7.1 Models -- Introduction
一、概述
1. 模型是表示应用程序呈现给用户的底层数据的对象。不同的应用程序有不同的模型,这取决于它们正在试图解决什么问题。
2. 例如,一个照片分享应用程序可能有一个Phone模型来代表一个特殊的照片,并且PhotoAlbum代表一组照片。相反,一个在线购物应用程序可能有不同的模型,例如ShoppingCart,Invice或者LineItem。
3. 模型往往是持久的。这意味着当它们关闭浏览器窗口时,用户不希望模型数据丢失。为了确保没有数据丢失如果用户改变一个模型,需要把模型数据存储在不会丢失的地方。
4. 通常情况下,大多数模型被加载和存储在一个使用数据库存储数据的服务器。通常你会来回往返发送JASON代表模型打一个你编写的HTTP服务器。然而,Ember使它很容易使用其他持久化存储,例如使用IndexedDB存储到用户的硬盘上,或托管存储解决方案,让你避免编写和托管到你自己的服务器。
5. 一旦你从存储中加载了模型,组件知道如果将模型数据转换为用户可以与其交互的用户界面。想要获取更多关于组件是如何获取模型数据的信息,请看Specifying a Route's Model 。
6. Ember Data,默认情况下当你创建一个新的应用程序,它是一个库,它与Ember紧密结合,为了更方便从你的服务器检索模型作为JSON,保存到服务器,并且在浏览器中创建新的模型。
7. 由于其使用的adapter pattern,Ember Data可以被配置和不同类型的后台一起工作。这里有一个an entire ecosystem of adapters,它允许你的Ember应用程序和不同类型的服务器通话,而不必编写任何networking代码。
8. 如果你需要使用一个服务器集成你的Ember.js应用程序,没有一个可用的适配器(例如,你又一个API服务器不持之任何JSON规范),Ember Data被设计为可配置的,可以和你的服务器返回的任何数据一起工作。
9. Ember Data也被设计为可以和流服务器一起工作,像那些WebSockets。每当他们出现,你可以打开一个socket并且推送改变到Ember Data,给你的应用程序一个实时用户界面,它总是最新的。
二、Thinking in Ember Data
1. 首先,使用Ember Data可能有不同的感觉比你用来写JavaScript应用程序的方式。许多开发者熟悉使用AJAX从一个端点获取原始JSON数据,起初可能会显的容易一些。随着时间的推移,你的应用程序代码暴露出来的复杂性,使它很难维护。
2. 使用Ember Data,随着你的应用程序的成长管理模型变得既简单又容易。
3. 一旦你对Ember Data有了一个了解,你将会又一个更好的方法来管理应用程序中加载的数据的复杂性,允许你的代码扩展而不会造成混乱。
三、The store and a single source of truth
1. 构建网络应用程序最常见的方法是将用户界面元素紧密耦合获取数据。例如,想象你正在编写一个博客应用程序的管理部分,它又一个功能,列出了当前登录的用户。
2. 你可能会试图使组件负责获取数据并存储它:
app/components/list-of-drafts.js
import Component from "ember-component"; export default Component.extend({ willRender() { $.getJSON('/drafts').then(data => { this.set('drafts', data); }); } });
你然后可以展示在组件的模板上展示列表,像这样:
app/templates/components/list-of-drafts.hbs
<ul> {{#each drafts key="id" as |draft|}} <li>{{draft.title}}</li> {{/each}} </ul>
3. 虽然这样可以工作,但是这不是最理想的,有以下几个原因:
(1) 首先,通过通过将获取数据紧密耦合到一个独立的UI组件,共享数据的机会就失去了。当你构建你的应用程序的功能的时候,其他组件可能要访问相同的数据。
- 例如,想象一下你在博客编辑器中添加的下一个功能是应用程序工具栏中的一个小窗口,显示一个未发表的drafts。该组件也需要drafts的列表,但是因为这两个组件是负责获取自己的数据,你的应用程序将为相同的信息作出两次独立的请求。
- 不仅是多余的数据获取昂贵的带宽和影响你的应用程序的感知速度,这是很容易为两个值,以获得同步。你自己可能已经使用了一个web应用程序,列表中项目和工具栏中的计数器是同步的,导致一个令人沮丧和不一致的经验。
(2) 其次,这是不理想的是因为,它在应用程序的UI和net work code之间创建了紧密的耦合。如果加载的JSON格式发生变化,这种方式很可能打破你所有的UI组件,并且很难追踪。
- 好的设计SOLID原则告诉我们,对象应该有单一的职责。一个组件的职责应该是展现模型数据给用户,而不是获取model。
- 好的Ember应用程序采取不同的方法。Ember Data给了你一个单一的store,这是在你的应用程序中的中央仓库。组件和路由可以为models请求store,并且store负责指导怎样获取它们。
- 这也意味着,store可以检测到两个不同的组件正在请求一个相同的modle,允许你的app仅仅从服务器获取一次数据。你可以把这个store想成一个你的应用程序的模型的读取缓存(read-through cache)。你的组件和路由都访问这个共享的store;当你需要展现或者修改一个模型,它们首先向store请求它。
- 你使用store去检索record (an instance of a model),也创建新的。例如,我们可能希望通过ID为1从我们的路由model hook中查找一个person:
app/routes/index.js
export default Ember.Route.extend({ model() { return this.store.findRecord('person', 1); } });
四、Convention over configuration with JSON API(使用JSON API约定优于配置)
1. 依靠Ember的约定,你可以显着减少你需要写和维护的代码。通过采用这些约定,你不只是写更少的代码,你的代码将更容易维护和被其他开发人员理解。
2. 而不是创建任意的约定集合,Ember Data被设计为使用JSON API开箱工作。JSON API是一个正式规范,它用于建设约定的,强壮的,和高性能的APIs,它允许客户端和服务器传输模型数据。
3. JSON API规范JS应用程序如何和服务器通讯,所以你减少前端和后端的耦合,并且有更多的自由来改变pieces of your stack。
4. 做一个比喻,JSON API对于JS应用程序和API服务器来说就像SQL对于服务器端框架和数据库。流行的框架如Ruby on Rails,Django,laravel,Spring和更多的开箱工作与许多不同的数据库,如MySQL,PostgreSQL,SQL服务器,还有更多。
5. 框架(或建立在这些框架的应用程序)不需要编写自定义代码来位一个新的数据库添加支持;只要数据库支持的SQL,增加对它的支持是比较容易的。
6. 所以用JSON API。通过使用JSON API在你的Ember应用程序和你的server之间互操作,你可以完全改变你的后端栈而不打破你的前端。当你添加其他平台的应用程序,如iOS和Android,对也这些平台,你能够利用JSON API库更简单的使用和你的Ember应用程序相同的API。
五、Models
1. 在Ember Data中,每一个model被一个Model的子类代表,它定义了你展现给客户的数据的属性,关系和行为。
2. Models定义数据类型,它将被你的服务器提供。例如,一个Person model可能有一个firstName属性,它是一个字符串,并且有一个birthday属性,它是一个日期:
app/models/person.js
import Model, { attr } from "ember-data/model";
export default Model.extend({
firstName: attr('string'),
birthday: attr('date')
});
3. 一个模型也描述和其他对象之间的关系。例如,一个order可能有许多line-items,并且一个line-item可能属于一个特殊的order:
app/models/order.js
import Model, { hasMany } from "ember-data/model";
export default Model.extend({
lineItems: hasMany('line-item')
});
app/models/line-item.js
import Model, { belongsTo } from "ember-data/model";
export default Model.extend({
order: belongsTo('order')
});
模型本身没有任何数据;他们只是定义指定实例的属性,关系和行为,这些实例被称为records。
六、Records
1. 一个record是一个模型的实例,它包含从服务器加载的数据。你的应用程序也可以创建新的实例并且把它们保存回服务器。
2. 一个record是被唯一确定的通过它的模型的type和ID。
3. 例如,如果你正在编写一个联系人管理应用程序,你可能有一个Person模型。在你app中一个独立的实例可能有一个person的类型和ID为1或者steve-buscemi。
this.store.findRecord('person', 1); // => { id: 1, name: 'steve-buscemi' }
当你第一次保存它的时候,一个ID通常是由服务器反赔给一个实例。但是你也可以在客户端生成IDs。
七、Adapter
1. 一个adapter是一个对象,它把一个来自Ember(例如查找一个ID为123的用户)的请求转换为一个到服务器的请求。
2. 例如,如果你的app使用一个值为123的ID请求一个Person,Ember应该如何加载它?通过HTTP还是WebSocket呢?如果是HTTP,URL是/person/123还是/resources/people/1?
3. 这个适配器负责回答所有这些问题。不管何时你的app向store请求一个它没有缓存的record,它将向适配器请求它。如果你改变一个record并且保存它,这个store将这个record发送到适配器,适配器将相应的数据发送到你的服务器,并确认保存成功。
4. 适配器让你完全改变你的API是如何实现的,而不影响你的Ember应用程序代码。
八、Automatic Caching
1. store将会自动为你缓存records。如果一个record已经被加载,第二次请求它通常会返回相同的对象实例。这最大限度地减少了对服务器的往返次数,并允许您的应用程序以尽可能快的速度向用户呈现用户界面。
2. 例如,第一次你的应用程序适应ID为1向store请求一个person record,它将会从服务器获取信息。
3. 然而,下一次你的app用ID为1请求一个person,这个store将会察觉到,store已经从服务器上检索和缓存这个信息了。它不会为相同的信息发送另一个请求,它将给你的应用程序提供与第一次提供的实例相同的实例。这个功能—通常总是返回相同的record对象,不管你查询它多少次—有时被称为一个身份映射identity map。
4. 使用一个identity map是非常重要的,因为它确保你在一部分UI上的改变传播到UI的其他部分。这也意味着你不需要手动保持records同步,你可以通过ID请求一个record并且不必担心是否你的应用程序的其他部分已经请求并且加载了它。
九、Architecture overview
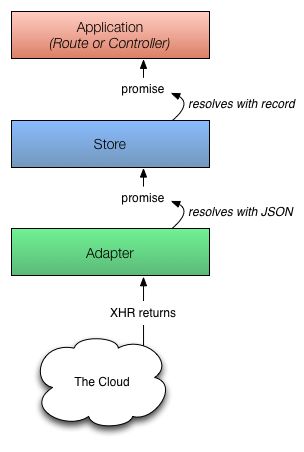
1. 你的app第一次向store请求一个record,这个store发现它没有本地的副本并且从adapter请求它。你的adapter将会去你的持久化层检索这个record;通常,这会是一个JSON代表这个record,它来自一个HTTP服务器。

- 如上图所示,适配器不能总是立即返回请求的记录。在这种情况下,适配器必须对服务器进行异步请求,只有当该请求完成加载时,该record将以其返回的数据被创建。
- 由于异步,这个store为find()方法立即返回一个promise,同样的,store到adapter的任何请求也都返回promises。
- 一旦到服务器的请求为请求的record返回一个JSON,适配器就解决了这个promise,它返回给store这个JSON。
- store然后拿着这个JSON,使用JSON数据初始化这个record,并且解决这个promise,使用新加载的record返回给你的app。
2. 让我们看一下如果请求的record在store中已经存在缓存了会发生什么:

在这种情况下,因为store已经知道这个record了,它返回一个promise,这个promise使用record立即解决。它不需要向adapter请求一个副本因为它已经被保存到了本地。