iOS中的预编译指令的初步探究
看到非常好的两篇技术文,转来方便自己查看。
转自:http://www.cnblogs.com/daiweilai/p/4234336.html
开篇
我们人类创造东西的时候有个词叫做”仿生学“!人类创造什么东西都会模仿自己来创造,所以上帝没有长成树的样子而和人长得一样,科幻片里面外星人也像人一样有眼睛有鼻子……但是人类自己创造的东西如果太像自己,自己又会吓尿(恐怖谷效应),人类真是奇葩;奇葩的我们在20世纪创造了改变世界的东西——计算机(电脑),不用怀疑,这货当然也是仿生学!这货哪里长得像人了??别不服,先听我说完,先把你的砖头放下。狭义的仿生学是外形上仿生嘛,其实广义上仿生学还可以原理的仿生,构造的仿生,性能的仿生阿拉巴拉……,计算机(这里我狭义的使用个人PC来举例)我们常说的有输入设备(键盘呀鼠标呀摄像头呀……)、处理设备(CPU、GPU……)和输出设备(显示器、音响……);然后你自个儿瞅瞅你自己的眼睛耳朵(输入),大脑(处理),四肢(输出) 当初设计电脑必须要这种构造的人难道不是瞅着自己来设计计算机的么?^_^
所以上计算机组成原理的时候有什么地方晦涩难以理解的时候,我就立刻解禁我高中的生物知识,然后就迎刃而解了~但是今天我这篇博客是要讲程序的呀,这把犊子扯的那么远看客们也难免心有愤懑,你切勿急躁,我马上就带你们飞!跟着我用仿生学的角度去理解计算机,那么计算机程序是神马呢?教科书上怎么说?可以被计算机执行,那神马东西会被人执行的呢?老婆的命令、老爸的呵斥、项目经理的需求变更……我们都会执行,貌似这就是人的程序了,这确实就是人的程序!下面我具体拿老婆的命令来详解一下人得程序的执行过程;比如老婆说了一句”你给我滚出去睡沙发!“,首先这句话的处理流程是这样的:
图1

带你们看计算机程序执行过程之前,我们要严肃的了解一点程序的编译,也就是上图中的,我们把老婆的命令转换成电信号的过程。在计算机世界中有些好事者把这个玩意儿称作编译器(compiler),什么gcc呀clang呀阿拉巴拉,说的编译器这名字逼格好高~其实说白了就是个翻译的东西,如我们人执行程序过程中,把老婆的话(也是人类的话)翻译成大脑懂的话(电波),在计算机中就是把各种编程语言(c、c++、oc……)翻译成0101011……让计算机懂。编译器的工作原理基本上都是三段式的,可以分为前端(Frontend)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree)。优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
图2

为什么要弄成这三段式的呢?我肯定不会从什么框架、结构啊优化……角度说起,因为我也不懂呀,哈哈 不过我可以讲一个过去的故事给大家,大家试想一下编译器是怎么开发出来的呀,好家伙,上网一搜LLVM编译器是C++写的,那c++的编译器呢?其实不用那么麻烦,现在把你的手借给我,让我牵着你回到上个世纪70年代,里奇正在为他新发明的C语言在写编译器呢,他在用汇编语言!汇编语言怎么编译变成二进制流呢?答案是使用01011机器码编写的编译器;所以编译器和计算机语言的进步就像这样迭代发展的,再之后是用高级语言写更高级的编译器,高级的编译器能编译更高级的计算机语言……,虽然蓝翔的挖掘机技术强,但问题还是来了,世界上计算机那么多,各种不同的架构,人还好基本架构都一样,但是计算机有Intel架构的又有ARM架构,怎么能让编程语言通过编译分别产生不同架构的执行码呢?所以这就是编译器三段式这种模型的好处了,当我们要支持多种语言时,只需要添加多个前端就可以了。当需要支持多种目标机器时,只需要添加多个后端就可以了。对于中间的优化器,我们可以使用通用的中间代码。gcc可以支持c、c++、java……等语言的编译。
图3

那么一个HelloWord的程序的编译和执行过程大家就按照图1自行脑补吧
说了这么多终于正片开始了~ 原来我的啰嗦,因为我就是叫做话痨戴^_^,本人从没有开发过Mac os的应用所以本文主要示例代码和框架都是iOS下的,但是是因为C系语言的预编译指令,所以基本都能通用。虽然这篇文章有个宏大的开端,但是本文主要就是想探究一下编译过程中的预处理部分的部分预处理指令,希望本文能够做到的就是抛砖引玉,给比我菜的广大猿友指引一条学习的方向。
在很久很久以前的Xcode不知道什么版本,Build settings里面还可以选择不同的编译器。
如图4

不同的编译器,是否对于预处理指令有差异,我也没办法考究了。还有其实、其实人家接触iOS也只有3个月,我开发iOS使用的第一个IDE就是XCode6,如果坑了大家,那就索瑞~~
现在Xcode6里面默认使用了Apple LLVM(Low Level Virtual Machine) 6.0的编译器
图5

各种编译器的区别还有几本对比知识可以参看《LLVM和GCC的区别》http://www.cnblogs.com/zuopeng/p/4141467.html
关于苹果的和gcc以及LLVM背后激情个故事看以看这个《三好学生Chris Lattner的LLVM编译工具链》http://www.programmer.com.cn/9436/
那么接下来就是正片的高潮啦——预处理指令
高潮之前再加一个预高潮^_^,干嘛要预处理呢?回去看图一,老婆说“你给我滚出去睡沙发!” 如果你没有预处理,你按照顺序运行,先滚出去了你可能还不想睡觉,你在沙发上看电视看了几个小时后才打算睡觉,这时候你发现你竟然忘了从房间拿枕头和被子出来了,你这时候就去敲老婆的门,又是一顿臭骂,之后你才能睡觉……折腾不? 如果你进行了预处理,当老婆说完指令,其中你获取到关键字“睡沙发”,不管我滚出去之后睡不睡觉,我都先从房间把被子枕头拿到沙发,这样是不是效率高了很多?同样对于C系的语言的开发,预处理可谓举足轻重,如果你阅读过优秀的C源代码,你一定看到了很多 #define #if #error …… 预编译对程序之后的编译提供了很多方便以及优化,对于错误处理、包引用、跨平台……有着极大的帮助。而且开发中使用预编译指令完成一些事情也是很屌的事情,并且你既然走上了一条改变世界的道路那么当一个有逼格的程序猿的觉悟也需要觉醒呀
文件包含
#include
这个我真的不想多说,只要你大学C语言课程不是体育老师教得话,他们肯定跟你说过#include “”、#include <>的区别,他们肯定说过#include“xxx”包含和使用#include <xxx>包含的不同之处就是使用<>包含时,预处理器会搜索C函数库头文件路径下的文件,而使用“”包含时首先搜索程序所在目录,其次搜索系统Path定义目录,如果还是找不到才会搜索C函数库头文件所在目录。
所以我不想为了弥补你老师犯下的错,我就不想重复了,有一点需要注意使用#include的时候包含文件的时候是不能递归包含的,例如a.h文件包含b.h,而b.h就不能再包含a.h了;还有就是重复包含(比如a.h包含了b.h,然后main.c中又包含了a.h和b.h)虽然是允许的但是这会降低编译性能。那该怎么办呢?1、使用#import替代include 2、使用宏判断(宏判断下面会详解),xcode很聪明,只要新建一个头文件a.h 里面就自动就生成了 图6

这个看不懂?你可以等看完#ifndef和#define之后就明白了,大概的原理就是,用宏定义判断一个宏是否定义了,如果没有定义则会定义这个宏,这样以来如果已经包含过则这个宏定义肯定已经定义过了,即使再包含也不会重新定义了,下面的代码也就不会包含进去。
#include_next
这个是非C标准库里面的预处理指令,但是Xcode中允许使用,所以也就介绍一下吧。#include_next是GNU(一群牛逼的人疯狂开源的组织,可以说是Linux的灵魂)的一个扩展,并不是标准C中的指令 例如有个搜索路径链,在#include中,它们的搜索顺序依次是A,B,C,D和E。在B目录中有个头文件叫a.h,在D目录中也有个头文件叫a.h,如果在我们的源代码中这样写#include <a.h>,那么我们就会包含的是B目录中的a.h头文件,如果我们这样写#include_next <a.h>那么我们就会包含的是D目录中的a.h头文件。#include_next <a.h>的意思按我们上面的引号包含中的解释来说就是“在B目录中的a.h头文件后面的目录路径(即C,D和E)中搜索a.h头文件并包含进来)。#include_next <a.h>的操作会是这样的,它将在A,B,C,D和E目录中依次搜索a.h头文件,那么首先它会在B目录中搜索到a.h头文件,那它就会以B目录作为分割点,搜索B目录后面的目录(C,D和E),然后在这后面的目录中搜索a.h头文件,并把在这之后搜索到的a.h头文件包含进来。这样说的话大家应该清楚了吧。
#import
OC特有的就是一个智能的#include,解决了#include的重复包含的问题。
宏定义
#define
这个使用的就太多了,个人认为是所有预处理指令中最酷的!必须要学习!这里我厚颜无耻的转载OneV’s Den的文章,他写的非常的棒!免得同学们链接跳来跳去我就直接粘贴他的文章吧,请叫我快乐的搬运工!
宏定义的黑魔法 - 宏菜鸟起飞手册
宏定义在C系开发中可以说占有举足轻重的作用。底层框架自不必说,为了编译优化和方便,以及跨平台能力,宏被大量使用,可以说底层开发离开define将寸步难行。而在更高层级进行开发时,我们会将更多的重心放在业务逻辑上,似乎对宏的使用和依赖并不多。但是使用宏定义的好处是不言自明的,在节省工作量的同时,代码可读性大大增加。如果想成为一个能写出漂亮优雅代码的开发者,宏定义绝对是必不可少的技能(虽然宏本身可能并不漂亮优雅XD)。但是因为宏定义对于很多人来说,并不像业务逻辑那样是每天会接触的东西。即使是能偶尔使用到一些宏,也更多的仅仅只停留在使用的层级,却并不会去探寻背后发生的事情。有一些开发者确实也有探寻的动力和意愿,但却在点开一个定义之后发现还有宏定义中还有其他无数定义,再加上满屏幕都是不同于平时的代码,既看不懂又不变色,于是乎心生烦恼,怒而回退。本文希望通过循序渐进的方式,通过几个例子来表述C系语言宏定义世界中的一些基本规则和技巧,从0开始,希望最后能让大家至少能看懂和还原一些相对复杂的宏。考虑到我自己现在objc使用的比较多,这个站点的读者应该也大多是使用objc的,所以有部分例子是选自objc,但是本文的大部分内容将是C系语言通用。
入门
如果您完全不知道宏是什么的话,可以先来热个身。很多人在介绍宏的时候会说,宏嘛很简单,就是简单的查找替换嘛。嗯,只说对了的一半。C中的宏分为两类,对象宏(object-like macro)和函数宏(function-like macro)。对于对象宏来说确实相对简单,但却也不是那么简单的查找替换。对象宏一般用来定义一些常数,举个例子:
//This defines PI #define M_PI 3.14159265358979323846264338327950288
#define关键字表明即将开始定义一个宏,紧接着的M_PI是宏的名字,空格之后的数字是内容。类似这样的#define X A的宏是比较简单的,在编译时编译器会在语义分析认定是宏后,将X替换为A,这个过程称为宏的展开。比如对于上面的M_PI
#define M_PI 3.14159265358979323846264338327950288 double r = 10.0; double circlePerimeter = 2 * M_PI * r; // => double circlePerimeter = 2 * 3.14159265358979323846264338327950288 * r; printf("Pi is %0.7f",M_PI); //Pi is 3.1415927
那么让我们开始看看另一类宏吧。函数宏顾名思义,就是行为类似函数,可以接受参数的宏。具体来说,在定义的时候,如果我们在宏名字后面跟上一对括号的话,这个宏就变成了函数宏。从最简单的例子开始,比如下面这个函数宏
//A simple function-like macro #define SELF(x) x NSString *name = @"Macro Rookie"; NSLog(@"Hello %@",SELF(name)); // => NSLog(@"Hello %@",name); // => Hello Macro Rookie
这个宏做的事情是,在编译时如果遇到SELF,并且后面带括号,并且括号中的参数个数与定义的相符,那么就将括号中的参数换到定义的内容里去,然后替换掉原来的内容。 具体到这段代码中,SELF接受了一个name,然后将整个SELF(name)用name替换掉。嗯..似乎很简单很没用,身经百战阅码无数的你一定会认为这个宏是写出来卖萌的。那么接受多个参数的宏肯定也不在话下了,例如这样的:
#define PLUS(x,y) x + y printf("%d",PLUS(3,2)); // => printf("%d",3 + 2); // => 5
相比对象宏来说,函数宏要复杂一些,但是看起来也相当简单吧?嗯,那么现在热身结束,让我们正式开启宏的大门吧。
宏的世界,小有乾坤
因为宏展开其实是编辑器的预处理,因此它可以在更高层级上控制程序源码本身和编译流程。而正是这个特点,赋予了宏很强大的功能和灵活度。但是凡事都有两面性,在获取灵活的背后,是以需要大量时间投入以对各种边界情况进行考虑来作为代价的。可能这么说并不是很能让人理解,但是大部分宏(特别是函数宏)背后都有一些自己的故事,挖掘这些故事和设计的思想会是一件很有意思的事情。另外,我一直相信在实践中学习才是真正掌握知识的唯一途径,虽然可能正在看这篇博文的您可能最初并不是打算亲自动手写一些宏,但是这我们不妨开始动手从实际的书写和犯错中进行学习和挖掘,因为只有肌肉记忆和大脑记忆协同起来,才能说达到掌握的水准。可以说,写宏和用宏的过程,一定是在在犯错中学习和深入思考的过程,我们接下来要做的,就是重现这一系列过程从而提高进步。
第一个题目是,让我们一起来实现一个MIN宏吧:实现一个函数宏,给定两个数字输入,将其替换为较小的那个数。比如MIN(1,2)出来的值是1。嗯哼,simple enough?定义宏,写好名字,两个输入,然后换成比较取值。比较取值嘛,任何一本入门级别的C程序设计上都会有讲啊,于是我们可以很快写出我们的第一个版本:
//Version 1.0 #define MIN(A,B) A < B ? A : B
Try一下
int a = MIN(1,2); // => int a = 1 < 2 ? 1 : 2; printf("%d",a); // => 1
输出正确,打包发布!图7

但是在实际使用中,我们很快就遇到了这样的情况
int a = 2 * MIN(3, 4); printf("%d",a); // => 4
看起来似乎不可思议,但是我们将宏展开就知道发生什么了
int a = 2 * MIN(3, 4); // => int a = 2 * 3 < 4 ? 3 : 4; // => int a = 6 < 4 ? 3 : 4; // => int a = 4;
嘛,写程序这个东西,bug出来了,原因知道了,事后大家就都是诸葛亮了。因为小于和比较符号的优先级是较低的,所以乘法先被运算了,修正非常简单嘛,加括号就好了。
//Version 2.0 #define MIN(A,B) (A < B ? A : B)
这次2 * MIN(3, 4)这样的式子就轻松愉快地拿下了。经过了这次修改,我们对自己的宏信心大增了...直到,某一天一个怒气冲冲的同事跑来摔键盘,然后给出了一个这样的例子:
int a = MIN(3, 4 < 5 ? 4 : 5); printf("%d",a); // => 4
简单的相比较三个数字并找到最小的一个而已,要怪就怪你没有提供三个数字比大小的宏,可怜的同事只好自己实现4和5的比较。在你开始着手解决这个问题的时候,你首先想到的也许是既然都是求最小值,那写成MIN(3, MIN(4, 5))是不是也可以。于是你就随手这样一改,发现结果变成了3,正是你想要的..接下来,开始怀疑之前自己是不是看错结果了,改回原样,一个4赫然出现在屏幕上。你终于意识到事情并不是你想像中那样简单,于是还是回到最原始直接的手段,展开宏。
int a = MIN(3, 4 < 5 ? 4 : 5); // => int a = (3 < 4 < 5 ? 4 : 5 ? 3 : 4 < 5 ? 4 : 5); //希望你还记得运算符优先级 // => int a = ((3 < (4 < 5 ? 4 : 5) ? 3 : 4) < 5 ? 4 : 5); //为了您不太纠结,我给这个式子加上了括号 // => int a = ((3 < 4 ? 3 : 4) < 5 ? 4 : 5) // => int a = (3 < 5 ? 4 : 5) // => int a = 4
找到问题所在了,由于展开时连接符号和被展开式子中的运算符号优先级相同,导致了计算顺序发生了变化,实质上和我们的1.0版遇到的问题是差不多的,还是考虑不周。那么就再严格一点吧,3.0版!
//Version 3.0 #define MIN(A,B) ((A) < (B) ? (A) : (B))
至于为什么2.0版本中的MIN(3, MIN(4, 5))没有出问题,可以正确使用,这里作为练习,大家可以试着自己展开一下,来看看发生了什么。
经过两次悲剧,你现在对这个简单的宏充满了疑惑。于是你跑了无数的测试用例而且它们都通过了,我们似乎彻底解决了括号问题,你也认为从此这个宏就妥妥儿的哦了。不过如果你真的这么想,那你就图样图森破了。生活总是残酷的,该来的bug也一定是会来的。不出意外地,在一个雾霾阴沉的下午,我们又收到了一个出问题的例子。
float a = 1.0f; float b = MIN(a++, 1.5f); printf("a=%f, b=%f",a,b); // => a=3.000000, b=2.000000
拿到这个出问题的例子你的第一反应可能和我一样,这TM的谁这么二货还在比较的时候搞++,这简直乱套了!但是这样的人就是会存在,这样的事就是会发生,你也不能说人家逻辑有错误。a是1,a++表示先使用a的值进行计算,然后再加1。那么其实这个式子想要计算的是取a和b的最小值,然后a等于a加1:所以正确的输出a为2,b为1才对!嘛,满眼都是泪,让我们这些久经摧残的程序员淡定地展开这个式子,来看看这次又发生了些什么吧:
float a = 1.0f; float b = MIN(a++, 1.5f); // => float b = ((a++) < (1.5f) ? (a++) : (1.5f))
其实只要展开一步就很明白了,在比较a++和1.5f的时候,先取1和1.5比较,然后a自增1。接下来条件比较得到真以后又触发了一次a++,此时a已经是2,于是b得到2,最后a再次自增后值为3。出错的根源就在于我们预想的是a++只执行一次,但是由于宏展开导致了a++被多执行了,改变了预想的逻辑。解决这个问题并不是一件很简单的事情,使用的方式也很巧妙。我们需要用到一个GNU C的赋值扩展,即使用({...})的形式。这种形式的语句可以类似很多脚本语言,在顺次执行之后,会将最后一次的表达式的赋值作为返回。举个简单的例子,下面的代码执行完毕后a的值为3,而且b和c只存在于大括号限定的代码域中
int a = ({ int b = 1; int c = 2; b + c; }); // => a is 3
有了这个扩展,我们就能做到之前很多做不到的事情了。比如彻底解决MIN宏定义的问题,而也正是GNU C中MIN的标准写法
//GNUC MIN #define MIN(A,B) ({ __typeof__(A) __a = (A); __typeof__(B) __b = (B); __a < __b ? __a : __b; })
这里定义了三个语句,分别以输入的类型申明了__a和__b,并使用输入为其赋值,接下来做一个简单的条件比较,得到__a和__b中的较小值,并使用赋值扩展将结果作为返回。这样的实现保证了不改变原来的逻辑,先进行一次赋值,也避免了括号优先级的问题,可以说是一个比较好的解决方案了。如果编译环境支持GNU C的这个扩展,那么毫无疑问我们应该采用这种方式来书写我们的MIN宏,如果不支持这个环境扩展,那我们只有人为地规定参数不带运算或者函数调用,以避免出错。
关于MIN我们讨论已经够多了,但是其实还存留一个悬疑的地方。如果在同一个scope内已经有__a或者__b的定义的话(虽然一般来说不会出现这种悲剧的命名,不过谁知道呢),这个宏可能出现问题。在申明后赋值将因为定义重复而无法被初始化,导致宏的行为不可预知。如果您有兴趣,不妨自己动手试试看结果会是什么。Apple在Clang中彻底解决了这个问题,我们把Xcode打开随便建一个新工程,在代码中输入MIN(1,1),然后Cmd+点击即可找到clang中 MIN的写法。为了方便说明,我直接把相关的部分抄录如下:
//CLANG MIN #define __NSX_PASTE__(A,B) A##B #define MIN(A,B) __NSMIN_IMPL__(A,B,__COUNTER__) #define __NSMIN_IMPL__(A,B,L) ({ __typeof__(A) __NSX_PASTE__(__a,L) = (A); __typeof__(B) __NSX_PASTE__(__b,L) = (B); (__NSX_PASTE__(__a,L) < __NSX_PASTE__(__b,L)) ? __NSX_PASTE__(__a,L) : __NSX_PASTE__(__b,L); })
似乎有点长,看起来也很吃力。我们先美化一下这宏,首先是最后那个__NSMIN_IMPL__内容实在是太长了。我们知道代码的话是可以插入换行而不影响含义的,宏是否也可以呢?答案是肯定的,只不过我们不能使用一个单一的回车来完成,而必须在回车前加上一个反斜杠\。改写一下,为其加上换行好看些:
#define __NSX_PASTE__(A,B) A##B #define MIN(A,B) __NSMIN_IMPL__(A,B,__COUNTER__) #define __NSMIN_IMPL__(A,B,L) ({ __typeof__(A) __NSX_PASTE__(__a,L) = (A); \ __typeof__(B) __NSX_PASTE__(__b,L) = (B); \ (__NSX_PASTE__(__a,L) < __NSX_PASTE__(__b,L)) ? __NSX_PASTE__(__a,L) : __NSX_PASTE__(__b,L); \ })
但可以看出MIN一共由三个宏定义组合而成。第一个__NSX_PASTE__里出现的两个连着的井号##在宏中是一个特殊符号,它表示将两个参数连接起来这种运算。注意函数宏必须是有意义的运算,因此你不能直接写AB来连接两个参数,而需要写成例子中的A##B。宏中还有一切其他的自成一脉的运算符号,我们稍后还会介绍几个。接下来是我们调用的两个参数的MIN,它做的事是调用了另一个三个参数的宏__NSMIN_IMPL__,其中前两个参数就是我们的输入,而第三个__COUNTER__我们似乎不认识,也不知道其从何而来。其实__COUNTER__是一个预定义的宏,这个值在编译过程中将从0开始计数,每次被调用时加1。因为唯一性,所以很多时候被用来构造独立的变量名称。有了上面的基础,再来看最后的实现宏就很简单了。整体思路和前面的实现和之前的GNUC MIN是一样的,区别在于为变量名__a和__b添加了一个计数后缀,这样大大避免了变量名相同而导致问题的可能性(当然如果你执拗地把变量叫做__a9527并且出问题了的话,就只能说不作死就不会死了)。
花了好多功夫,我们终于把一个简单的MIN宏彻底搞清楚了。宏就是这样一类东西,简单的表面之下隐藏了很多玄机,可谓小有乾坤。作为练习大家可以自己尝试一下实现一个SQUARE(A),给一个数字输入,输出它的平方的宏。虽然一般这个计算现在都是用inline来做了,但是通过和MIN类似的思路我们是可以很好地实现它的,动手试一试吧 :)
Log,永恒的主题
Log人人爱,它为我们指明前进方向,它为我们抓虫提供帮助。在objc中,我们最多使用的log方法就是NSLog输出信息到控制台了,但是NSLog的标准输出可谓残废,有用信息完全不够,比如下面这段代码:
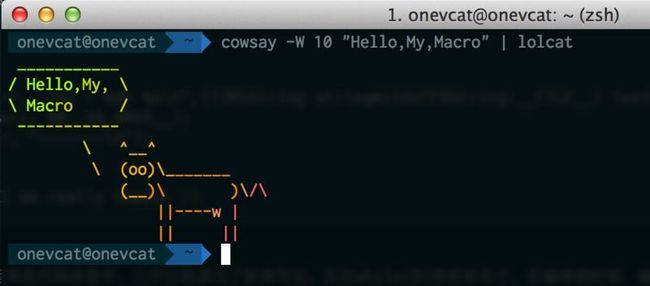
NSArray *array = @[@"Hello", @"My", @"Macro"]; NSLog (@"The array is %@", array);
打印到控制台里的结果是类似这样的
2014-01-20 11:22:11.835 TestProject[23061:70b] The array is ( Hello, My, Macro )
我们在输出的时候关心什么?除了结果以外,很多情况下我们会对这行log的所在的文件位置方法什么的会比较关心。在每次NSLog里都手动加上方法名字和位置信息什么的无疑是个笨办法,而如果一个工程里已经有很多NSLog的调用了,一个一个手动去改的话无疑也是噩梦。我们通过宏,可以很简单地完成对NSLog原生行为的改进,优雅,高效。只需要在预编译的pch文件中加上
//A better version of NSLog #define NSLog(format, ...) do { \ fprintf(stderr, "<%s : %d> %s\n", \ [[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \ __LINE__, __func__); \ (NSLog)((format), ##__VA_ARGS__); \ fprintf(stderr, "-------\n"); \ } while (0)
嘛,这是我们到现在为止见到的最长的一个宏了吧...没关系,一点一点来分析就好。首先是定义部分,第2行的NSLog(format, ...)。我们看到的是一个函数宏,但是它的参数比较奇怪,第二个参数是...,在宏定义(其实也包括函数定义)的时候,写为...的参数被叫做可变参数(variadic)。可变参数的个数不做限定。在这个宏定义中,除了第一个参数format将被单独处理外,接下来输入的参数将作为整体一并看待。回想一下NSLog的用法,我们在使用NSLog时,往往是先给一个format字符串作为第一个参数,然后根据定义的格式在后面的参数里跟上写要输出的变量之类的。这里第一个格式化字符串即对应宏里的format,后面的变量全部映射为...作为整体处理。
接下来宏的内容部分。上来就是一个下马威,我们遇到了一个do while语句...想想看你上次使用do while是什么时候吧?也许是C程序设计课的大作业?或者是某次早已被遗忘的算法面试上?总之虽然大家都是明白这个语句的,但是实际中可能用到它的机会少之又少。乍一看似乎这个do while什么都没做,因为while是0,所以do肯定只会被执行一次。那么它存在的意义是什么呢,我们是不是可以直接简化一下这个宏,把它给去掉,变成这个样子呢?
//A wrong version of NSLog #define NSLog(format, ...) fprintf(stderr, "<%s : %d> %s\n", \ [[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \ __LINE__, __func__); \ (NSLog)((format), ##__VA_ARGS__); \ fprintf(stderr, "-------\n");
答案当然是否定的,也许简单的测试里你没有遇到问题,但是在生产环境中这个宏显然悲剧了。考虑下面的常见情况
if (errorHappend) NSLog(@"Oops, error happened");
展开以后将会变成
if (errorHappend) fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__); (NSLog)((format), ##__VA_ARGS__); //I will expand this later fprintf(stderr, "-------\n");
注意..C系语言可不是靠缩进来控制代码块和逻辑关系的。所以说如果使用这个宏的人没有在条件判断后加大括号的话,你的宏就会一直调用真正的NSLog输出东西,这显然不是我们想要的逻辑。当然在这里还是需要重新批评一下认为if后的单条执行语句不加大括号也没问题的同学,这是陋习,无需理由,请改正。不论是不是一条语句,也不论是if后还是else后,都加上大括号,是对别人和自己的一种尊重。
好了知道我们的宏是如何失效的,也就知道了修改的方法。作为宏的开发者,应该力求使用者在最大限度的情况下也不会出错,于是我们想到直接用一对大括号把宏内容括起来,大概就万事大吉了?像这样:
//Another wrong version of NSLog #define NSLog(format, ...) { fprintf(stderr, "<%s : %d> %s\n", \ [[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \ __LINE__, __func__); \ (NSLog)((format), ##__VA_ARGS__); \ fprintf(stderr, "-------\n"); \ }
展开刚才的那个式子,结果是
//I am sorry if you don't like { in the same like. But I am a fan of this style :P if (errorHappend) { fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__); (NSLog)((format), ##__VA_ARGS__); fprintf(stderr, "-------\n"); };
编译,执行,正确!因为用大括号标识代码块是不会嫌多的,所以这样一来的话我们的宏在不论if后面有没有大括号的情况下都能工作了!这么看来,前面例子中的do while果然是多余的?于是我们又可以愉快地发布了?如果你够细心的话,可能已经发现问题了,那就是上面最后的一个分号。虽然编译运行测试没什么问题,但是始终稍微有些刺眼有木有?没错,因为我们在写NSLog本身的时候,是将其当作一条语句来处理的,后面跟了一个分号,在宏展开后,这个分号就如同噩梦一般的多出来了。什么,你还没看出哪儿有问题?试试看展开这个例子吧:
if (errorHappend) NSLog(@"Oops, error happened"); else //Yep, no error, I am happy~ :)
No! I am not haapy at all! 因为编译错误了!实际上这个宏展开以
后变成了这个样子:
if (errorHappend) { fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__); (NSLog)((format), ##__VA_ARGS__); fprintf(stderr, "-------\n"); }; else { //Yep, no error, I am happy~ :) }
因为else前面多了一个分号,导致了编译错误,很恼火..要是写代码的人乖乖写大括号不就啥事儿没有了么?但是我们还是有巧妙的解决方法的,那就是上面的do while。把宏的代码块添加到do中,然后之后while(0),在行为上没有任何改变,但是可以巧妙地吃掉那个悲剧的分号,使用do while的版本展
开以后是这个样子的
if (errorHappend) do { fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__); (NSLog)((format), ##__VA_ARGS__); fprintf(stderr, "-------\n"); } while (0); else { //Yep, no error, I am really happy~ :) }
这个吃掉分号的方法被大量运用在代码块宏中,几乎已经成为了标准写法。而且while(0)的好处在于,在编译的时候,编译器基本都会为你做好优化,把这部分内容去掉,最终编译的结果不会因为这个do while而导致运行效率上的差异。在终于弄明白了这个奇怪的do while之后,我们终于可以继续深入到这个宏里面了。宏本体内容的第一行没有什么值得多说的fprintf(stderr, "<%s : %d> %s\n",,简单的格式化输出而已。注意我们使用了\将这个宏分成了好几行来写,实际在最后展开时会被合并到同一行内,我们在刚才MIN最后也用到了反斜杠,希望你还能记得。接下来一行我们填写这个格式输出中
的三个token,
[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__);
这里用到了三个预定义宏,和刚才的__COUNTER__类似,预定义宏的行为是由编译器指定的。__FILE__返回当前文件的绝对路径,__LINE__返回展开该宏时在文件中的行数,__func__是改宏所在scope的函数名称。我们在做Log输出时如果带上这这三个参数,便可以加快解读Log,迅速定位。关于编译器预定义的Log以及它们的一些实现机制,感兴趣的同学可以移步到gcc文档的PreDefine页面和clang的Builtin Macro进行查看。在这里我们将格式化输出的三个参数分别设定为文件名的最后一个部分(因为绝对路径太长很难看),行数,以及方法名称。
接下来是还原原始的NSLog,(NSLog)((format), ##__VA_ARGS__);中出现了另一个预定义的宏__VA_ARGS__(我们似乎已经找出规律了,前后双下杠的一般都是预定义)。__VA_ARGS__表示的是宏定义中的...中的所有剩余参数。我们之前说过可变参数将被统一处理,在这里展开的时候编译器会将__VA_ARGS__直接替换为输入中从第二个参数开始的剩余参数。另外一个悬疑点是在它前面出现了两个井号##。还记得我们上面在MIN中的两个井号么,在那里两个井号的意思是将前后两项合并,在这里做的事情比较类似,将前面的格式化字符串和后面的参数列表合并,这样我们就得到了一个完整的NSLog方法了。之后的几行相信大家自己看懂也没有问题了,最后输出一下试试看,大概
看起来会是这样的。
------- <AppDelegate.m : 46> -[AppDelegate application:didFinishLaunchingWithOptions:] 2014-01-20 16:44:25.480 TestProject[30466:70b] The array is ( Hello, My, Macro ) -------
带有文件,行号和方法的输出,并且用横杠隔开了(请原谅我没有质感的设计,也许我应该画一只牛,比如这样?),debug的时候也许会轻松一些吧 :)图8
这个Log有三个悬念点,首先是为什么我们要把format单独写出来,然后吧其他参数作为可变参数传递呢?如果我们不要那个format,而直接写成NSLog(...)会不会有问题?对于我们这里这个例子来说的话是没有变化的,但是我们需要记住的是...是可变参数列表,它可以代表一个、两个,或者是很多个参数,但同时它也能代表零个参数。如果我们在申明这个宏的时候没有指定format参数,而直接使用参数列表,那么在使用中不写参数的NSLog()也将被匹配到这个宏中,导致编译无法通过。如果你手边有Xcode,也可以看看Cocoa中真正的NSLog方法的实现,可以看到它也是接收一个格式参数和一个参数列表的形式,我们在宏里这么定义,正是为了其传入正确合适的参数,从而保证使用者可以按照原来的方式正确使用这个宏。
第二点是既然我们的可变参数可以接受任意个输入,那么在只有一个format输入,而可变参数个数为零的时候会发生什么呢?不妨展开看一看,记住##的作用是拼接前后,而现在##之
后的可变参数是空:
NSLog(@"Hello"); => do { fprintf((stderr, "<%s : %d> %s\n",[[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], __LINE__, __func__); (NSLog)((@"Hello"), ); fprintf(stderr, "-------\n"); } while (0);
中间的一行(NSLog)(@"Hello", );似乎是存在问题的,你一定会有疑惑,这种方式怎么可能编译通过呢?!原来大神们其实早已想到这个问题,并且进行了一点特殊的处理。这里有个特殊的规则,在逗号和__VA_ARGS__之间的双井号,除了拼接前后文本之外,还有一个功能,那就是如果后方文本为空,那么它会将前面一个逗号吃掉。这个特性当且仅当上面说的条件成立时才会生效,因此可以说是特例。加上这条规则后,我们就可以将刚才的式子展开为正确的(NSLog)((@"Hello"));了。
最后一个值得讨论的地方是(NSLog)((format), ##__VA_ARGS__);的括号使用。把看起来能去掉的括号去掉,写成NSLog(format, ##__VA_ARGS__);是否可以呢?在这里的话应该是没有什么大问题的,首先format不会被调用多次也不太存在误用的可能性(因为最后编译器会检查NSLog的输入是否正确)。另外你也不用担心展开以后式子里的NSLog会再次被自己展开,虽然展开式中NSLog也满足了我们的宏定义,但是宏的展开非常聪明,展开后会自身无限循环的情况,就不会再次被展开了。
作为一个您读到了这里的小奖励,附送三个debug输出rect,size和point的宏,希望您能用上(嗯..想想曾经有多少次你需要打印这些结构体的某个数字而被折磨致死,让它们玩儿蛋去吧!当然请
先加油看懂它们吧)
#define NSLogRect(rect) NSLog(@"%s x:%.4f, y:%.4f, w:%.4f, h:%.4f", #rect, rect.origin.x, rect.origin.y, rect.size.width, rect.size.height) #define NSLogSize(size) NSLog(@"%s w:%.4f, h:%.4f", #size, size.width, size.height) #define NSLogPoint(point) NSLog(@"%s x:%.4f, y:%.4f", #point, point.x, point.y)
两个实际应用的例子
当然不是说上面介绍的宏实际中不能用。它们相对简单,但是里面坑不少,所以显得很有特点,非常适合作为入门用。而实际上在日常中很多我们常用的宏并没有那么多奇怪的问题,很多时候我们按照想法去实现,再稍微注意一下上述介绍的可能存在的共通问题,一个高质量的宏就可以诞生。如果能写出一些有意义价值的宏,小了从对你的代码的使用者来说,大了从整个社区整个世界和减少碳排放来说,你都做出了相当的贡献。我们通过几个实际的例子来看看,宏是如何改变我们的生活,和写代码的习惯的吧。
先来看看这两个宏
#define XCTAssertTrue(expression, format...) \ _XCTPrimitiveAssertTrue(expression, ## format) #define _XCTPrimitiveAssertTrue(expression, format...) \ ({ \ @try { \ BOOL _evaluatedExpression = !!(expression); \ if (!_evaluatedExpression) { \ _XCTRegisterFailure(_XCTFailureDescription(_XCTAssertion_True, 0, @#expression),format); \ } \ } \ @catch (id exception) { \ _XCTRegisterFailure(_XCTFailureDescription(_XCTAssertion_True, 1, @#expression, [exception reason]),format); \ }\ })
如果您常年做苹果开发,却没有见过或者完全不知道XCTAssertTrue是什么的话,强烈建议补习一下测试驱动开发的相关知识,我想应该会对您之后的道路很有帮助。如果你已经很熟悉这个命令了,那我们一起开始来看看幕后发生了什么。
有了上面的基础,相信您大体上应该可以自行解读这个宏了。({...})的语法和##都很熟悉了,这里有三个值得注意的地方,在这个宏的一开始,我们后面的的参数是format...,这其实也是可变参数的一种写法,和...与__VA_ARGS__配对类似,{NAME}...将于{NAME}配对使用。也就是说,在这里宏内容的format指代的其实就是定义的先对expression取了两次反?我不是科班出身,但是我还能依稀记得这在大学程序课上讲过,两次取反的操作可以确保结果是BOOL值,这在objc中还是比较重要的(关于objc中BOOL的讨论已经有很多,如果您还没能分清BOOL, bool和Boolean,可以参看NSHisper的这篇文章)。然后就是@#expression这个式子。我们接触过双井号##,而这里我们看到的操作符是单井号#,注意井号前面的@是objc的编译符号,不属于宏操作的对象。单个井号的作用是字符串化,简单来说就是将替换后在两头加上"",转为一个C字符串。这里使用@然后紧跟#expression,出来后就是一个内容是expression的内容的NSString。然后这个NSString再作为参数传递给_XCTRegisterFailure和_XCTFailureDescription等,继续进行展开,这些是后话。简单一瞥,我们大概就可以想象宏帮助我们省了多少事儿了,如果各位看官要是写个断言还要来个十多行的话,想象都会疯掉的吧。
另外一个例子,找了人民群众喜闻乐见的ReactiveCocoa(RAC)中的一个宏定义。对于RAC不熟悉或者没听过的朋友,可以简单地看看Limboy的一系列相关博文(搜索ReactiveCocoa),介绍的很棒。如果觉得“哇哦这个好酷我很想学”的话,不妨可以跟随raywenderlich上这个系列的教程做一些实践,里面简单地用到了RAC,但是都已经包含了RAC的基本用法了。RAC中有几个很重要的宏,它们是保证RAC简洁好用的基本,可以说要是没有这几个宏的话,是不会有人喜欢RAC的。其中RACObserve就是其中一个,它通过KVC来为对象的某个属性创建一个信号返回(如果你看不懂这句话,不要担心,这对你理解这个宏的写法和展开没有任何影响)。对于这个宏,我决定不再像上面那样展开和讲解,我会在最后把相关的宏都贴出来,大家不妨拿它练练手,看看能不能将其展开到代码的状态,并且明白其中都发生了些什么。如果你遇到什么问题或者在展开过程中有所心得,欢迎在评论里留言分享和交流 :)
好了,这篇文章已经够长了。希望在看过以后您在看到宏的时候不再发怵,而是可以很开心地说这个我会这个我会这个我也会。最终目标当然是写出漂亮高效简洁的宏,这不论对于提高生产力还是~震慑你的同事~提升自己实力都会很有帮助。
另外,在这里一定要宣传一下关注了很久的@hangcom 吴航前辈的新书《iOS应用逆向工程》。很荣幸能够在发布之前得到前辈的允许拜读了整本书,可以说看的畅快淋漓。我之前并没有越狱开发的任何基础,也对相关领域知之甚少,在这样的前提下跟随书中的教程和例子进行探索的过程可以说是十分有趣。我也得以能够用不同的眼光和高度来审视这几年所从事的iOS开发行业,获益良多。可以说《iOS应用逆向工程》是我近期所愉快阅读到的很cool的一本好书。现在这本书还在预售中,但是距离1月28日的正式发售已经很近,有兴趣的同学可以前往亚马逊或者ChinaPub的相关页面预定,相信这本书将会是iOS技术人员非常棒的春节读物。
最后是我们说好的留给大家玩的练习,我加了一点注释帮助大家稍微理解每个宏是做什么的,在文章后面留了一块试验田,大家可以随便填写玩弄。总之,加油!
//调用 RACSignal是类的名字 RACSignal *signal = RACObserve(self, currentLocation); //以下开始是宏定义 //rac_valuesForKeyPath:observer:是方法名 #define RACObserve(TARGET, KEYPATH) \ [(id)(TARGET) rac_valuesForKeyPath:@keypath(TARGET, KEYPATH) observer:self] #define keypath(...) \ metamacro_if_eq(1, metamacro_argcount(__VA_ARGS__))(keypath1(__VA_ARGS__))(keypath2(__VA_ARGS__)) //这个宏在取得keypath的同时在编译期间判断keypath是否存在,避免误写 //您可以先不用介意这里面的巫术.. #define keypath1(PATH) \ (((void)(NO && ((void)PATH, NO)), strchr(# PATH, '.') + 1)) #define keypath2(OBJ, PATH) \ (((void)(NO && ((void)OBJ.PATH, NO)), # PATH)) //A和B是否相等,若相等则展开为后面的第一项,否则展开为后面的第二项 //eg. metamacro_if_eq(0, 0)(true)(false) => true // metamacro_if_eq(0, 1)(true)(false) => false #define metamacro_if_eq(A, B) \ metamacro_concat(metamacro_if_eq, A)(B) #define metamacro_if_eq1(VALUE) metamacro_if_eq0(metamacro_dec(VALUE)) #define metamacro_if_eq0(VALUE) \ metamacro_concat(metamacro_if_eq0_, VALUE) #define metamacro_if_eq0_1(...) metamacro_expand_ #define metamacro_expand_(...) __VA_ARGS__ #define metamacro_argcount(...) \ metamacro_at(20, __VA_ARGS__, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1) #define metamacro_at(N, ...) \ metamacro_concat(metamacro_at, N)(__VA_ARGS__) #define metamacro_concat(A, B) \ metamacro_concat_(A, B) #define metamacro_concat_(A, B) A ## B #define metamacro_at2(_0, _1, ...) metamacro_head(__VA_ARGS__) #define metamacro_at20(_0, _1, _2, _3, _4, _5, _6, _7, _8, _9, _10, _11, _12, _13, _14, _15, _16, _17, _18, _19, ...) metamacro_head(__VA_ARGS__) #define metamacro_head(...) \ metamacro_head_(__VA_ARGS__, 0) #define metamacro_head_(FIRST, ...) FIRST #define metamacro_dec(VAL) \ metamacro_at(VAL, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19) //调用 RACSignal是类的名字 RACSignal *signal = RACObserve(self, currentLocation);
源地址是http://onevcat.com/2014/01/black-magic-in-macro/
OneV’s Den大大还有很多很棒的文章哟~~~
附上那头小牛
#define NSLog(format, ...) fprintf(stderr, "<%s : %d> %s\n", \ [[[NSString stringWithUTF8String:__FILE__] lastPathComponent] UTF8String], \ __LINE__, __func__); \ (NSLog)((format), ##__VA_ARGS__); \ fprintf(stderr, "\n ------------------\n/ Hello David Day! \\\n\\ my Macro Log ~ /\n ------------------\n \\\n \\ ^__^\n (OO)\__________\n (__)\\ )\\/\\\n ||_______ _)\n || W |\n YYy ww ww\n");
图9

#undef
当你使用了#define宏定义后,则在整个程序的运行周期内这个宏都是有效的,但有时候我们在某个逻辑里希望这个宏失效不想使用,则会使用
#define NetworkOn //定义一个宏,如果该宏定义了,则在应用里使用网络 -(void)closeNetwork{//突然发生意外的情况,网络无法使用了,调用该方法,取消NetworkOn的宏定义 #undef NetworkOn }
条件编译
#if #else #endif
#if就和我们常用的条件语句的if使用方式一样,#if的后面跟上条件表达式,后面跟上一个#endif表示结束#if,虽说这玩意儿简单,但是用的好,对于某些取巧的工作特别容易实现。比如你现在有这样的需求,我的程序平时调试模式的时候需要打印一些log,但是发布模式的应用就不用再打印log了,怎么办?很多人就说发布的时候吧log语句一句一句的删除呗~ 那客户发烂咋说你写的东西是狗屎让你修改,所以你又要回来调试,当你调试的时候你菊花肯定一紧,以前的调试语句因为过于自信在发布的时候全都删除了,又想不到发布后又被要求修改~,有基友就说了,那就不删除log语句呗,反正是打印到控制台的信息,用户又看不到~,果然没有安全意识,企业开发不是学雷锋,不用把你的所有log都写在日记本,有时候你的软件被破解的原因就是因为你的调试信息出卖了你。安全意识不可无,不然老王替你生孩子~~~~~。
怎么做呢?
//swift语言 #if DEBUG func dlog<T>(object: T) { println(object) } #else func dlog<T>(object: T) {} #endif
DEBUG是xcode的预定义的宏,这个东西多的很呢,要慢慢挖掘呢。 以后打印log你都只使用dlog()这个函数,如果你是在调试模式的时候就会打印,否则就不会打印了。
其他例子:
判断是否开启ARC,有些库需要ARC支持,则在编译之前可以判断用户有没有开启ARC
#if !__has_feature(objc_arc) //如果没有开启ARC这里可以做一些错误处理 比如: #error "啊 啊 啊~ 伦家需要ARC" #endif
同样__has_feature(objc_arc)这玩意儿也是xcode预置的 , 前缀是这个的"__"都是预定宏;
又比如,对不同版本的os系统做策略
#if __IPHONE_OS_VERSION_MIN_REQUIRED < __IPHONE_7_0 //如果iOS版本低于7.0,这里可以干一些事情
#endif
又或者判断设备类型
#define IS_IPAD (UI_USER_INTERFACE_IDIOM() == UIUserInterfaceIdiomPad) #if IS_IPAD //这台设备是IPAD呀~~~~ #else //这货是IPhone #endif
这个东西简单但是很常使用,正所谓IF在手,天下我有 哈哈哈
#if define #ifdef #ifndef #elif
#if define = #ifdef
#if !define = #ifndef
#elif = "else if"
错误、警告处理
#error
如果编译器遇到这货,马上就会罢工。再说Xcode的错误纠正功能这么强大,所以几乎不可能在编译过程中遇到#error了,所以说这货没用?非也~,我们是受过高等教育的高材生,我们要懂得辩证观点还要了解价值定理!任何事物都有存在的价值的。虽说今天的IDE很好很强大,#error似乎没什么用了~但是还有有一群猿类孤高冷傲,隐居山林,他们鄙视一切IDE,他们坚信Notepad就是他们的屠龙宝刀……
对于这些虚幻飘渺的程序猿们,他们还是需要#error来给他们预报编译前的错误的。我们说点有价值的,如果非要用#error,那在我们当下的开发中怎么用?
现在#error还是有用的,尤其是你在开发一个库的时候,这个库的使用需要一定的条件,如果不满足这个条件,你就不让使用者编译。这样不就可以使用#error啦嘛
#if !__has_feature(objc_arc) #error "我的低调不是你装逼的资本!这个库需要开启ARC,不然你别用!" #endif
那么如果用户没有开启ARC就无法进行编译了,因为xcode看到#error就不编译了,在这里只有开启了ARC,#error才会不见。
#warning
这个用法很简单,只要后面跟上你想警告的话就OK了,这样你就可以让编译器提醒这个警告。图10

如果你在Xcode中设置了,图11

如果你设置成Yes,那么你的waring就等于error,编译不了的哦。
请再次叫我快乐的小搬运工~ 又是他 ---->Onev's Den写的东西,我就是喜欢他,怎么样怎么样?
谈谈Objective-C的警告
一个有节操的程序员会在乎自己的代码的警告,就像在乎饭碗边上有只死蟑螂那样。 ——@onevcat
重视编译警告
现在编译器有时候会很吵,而编译器给出的警告对开发者来说是很有用的信息。警告不会阻止继续编译和链接,也不会导致程序不能运行,但是很多时候编译器会先你一步发现问题所在,对于Objective-C来说特别如此。Clang不仅对于明显的错误能够提出警告(比如某方法或者接口未实现),也能对很多潜在可能的问题做出提示(比如方法已经废弃或者有问题的转换),而这些问题在很多时候都可能成为潜在的致命错误,必须加以重视。
像Ruby或者PHP这样的动态语言没有所谓的编译警告,而C#或者Java这类语言的警告很多都是不得不照顾的废弃方法什么的,很多开发者已经习惯于忽略警告进行开发。OC由于现在由苹果负责维护,Clang的LLVM也同时是苹果在做,可以说从语言到编译器到SDK全局都在掌握之中,因此做OC开发时的警告往往比其他语言的警告更有参考价值。打开尽可能多的警告提示,并且在程序开发中尽量避免生成警告,对于构建一个健壮高效的程序来说,是必须的。
在Xcode中开启额外警告提示
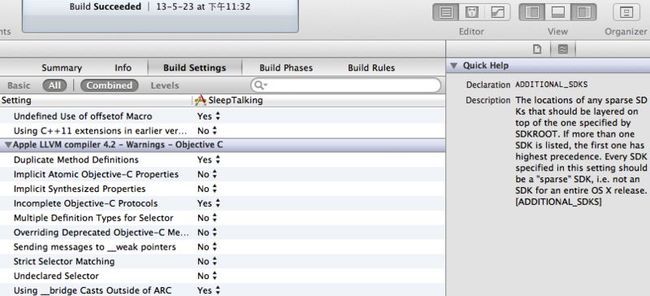
Xcode的工程模板已经为我们设置开启了一些默认和常用的警告提示,这些默认设置为了兼容一些上年头的项目,并没有打开很多,仅是指对最危险和最常见的部分进行了警告。这对于一个新项目来说这是不够用的(至少对我来说是不够用的),在无数前辈大牛的教导下,首先要做的事情就是打开尽可能多的警告提示。
最简单的方法是通过UI来打开警告。在Xcode中,Build Setting选项里为我们预留了一些打开警告的开关,找到并直接勾选相应的选项就可以打开警告。大部分时间里选项本身已经足够能描述警告的作用和产生警告的时机,如果不是很明白的话,在右侧的Quick Help面板里有更详细的说明。对于OC开发来说特有的警告都在Apple LLVM compiler 4.2 - Warnings - Objective C一栏中,不管您是不是决定打开它们,都是值得花时间看一看加以了解的,因为它们都是写OC程序时最应该避免的情况。另外几个Apple LLVM compiler 4.2 - Warnings - …(All languages和C++)也包含了大量的选项,以方便控制警告产生。
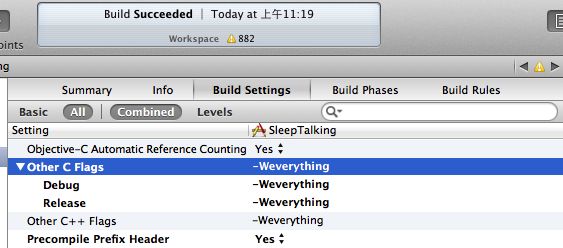
当然在UI里一个一个点击激活警告虽然简单,但每次都这样来一回是一种一点也不有趣的做法,特别是在你已经了解它们的内容并决定打开它们的时候。在编译选项中加入合适的flag能够打开或者关闭警告:在Build Setting中的Other C Flags里添加形似-W...的编译标识。你可以在其中填写任意多的-W...以开关某些警告,比如,填写为-Wall -Wno-unused-variable即可打开“全部”警告(其实并不是全部,只是一大部分严重警告而已),但是不启用“未使用变量”的警告。使用-W...的形式,而不是在UI上勾选的一大好处是,在编译器版本更新时,新加入的警告如果包含在-Wall中的话,不需要对工程做任何修改,新的警告即可以生效。这样立即可以察觉到同一个工程由于编译器版本更新时可能带来的隐患。另外一个更重要的原因是..Xcode的UI并没有提供所有的警告 =_=||..
刚才提到的,需要注意的是,-Wall的名字虽然是all,但是这真的只是一个迷惑人的词语,实际上-Wall涵盖的仅只是所有警告中的一个子集。在StackExchange上有一个在Google工作的Clang开发者进行的回答,其中解释了有一些重要的警告组:
-
- -Wall 并不是所有警告。这一个警告组开启的是编译器开发者对于“你所写的代码中有问题”这一命题有着很高的自信的那些警告。要是在这一组设定下你的代码出现了警告,那基本上就是你的代码真的存在严重问题了。但是同时,并不是说打开Wall就万事大吉了,因为Wall所针对的仅仅只是经典代码库中的为数不多的问题,因此有一些致命的警告并不能被其捕捉到。但是不论如何,因为Wall的警告提供的都是可信度和优先级很高的警告,所以为所有项目(至少是所有新项目)打开这组警告,应该成为一种良好的习惯。
- -Wextra 如其所名,
-Wextra组提供“额外的”警告。这个组和-Wall组几乎一样有用,但是有些情况下对于代码相对过于严苛。一个很常见的例子是,-Wextra中包含了-Wsign-compare,这个警告标识会开启比较时候对signed和unsigned的类型检查,当比较符两边一边是signed一边是unsigned时,产生警告。其实很多代码并没有特别在意这样的比较,而且绝大多数时候,比较signed和unsigned也是没有太大问题的(当然不排除会有致命错误出现的情况)。需要注意,-Wextra和-Wall是相互独立的两个警告组,虽然里面打开的警告标识有个别是重复的,但是两组并没有包含的关系。想要同时使用的话必须在Other C Flags中都加上 - -Weverything 这个是真正的所有警告。但是一般开发者不会选择使用这个标识,因为它包含了那些还正在开发中的可能尚存bug的警告提示。这个标识一般是编译器开发者用来调试时使用的,如果你想在自己的项目里开启的话,警告一定会爆棚导致你想开始撞墙..
关于某个组开启了哪些警告的说明,在GCC的手册中有一个参考。虽然苹果现在用的都是LLVM了,但是这部分内容应该是继承了GCC的设定。
控制警告,局部加入或关闭
Clang提供了我们自己加入警告或者暂时关闭警告的办法。
强制加入一个警告:
//Generate a warning #pragma message "Warning 1" //Another way to generate a warning #warning "Warning 2"
两种强制警告的方法在视觉效果上结果是一样的,但是警告类型略有不同,一个是-W#pragma-messages,另一个是-W#warnings。对于第二种写法,把warning换成error,可以强制使编译失败。比如在发布一些需要API Key之类的类库时,可以使用这个方法来提示别的开发者别忘了输入必要的信息。
//Generate an error to fail the build. #error "Something wrong"
对于关闭某个警告,如果需要全局关闭的话,直接在Other C Flags里写-Wno-...就行了,比如-Wextra -Wno-sign-compare就是一个常见的组合。如果相对某几个文件开启或禁用警告,在Build Phases的Compile Source相应的文件中加入对应的编译标识即可。如果只是想在某几行关闭某个警告的话,可以通过临时改变诊断编译标记来抑制指定类型的警告,具体如下:
#pragma clang diagnostic push #pragma clang diagnostic ignored "-Wunused-variable" int a; #pragma clang diagnostic pop
如果a之后没有被使用,也不会出未使用变量的警告了。对于想要抑制的警告类型的标识名,可以在build产生该警告后的build log中看到。Xcode中的话,快捷键Cmd+7然后点击最近的build log中,进入详细信息中就能看到了。

我应该开启哪些警告提示
个人喜好(代码洁癖)不同,会有不同的需求。我的建议是对于所有项目,特别是新开的项目,首先开启-Wall和-Wextra,然后在此基础上构建项目并且避免一切警告。如果在开发过程中遇到了某些确实无法解决或者确信自己的做法是正确的话(其实这种情况,你的做法一般即使不是错误的,也会是不那么正确的),可以有选择性地关闭某些警告。一般来说,关闭的警告项目不应该超过一只手能数出来的数字,否则一定哪儿出问题了..
是否要让警告等于错误
一种很常见的做法和代码洁癖是将警告标识为错误,从而中断编译过程。这让开发者不得不去修复这些警告,从而保持代码干净整洁。在Xcode中,可以通过勾选相应的Treat Warnings as Errors来开启,或者加入-Werror标识。我个人来说不喜欢使用这个设定,因为它总是打断开发流程。很多时候并不可能把代码全写完再编译调试,相反地,我更喜欢写一点就编译运行一下看看结果,这样在中间debug编译的时候会出现警告也不足为奇。另外,如果做TDD开发时,也可能会有大量正常的警告出现,如果有警告就不让编译的话,开发效率可能会打折扣。一个比较好的做法是只在Release Build时将警告视为错误,因为Xcode中是可以为Debug和Release分别指定标识的,所以这很容易做到。
另外也可以只把某些警告当作错误,-Werror=...即可,同样地,也可以在-Werror被激活时使用-Wno-error=...来使某些警告不成为错误。结合使用这些编译标识可以达到很好的控制。
原文地址:http://onevcat.com/2013/05/talk-about-warning/
编译器控制
#pragma
大家都说在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。
其格式一般为: #pragma Para。其中Para 为参数
我们就说说iOS下,常用的
#pragma mark
如果一个文件代码量很大,有时候找某段逻辑不太好找,你就可以使用#pragma mark!
比如这样:图12

图13
在方法导航哪里就会出现你的mark了 是不是很方便呀
如果使用了 "#pragma mark -" 如这样:
#pragma mark - #pragma mark 这里是applicationWillTerminate方法呀~ - (void)applicationWillTerminate:(UIApplication *)application { // Called when the application is about to terminate. Save data if appropriate. See also applicationDidEnterBackground:. }
就会这样,图14

自动分隔开了!!!
#pragma message("")
可以输出调试信息
控制编译器行为不过多解释了
#pragma clang diagnostic push
#pragma clang diagnostic ignored "clang的参数"
#pragma clang diagnostic pop
自行Clang使用手册: http://clang.llvm.org/get_started.html
#pragma非常复杂需要你对编译器底层非常的了解,只有当你开发一些比较底层的framework的时候才可能比较多用的,我是初学者,我不用我怕谁?
其他
#line
在说这个东西的时候我们先来看一个预定义的宏,__LINE__,我们在《宏定义的黑魔法 - 宏菜鸟起飞手册》自定义NSLog中见过吧
C语言中的__LINE__用以指示本行语句在源文件中的位置信息。而#line就是可以改变当前行的行号在编译器中的表示,并且之后的行号也会相应的改变,比如
1 #include <stdio.h> 2 main(){ 3 printf("%d\n",__LINE__); 4 #line 100 //指定下一行的__LINE__为100 5 printf("%d\n",__LINE__); 6 printf("%d\n",__LINE__); 7 };
输出为:
3 100 101