帮助记忆yarn框架的那张图
hadoop1:
JobTracker负责:①作业调度和任务进度监视 ②追踪任务、重启失败或过慢的任务和进行任务登记。
hadoop2:
ResourceManager和 ApplicationMaster相当于JobTracker。
ResourceManager(资源管理器),负责①作业调度和任务进度监视
ApplicationMaster(应用管理器),负责②追踪任务、重启失败或过慢的任务和进行任务登记
如果运行的是MapReduce程序,那么ApplicationMaster也叫作MRAppMaster.
下图是yarn的框架:
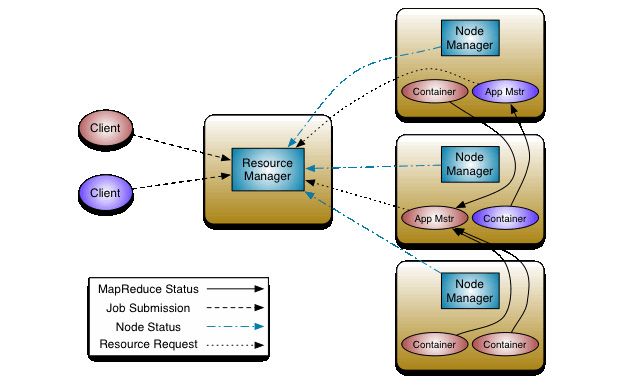
该框架的图解过程:
1.client客户端向ResourceManager提交任务时,实际上是向ResourceManager提交一个mapreduce程序(Job Submission那条线)
2.ResourceManager接收到这个MR程序后,把这个程序交给了某个NodeManager(图上没标这条线)
3.NodeManager接收到了这个MR程序,启动了一个进程叫MRAppMaster(第一个NodeManager上的那个App Mstr)
4.MRAppMaster进程向ResourceManager请求资源:“我需要xx个资源”(ResourceRequest那条线)
5.ResourceManager同意给它分配,并且去跟每一个NodeManager协商:“我需要xx个资源,你先给我分配一个container可以吗”(图上没标这条线)
6.第一个NodeManager说:“我的container是好的,可以用,分配给你用吧”(Node Status那条线)
7.ResourceManager就在本子上记下了——第一个NodeManager的container可以用,然后去问下一个NodeManager要container,如果NodeManager说:“诶真不凑巧,我这个container坏了,你用不了了”,ResourceManager就不能拿这个container,接着向下一个NodeManager要。。。。直到这xx个container都要够了(图上没标)
8.ResourceManager把所有可以用的NodeManager的container记到了本子上,把这个本子给MRAppMaster并跟它说 :“你去这些node上拿资源吧,我给你申请好了,都是可以用的”(图上没标)
9.MRAppMaster就按着这个本子上写的去各个Node上直接拿container了。(MapReduce Status 那条线)
总之就是RM和AM协调,用哪些node、用多少container。协调好了之后向负责管理这些的NodeManager要。