jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——词法解析
jQuery源码9600多行,而Sizzle引擎就独占近2000行,占了1/5。Sizzle引擎、jQuery事件机制、ajax是整个jQuery的核心,也是jQuery技术精华的体现。里面的有些策略确实很值得学习,先膜拜之,然后细细学习。
在学习Sizzle引擎之前我们先准备一点知识,和先了解Sizzle引擎的一点工作原理。
<div id="chua">
<a>
<span>chua的测试用例</span>
</a>
<p class="group">
<label for="age">年龄:</label>
<input type="text" id="age" value="20" readonly/>
<p>
</div>
Sizzle引擎查找节点时CSS 选择器时一定要从右往左解析?
我们要获取for="age"的label标签,css可以这么写#chua > a + .group labe[for="age"]。
正常流程我们是先查找#chua,然后找到直接子节点中为a标签的节点,然后在找到紧跟着的class为.group的节点,最后找到子节点为label且for属性为age的节点。可以想象当节点很多的时候,选择器引擎干了半天终于找到满足前面条件的.group节点,最后发现下面的子节点没有节点为label且for属性为age的节点,一夜回到解放前,前面的工作白做的。
所以我们的想法就是:先看找到匹配最右边的css的节点(这一步已经缩小了很大范围),如果木有那么很好,到此结束,直接返回;如果存在,我再往左的css一个个匹配,反正在此过程中如果有不满足条件的我就踢掉。首先我们要肯定的是查找直接子节点我们要遍历所有子节点来匹配,而查找直接父节点则简单的多只有一个(能匹配的上就OK,不能匹配就丢掉),扩展到查找后代节点和祖先节点也是一样。所以从右往左查找快速得多。
现在进入正题
Sizzle引擎的在处理css选择器的时候有个原则:如果能使用浏览器原生的解析器来解析CSS选择器就使用之,不能的才使用Sizzle自定的解析方式来解析。可以肯定的是Sizzle引擎号称业界最快的CSS选择器解析引擎,但也快不过浏览器自带的解析器。
a.Sizzle入口,内部函数Sizzle( selector, context, results, seed )
Sizzle函数是所有解析的入口。根据代码可知。Sizzle对一些简单情况作了处理,不需要进行select解析就直接返回结果。不能使用浏览器提供的基础函数解析的才进入select函数。
大概的轮毂如下
function Sizzle( selector, context, results, seed ) { ... if ( !selector || typeof selector !== "string" ) {return results; } if ( (nodeType = context.nodeType) !== 1 && nodeType !== 9 ) {return [];} if ( !documentIsXML && !seed ) { //rquickExpr = /^(?:(<[\w\W]+>)[^>]*|#([\w-]*))$/;对于简单搜索快捷解析 if ( (match = rquickExpr.exec( selector )) ) { // Speed-up: Sizzle("#ID"),如果是ID查询的话查询直接返回结果 if ( (m = match[1]) ) { ... return results; // Speed-up: Sizzle("TAG"),如果是直接查询TAG,查询直接返回结果 } else if ( match[2] ) { ... return results; } // QSA path,如果能使用浏览器高级查询querySelectorAll if ( support.qsa && !rbuggyQSA.test(selector) ) { ... if ( newSelector ) { //使用querySelectorAll能成功查询则返回结果,否则使用select try { push.apply( results, slice.call( newContext.querySelectorAll(newSelector), 0 ) ); return results; } catch(qsaError) { } finally { if ( !old ) { context.removeAttribute("id"); } } } } } // All others return select( selector.replace( rtrim, "$1" ), context, results, seed ); } }
上面的处理可以看到有三个情况是可以直接使用浏览器自带的处理的:查询ID(getElementById)、查询TAG(getElementsByTagName)、浏览器支持高级查询querySelectorAll。其他情况进入Sizzle自定义解析方式。
我们不禁要问:为啥木有包括Class查询?说明一下,老版本的浏览器中不是所有的浏览器都支持Class查询,但是ID和TAG查询是所有浏览器都支持的。而支持使用Class查询(getElementsByClassName)的浏览器基本都支持querySelectorAll高级查询,so,不用说,用querySelectorAll即可。
b. 词法解析
Sizzle引擎解析CSS选择器的第一个步骤就是要将CSS选择器分解成一个一个单独的词,这和编译原理共通。
Sizzle的词法解析入口函数是内部函数tokenize。tokenize的作用是把CSS选择器(其实也就是一段字符串)解析成一组基础词法的序列。这个序列里面的每一个元素格式是
Token:{
value:'匹配到的字符串',
type:'对应的Token类型',
matches:'正则匹配到的一个结构'
}
Sizzle查询结果缓存机制
jQuery在词法解析函数tokenize开始解析之前用到了一个比较巧妙的地方,Sizzle把每次查询结果缓存了起来,如果下一次有相同的查询,则直接使用缓存中的查询结果,而不需要重新查询。
机制的实现:
var tokenCache = createCache(), ... function createCache() { var cache, keys = []; return (cache = function( key, value ) { // 使用 (key + " ")避免命名冲突,最大缓存Expr.cacheLength:50 if ( keys.push( key += " " ) > Expr.cacheLength ) { // Only keep the most recent entries delete cache[ keys.shift() ]; } return (cache[ key ] = value); }); } ... //设置缓存 tokenCache( selector, groups ); //tokenize函数中获取缓存 cached = tokenCache[ selector + " " ]
解析:
createCache()返回的是一个回调函数,对于这个回调函数来说cache,和keys都是他的类全局变量,在回调函数中可以直接使用。这里的巧妙在于return (cache = function( key, value )…),将cache赋值给了tokenCache,这样使本来不能在外面使用的cache变成了tokenCache,tokenCache保存的就是最新的缓存,直接调用tokenCache[key]即可访问缓存。
这里还有一个点就是return (cache = function( key, value )…)中cache先被赋值,然后被填充cache[key].如果是先填充cache[key],然后再赋值则cache会被新赋值覆盖。
tokenize函数详解
tokenize函数功能是做词法分析,步骤如下
首先,查看缓存中是否有上次同样的查询的结果,如果有则返回即可
cached = tokenCache[ selector + " " ]; if ( cached ) { return parseOnly ? 0 : cached.slice( 0 ); }
然后,判断是否还有没有等待词法分析的字符串,如果没有则返回词法分析结果并将结果缓存下来;如果还有则去掉字符串前面可能存在的的逗号和空白符(比如CSS选择器为“p , span”,词法分析完p后剩下等待分析的字符串为" , span")
//如果soFar有内容则继续进行切分,知道将选择器切存储在groups中 while ( soFar ) { //第一次执行或者开始位置有逗号 //rcomma = new RegExp( "^" + whitespace + "*," + whitespace + "*" ) if ( !matched || (match = rcomma.exec( soFar )) ) { if ( match ) { // 去除前面的逗号 soFar = soFar.slice( match[0].length ) || soFar; } //在groups中新加一个数组类型的元素来保存新的tokens groups.push( tokens = [] ); } ... }
} ... // 如果仅是解析,返回剩余的字符串长度 // 否则抛出错误或返回词法解析结果 tokens return parseOnly ? soFar.length : soFar ? Sizzle.error( selector ) : //缓存词法解析结果tokens tokenCache( selector, groups ).slice( 0 );
接着,在确认还有字符串需要解析的基础上,如果第一个字符是匹配父子兄弟选择器(">"/"+"/" "/"~"),将设置每一个词语的token属性压入tokens数组并将其从带解析的字符串sofar中剔除掉。
// rcombinators=/^[\x20\t\r\n\f]*([\x20\t\r\n\f>+~])[\x20\t\r\n\f]*/ //如果匹配父子兄弟选择器 if ( (match = rcombinators.exec( soFar )) ) { matched = match.shift(); tokens.push( { value: matched, // Cast descendant combinators to space type: match[0].replace( rtrim, " " ) } ); soFar = soFar.slice( matched.length ); }
}
然后,解析其他词语。其他词语指的是下面几类ATTR/CHILD/ClASS/ID/PSEUDO/TAG,分别对应属性/子选择器/类/ID/伪类/标签
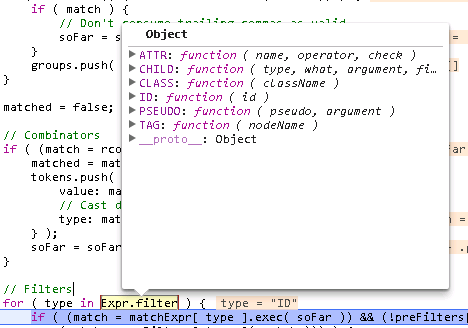
jquery有一个比较优秀的地方就是使用了很多js正则表达式,节省了很多代码,结构上也比较清晰。如下图展示的几个CSS选择器词语对应的正则
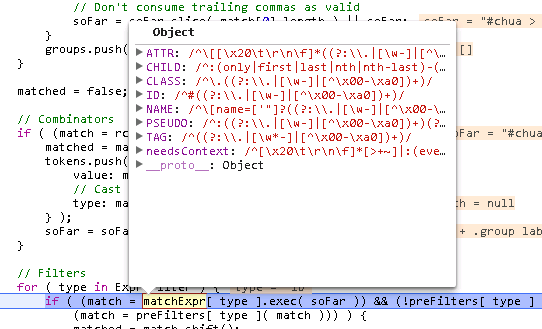
使用matchExpr[type]将每一种用到的词语匹配的结果match列出来做一下对比
["ATTR"].exec("[type='text']"): ["[type='text']", "type", "=", "'", "text", undefined]
["CHILD"].exec(":nth-of-type(2)"): [":nth-of-type(2)", "nth", "of-type", "2", "", undefined, undefined, "", "2"]
["CLASS"].exec(".chua"): [".chua", "chua"] ["ID"].exec("#chua"): ["#chua", "chua"] ["PSEUDO"].exec(":first"): [":first", "first", undefined, undefined, undefined, undefined, undefined, undefined, undefined, undefined, undefined] ["TAG"].exec("p"): ["p", "p"]
可以看出其中ATTR/CHILD/PSEUDO和另外的三种格式很不一样,为了后期便于统一处理,jQuery使用Expr.preFilter(具体的Expr.preFilter请查看源码)对这三种词语匹配的结果进行了调整,调整结果如下
match = preFilters["ATTR"]( match ): ["[type='text']", "type", "=", "text"]
match = preFilters["CHILD"]( match ): [":nth-of-type(2)", "nth", "of-type", "2", 0, 2, undefined, "", "2"] match = preFilters["PSEUDO"]( match ): [":first", "first", undefined]
匹配后将解析结果压入tokens中,并剔除已解析的词语
matched = match.shift();
tokens.push( {
value: matched,
type: type,
matches: match
} );
soFar = soFar.slice( matched.length );
好了,现在我们来看一下完成词法解析后我们得到的结果吧
以#chua > a + .group labe[for="age"]为例:

如果是多组CSS选择器如:"p > .chua , #chen input"这样使用逗号分隔的,则会得到一个二维数组[tokens1,tokens2],tokens1表示两个"p > .chua"的词法解析结果,tokens2表示 "#chen input"的词法解析结果
词法解析到此完毕。附上完整源码
function tokenize( selector, parseOnly ) { var matched, match, tokens, type, soFar, groups, preFilters, cached = tokenCache[ selector + " " ]; //查缓存 if ( cached ) { return parseOnly ? 0 : cached.slice( 0 ); } soFar = selector; groups = []; preFilters = Expr.preFilter; //如果soFar有内容则继续进行切分,知道将选择器切存储在groups中 while ( soFar ) { //第一次执行或者开始位置有逗号 //rcomma = new RegExp( "^" + whitespace + "*," + whitespace + "*" ) if ( !matched || (match = rcomma.exec( soFar )) ) { if ( match ) { // 去除前面的逗号 soFar = soFar.slice( match[0].length ) || soFar; } //在groups中新加一个数组类型的元素来保存新的tokens groups.push( tokens = [] ); } matched = false; // rcombinators=/^[\x20\t\r\n\f]*([\x20\t\r\n\f>+~])[\x20\t\r\n\f]*/ //如果匹配父子兄弟选择器 if ( (match = rcombinators.exec( soFar )) ) { matched = match.shift(); tokens.push( { value: matched, // Cast descendant combinators to space type: match[0].replace( rtrim, " " ) } ); soFar = soFar.slice( matched.length ); } //filters
////其中Expr.filter中的过滤函数目前只在matcherFromTokens中用到 for ( type in Expr.filter ) { //matchExpr包括ID, CLASS, NAME, TAG, ATTR,CHILD,PSEUDO,needsContext //等类型的正则表达式,matchExpr中属性的排列顺序是根据使用频率来排行的 //节约查找时间 //如果通过正则匹配到了Token格式:match = matchExpr[ type ].exec( soFar ) //然后看看需不需要预处理:!preFilters[ type ] //如果需要 ,那么通过预处理器将匹配到的处理一下 : match = preFilters[ type ]( match ) if ( (match = matchExpr[ type ].exec( soFar )) && (!preFilters[ type ] || (match = preFilters[ type ]( match ))) ) { matched = match.shift(); tokens.push( { value: matched, type: type, matches: match } ); soFar = soFar.slice( matched.length ); } } if ( !matched ) { break; } }
// 如果仅是解析,返回剩余的字符串长度
// 否则抛出错误或返回词法解析结果 tokens
return parseOnly ?
soFar.length :
soFar ? Sizzle.error( selector ) : //缓存词法解析结果tokens tokenCache( selector, groups ).slice( 0 );
如果觉得本文不错,请点击右下方【推荐】!