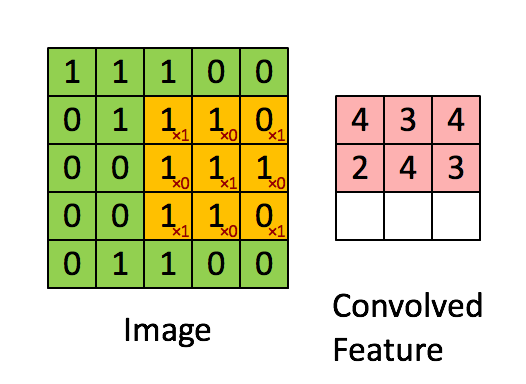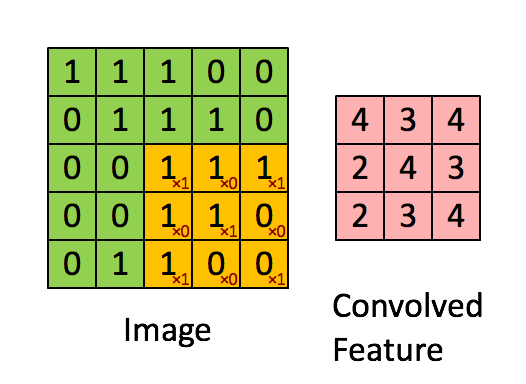
http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
举个例子:上图中输入的绿色矩阵表示一张人脸,黄色矩阵表示一个眼睛,卷积过程就是拿这个眼睛去匹配这张人脸,那么当黄色矩阵匹配到绿色矩阵(人脸)中眼睛部分时,对应的响应就会很大,得到的值就越大。(粗俗地这么理解了)在图像处理中,卷积操作可以用来对图像做边缘检测,锐化,模糊等。
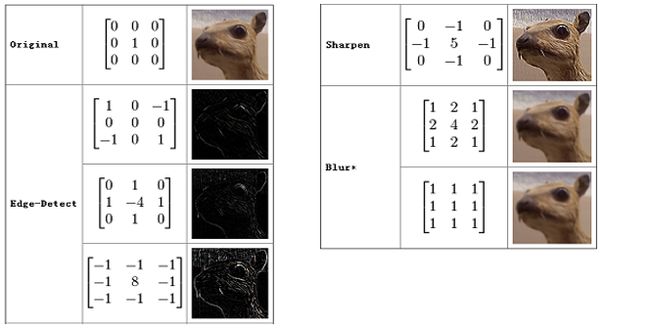
http://www.flickering.cn/ads/2015/02/语义分析的一些方法二/
2.什么是Convolutional Neural Network(卷积神经网络)?
最早应该是LeCun(1998)年论文提出,其结果如下:运用于手写数字识别。详细就不介绍,可参考zouxy09的专栏,主要关注convolution、pooling,个人理解是这样的,convolution是做特征检测,得到多个feature maps,而pooling是对特征进行筛选,提取关键信息,过滤掉一些噪音,另一方面是减少训练参数。
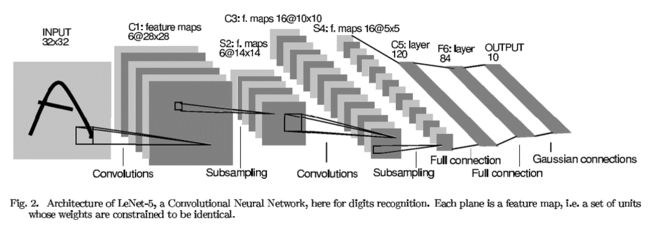
其中的Local Receptive Field 和Weight Sharing,可进一步参考:Ranzato:NEURAL NETS FOR VISION ,下图便出自此处。
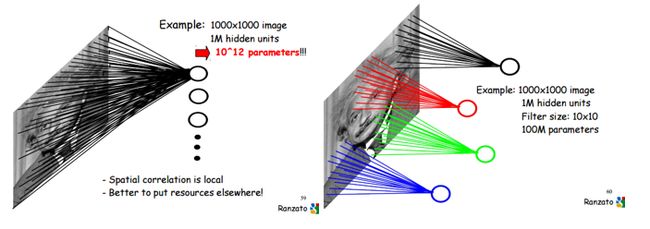
http://cs.nyu.edu/~fergus/tutorials/deep_learning_cvpr12/tutorial_p2_nnets_ranzato_short.pdf
三、CNN for NLP
1、Single Layer CNN
与图像处理不同,对于自然语言处理任务来说,输入一般是用矩阵表示的句子或文档。对于句子矩阵,每一行表示一个单词,每个词可以用向量表示(word2vec or GloVe, but they could also be one-hot vectors)。下面介绍一种简单的cnn结构,一层convolution+一层pooling。来自Yoon Kim(2014)的论文。
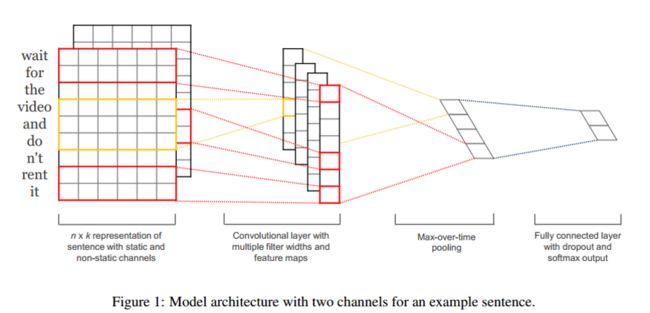
首先做一些符号说明:输入是词向量Xi(长度是k),句子向量Xi:n是词向量的级联(拼接成长向量),filter是w,可看出一个滑动窗口,这里的w是向量,长度是hk(滑动窗口包含h个词)。
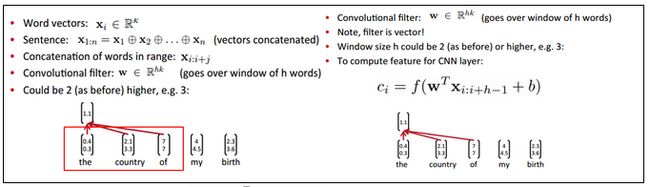
Convolution:卷积操作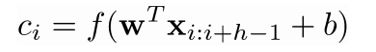 ,f是激活函数,ci表示卷积得到的特征。通过滑动filter w,与句子所有词进行卷积,可得到feature map
,f是激活函数,ci表示卷积得到的特征。通过滑动filter w,与句子所有词进行卷积,可得到feature map 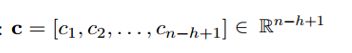

Pooling:使用max-pooling获得feature map中最大的值,然后使用多个filter获得不同n-grams的特征。
Multi-Channel:这里很有意思,输入句子时,使用两个通道(channel,可以认为是输入copy一份),都用word2vec初始化,其中一个词的向量保持不变(static),另一个是non-static,在BP过程不断修改,最后再pooling前对两个通道得到的卷积特征进行累加。
Classification:通过pooling,得到句子最后的特征向量![]() ,然后直接用softmax进行分类。
,然后直接用softmax进行分类。
另外还有一些Tricks:Dropout 和 Regularization,应该是Hinton(2012)提出的方法。

Training: BP,SGD,ADADELTA: an Adaptive Learning Rate Method.(M.Zeiler.2012)
另外,网络中的hyperparameters,是训练过程,用grid search方法在dev数据集上跑出来的,并且不断记录最优参数。结果感人,7项任务中4项得到很好结果。
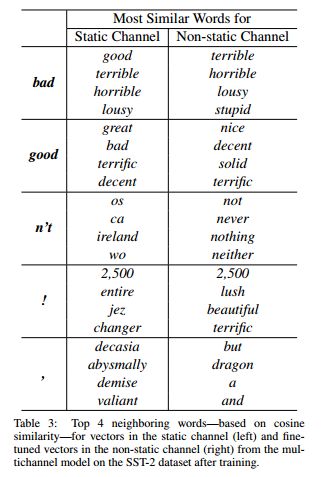
简单的cnn结构+word2vec获得很不错的结果,然后multi-channel还能学习一些相似词,比如word2vec中bad和good相似度高的问题。
2、Multi-Layer CNN
前面介绍的是单层卷积层+pooling层的CNN,下面看一个结构相对复杂一点的CNN。来自Nal Kalchbrenner (2014)的论文。文章主要提出Dynamic Convolutional Neural Network,下面只介绍一些与单层cnn不同的部分。下图是主要结构
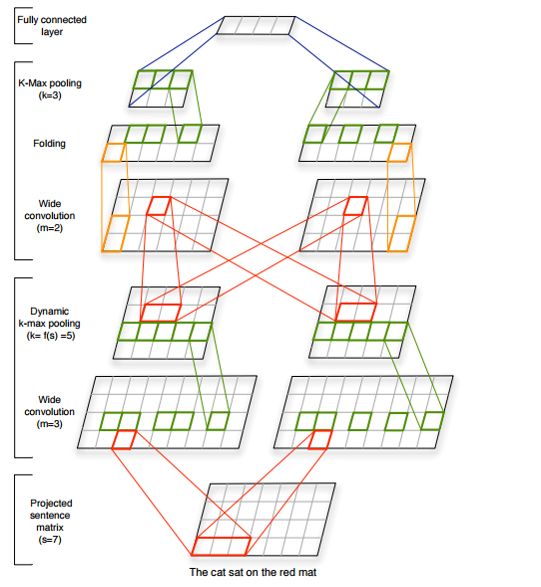
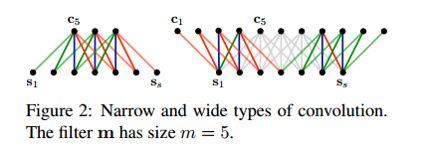
Wide Convolution:与Narrow相对而言,wide convolution指用filter m 对句子中的所有可能组合进行卷积,句子左右可以补零,从而得到比原句子长度更长的feature map,能够获得句子中词语尽可能多的不同组合。例如下图:
K-Max Pooling:与普通max-pooling取最大的feature不同,这里取最大的k个值,一定程度上保留了这些feature的顺序。

Dynamic K-Max Pooling:k的大小与卷积得到的feature map长度、以及当前pooling层数有关,公式如下:
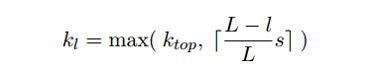
Folding:两行变一行,将同一个词的第1,2特征叠加,3,4特征叠加,我的理解是可能特征间存在某种联系,进行叠加能综合特征,又降低维数。
介绍差不过就这样,该结构不需要parse tree,而且能生成隐含的特征图,捕捉短的和长的语义关系(k-max pooling生成的树结构)。
四、目前一些研究方向
(1)卷积之前添加一层Multi-scale SUs
Wang, P., et al (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.
(2)Bag of words:
Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015
Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding.
(3)关系提取、实体识别:
Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48.
Sun, Y., Lin, L., et al. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (IJCAI), 1333–1339.
Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344.
(4)字符级别:
Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826.
Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.
Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102.
Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2015). Character-Aware Neural Language Models.
Reference
[1] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[2] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[3] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv:1207.0580, 2012.
[4] Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences[J]. arXiv preprint arXiv:1404.2188, 2014.
[5] Denny Britz (2015). Blog: understanding-convolutional-neural-networks-for-nlp
[6] @火光摇曳Flickering. Blog:语义分析的一些方法
[7] @zouxy09. Blog:Deep Learning(深度学习)学习笔记整理系列