Solr的安装部署及简单使用
由于demo项目使用的是maven构建,maven仓库用的是oschina的,此时solr的最新版本是5.4,而oschina中的solrj最新版本是5.3.1,所以我们为了保持一致性,也将下载5.3.1的solr作为演示
一、下载
首先需要下载solr5.3.1,具体下载此处略。
二、安装
1,解压tomcat(此处使用的是tomcat 7)
2,解压solr5.3.1
3,将 solr-5.3.1\server\solr-webapp 文件夹底下的 webapp 复制到 tomcat 对应目录底下的 webapps 中,并将文件夹名字改为 solr(自己指定其他的名字也是可以的)
4,将 solr-5.3.1\server\lib\ext 文件夹底下的lib全部复制到tomcat底下的 solr/WEB-INF/libs/ 中
5,复制 log4j.properties到tomcat底下solr对应的classes文件夹下(classes需要创建)
6,复制 solr-5.3.1\server\solr 文件夹到自己指定的目录,此目录需要在下一步骤里填写(也可以不复制,直接引用)
7,修改tomcat底下的solr对应的web.xml配置文件,找到以下片段
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>/put/your/solr/home/here</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>
注:此片段默认是注释了的,需要解除注释。
将 env-entry-value 里的值替换为刚才第5步的路径。
三、启动tomcat,查看安装结果
http://localhost:8080/solr/
注:solr下载下来后,也可以使用自带的命令来启动,这里是因为需要配合java web项目,才放在tomcat里做演示使用
以上,我们就将solr安装到tomcat底下,但是仍然没有和我们的java项目结合起来使用,同时也没有加入对应的中文分词。接下来将继续讲下面的部分。
四、添加自定义solr
在刚才定义的
solr/home
文件夹底下,新建一个文件夹 my_solr,在my_solr目录中新建core.properties内容为name=mysolr (solr中的mysolr应用),同时将下载下来的solr-5.3.1解压文件中的 server/solr 文件夹的复制到my_solr目录底下
五、配置中文分词,以mmseg4j为例
1,下载jar包(mmseg4j-core-1.10.0.jar、mmseg4j-solr-2.3.0.jar),并复制到tomcat底下的 solr/WEB-INF/libs/ 中
2,配置my_solr文件夹中的schema.xml,在尾部新增
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> </analyzer> </fieldtype> <fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" /> </analyzer> </fieldtype> <fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="d:/my_dic" /> </analyzer> </fieldtype>
3,重启tomcat,查看效果
六、java中调用
1,在上面说的schema.xml中,添加
<field name="content_test" type="textMaxWord" indexed="true" stored="true" multiValued="true"/>
2,新建测试类
package demo.test;
import org.apache.solr.client.solrj.*;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* solr 5.3.0
* Created by daxiong on 2015/10/23.
*/
public class MySolr {
//solr url
public static final String URL = "http://localhost:8080/solr";
//solr应用
public static final String SERVER = "mysolr";
//待索引、查询字段
public static String[] docs = {"Solr是一个独立的企业级搜索应用服务器",
"它对外提供类似于Web-service的API接口",
"用户可以通过http请求",
"向搜索引擎服务器提交一定格式的XML文件生成索引",
"也可以通过Http Get操作提出查找请求",
"并得到XML格式的返回结果"};
public static SolrClient getSolrClient(){
return new HttpSolrClient(URL+"/"+SERVER);
}
/**
* 新建索引
*/
public static void createIndex(){
SolrClient client = getSolrClient();
int i = 0;
List<SolrInputDocument> docList = new ArrayList<SolrInputDocument>();
for(String str : docs){
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id",i++);
doc.addField("content_test", str);
docList.add(doc);
}
try {
client.add(docList);
client.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
};
/**
* 搜索
*/
public static void search(){
SolrClient client = getSolrClient();
SolrQuery query = new SolrQuery();
query.setQuery("content_test:搜索");
QueryResponse response = null;
try {
response = client.query(query);
System.out.println(response.toString());
System.out.println();
SolrDocumentList docs = response.getResults();
System.out.println("文档个数:" + docs.getNumFound());
System.out.println("查询时间:" + response.getQTime());
for (SolrDocument doc : docs) {
System.out.println("id: " + doc.getFieldValue("id") + " content: " + doc.getFieldValue("content_test"));
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
createIndex();
search();
}
}
3,查看执行结果
{responseHeader={status=0,QTime=23,params={q=content_test:搜索,wt=javabin,version=2}},response={numFound=2,start=0,docs=[SolrDocument{id=0, content_test=[Solr是一个独立的企业级搜索应用服务器], _version_=1522509944966873088}, SolrDocument{id=3, content_test=[向搜索引擎服务器提交一定格式的XML文件生成索引], _version_=1522509945343311874}]}}
文档个数:2
查询时间:23
id: 0 content: [Solr是一个独立的企业级搜索应用服务器]
id: 3 content: [向搜索引擎服务器提交一定格式的XML文件生成索引]
七,与数据库整合
我们通常查询的数据都是在数据库(或缓存数据库),这里以mysql作为示例。
1,进入my_solr/conf目录中,找到 solrconfig.xml 配置文件,打开,在其中增加如下代码
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
这个是用来配置导入数据的配置文件
2,增加完后,再在同级目录增加 data-config.xml 文件,文件内容如下
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource type="demoDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/demo" user="root" password="" batchSize="-1" /> <document> <entity name="t_user" pk="id" query="SELECT * FROM t_user"> <field column="username" name="username" /> </entity> </document> </dataConfig>
其中配置的字段请填写自己数据库的相应配置。
3,然后打开 schema.xml ,在其中增加如下代码
<field name="username" type="text_general" indexed="true" stored="true" required="true" multiValued="true" />
这里的username和上面的username对应,用作查询使用。
4,打开solr管理后台 http://localhost:8080/solr/#/mysolr ,点击左侧菜单“Dataimport“,默认勾选项即可,点击”Excute“按钮,这时会按照刚才的配置导入相应的数据到solr中,执行完成后会出现如下截图(执行时间可能会比想象的要长一点)
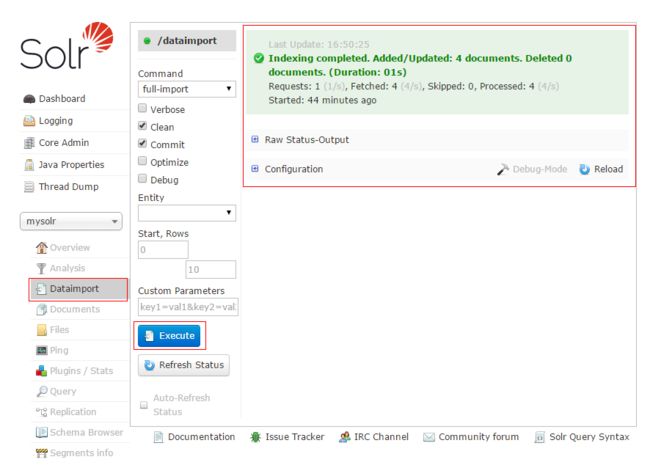
以上,我们就将mysql和solr关联了起来。接下来,我们可以点击左侧菜单”Query“,在”q“所在的对话框下,输入对应的搜索关键词,例如:username:张三,然后点击”Excute Query“按钮,就可以在右侧看到查询结果
那么怎么在java中调用,得到自己要的查询结果呢?
现在我知道的是两种方法:
1,使用http访问,返回对应的json数据
2,使用SolrQuery调用(上述已有示例代码)
相应的高级查询方法,后续如果有时间会继续补充。