实践GDB
调试工具简介:
GDB
Unix程序员最常用的调试工具是GDB,这是由Richard Stallman(开源软件运动的领路人)
开发的GNU项目调试器,该工具在Linux开发中扮演了关键的角色。
CGDB
cgdb可以看作gdb的界面增强版,用来替代gdb的 gdb -tui。cgdb主要功能是在调试时进行代码的同步显示,这无疑增加了调试的方便性,提高了调试效率。
DDD
随着GUI(用户图形界面)越来越流行,大量在Unix环境下运行的基于GUI的调试器被开发出来。其中的大多数工具都是GDB的GUI前端:用户通过GUI发出命令,GUI将这些命令传递给GDB。DDD(数据显示调试器)就是其中的一种工具。
三者的区别和联系:
- gdb在命令行中使用,并不十分方便。
- CGDB和DDD都是基于GDB开发的,他们只是增加了更加容易交互的界面。其中CGDB也是在命令行中使用的,使用方式与GDB一样,只是增加了代码显示的界面。
- DDD也是GNU开发的,他也是基于GDB的,只是使用了可视化界面,比CGDB更加容易操作
GDB方法示例:一个排序程序
为了跟踪第一个程序错误,在GDB中运行这个程序,并在按Ctrl+C组合键挂起程序之前让它运行一会。用这种方法可以确定无限循环的位置。
1 // 2 // insertion sort, several errors 3 // 4 // usage: insert_sort num1 num2 num3 ..., where the numi are the numbers to 5 // be sorted 6 7 int x[10], // input array 8 y[10], // workspace array 9 num_inputs, // length of input array 10 num_y = 0; // current number of elements in y 11 12 void get_args(int ac, char **av) 13 { int i; 14 15 num_inputs = ac - 1; 16 for (i = 0; i < num_inputs; i++) 17 x[i] = atoi(av[i+1]); 18 } 19 20 void scoot_over(int jj) 21 { int k; 22 23 for (k = num_y-1; k > jj; k++) 24 y[k] = y[k-1]; 25 } 26 27 void insert(int new_y) 28 { int j; 29 30 if (num_y = 0) { // y empty so far, easy case 31 y[0] = new_y; 32 return; 33 } 34 // need to insert just before the first y 35 // element that new_y is less than 36 for (j = 0; j < num_y; j++) { 37 if (new_y < y[j]) { 38 // shift y[j], y[j+1],... rightward 39 // before inserting new_y 40 scoot_over(j); 41 y[j] = new_y; 42 return; 43 } 44 } 45 } 46 47 void process_data() 48 { 49 for (num_y = 0; num_y < num_inputs; num_y++) 50 // insert new y in the proper place 51 // among y[0],...,y[num_y-1] 52 insert(x[num_y]); 53 } 54 55 void print_results() 56 { int i; 57 58 for (i = 0; i < num_inputs; i++) 59 printf("%d\n",y[i]); 60 } 61 62 int main(int argc, char ** argv) 63 { get_args(argc,argv); 64 process_data(); 65 print_results(); 66 }
编译代码

运行,尝试只有两个数的排序

首先,对insert_sort启动GDB调试器,屏幕显示如下:
现在从GDB中执行run命令以及程序的命令行参数来运行该程序,然后按Ctrl+C组合键挂起它。屏幕显示如下
该屏幕表明,当程序停止时,insert_sort在函数process_data()中,即将执行源文件ins.c的第52行。
现在第52行是从第49行开始的循环的一部分。根据确认原则,应当用GDB查看一下当前num_y的值。
对GDB的这一查询的输出表明num_y的值为1,因此我们现在在循环的第二个迭代上(49行)。通知GDB在循环的第二次迭代期间,在第52行的insert()中停止,以便查看情况,尝试找出程序在这个位置出了什么问题。
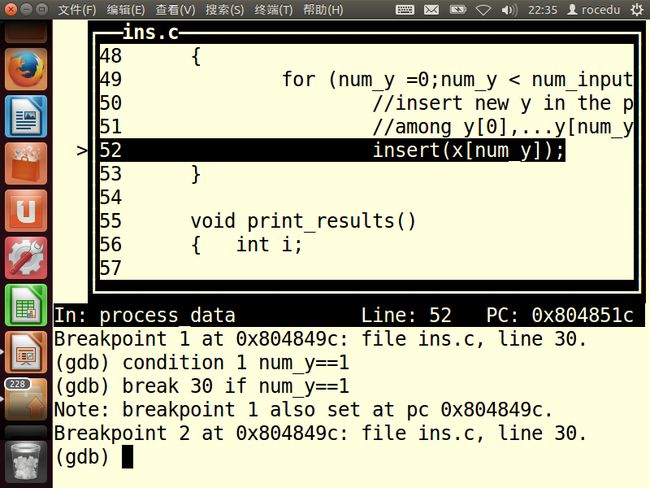
第一个命令在第30行(insetrt()的开头)放置一个断点。也可以通过break insert指定这个断点,即在insert()的第一行处中断。后一种形式有一个优点:如果修改了这个程序代码,使得函数insert()不再再ins.c的第30行开始,那么如果用函数名指定断点,而不是用行号指定,则断点仍然有效。
break命令一般会使得每次程序执行到指定行时都会暂停。然而这里的的第二个命令condition 1 num_y==1使得该断点成为有条件的断点:只有当满足条件num_y==1时,GDB才会暂停程序的执行。
与接收行号或者函数名的break命令不同,condition接收断点号。总是可以用命令info break和condition命令组合成一个步骤,如下
break 30 if num_y==1
然后用run命令再次运行程序,如下图。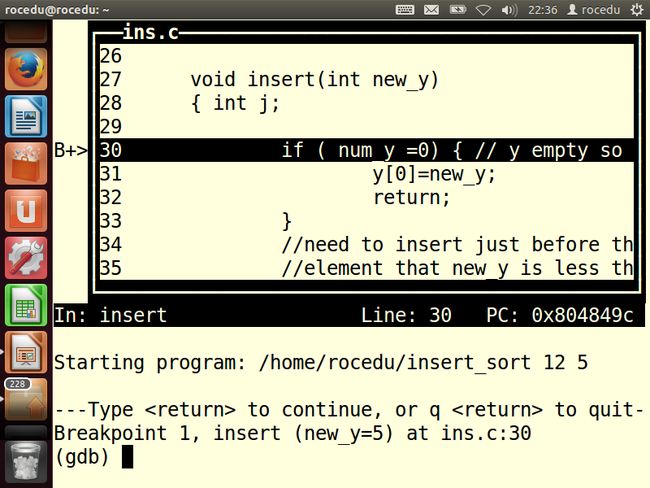
我们再次应用确认原则:因为num_y==1,所以应该跳过31行,直接执行第36行。但是我们需要确认这一点,因此执行next命令来继续执行下一行。
继续单步调试程序。由于现在位于循环的开头,因此再执行几次next命令来逐行查看循环的进展。
我们直接从第37行跳到了第45行。该循环在第36行处根本不执行迭代的唯一原因是:即使当J为0,第36行的条件j<num_y也不成立。现在确认一下num_y==1是否成立。
现在发现程序的错误第30行和第36行之间的某处,检验后发现在第30行我们用了=而不是==,拔一次相等测试变成了赋值操作。修改后重新编译运行

仍然没有得到正确的输出。再次运行程序,当程序开始处理第二个输入时停止。
这表示GDB发现我们冲死你编译了程序,在运行程序之前自动重新加载了新的二分表和新的符号表。
提示:在重新编译程序之前不要退出GDB,在调试回话期间不要退出再重启文本编辑器。
现在再次尝试单步调试代码,程序应该跳过31行,且可能到达第37行。通过next来检查这两点: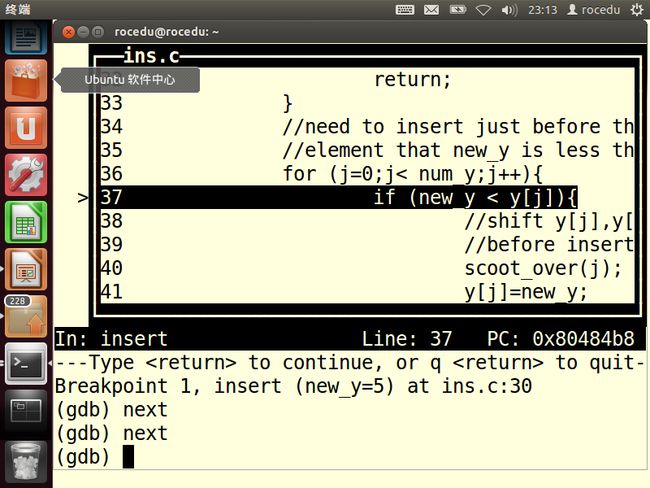
到达第37行。这是我们认为第37行的if中的条件应当成立,因为new_y=5,并且第一次迭代结束y【0】应为12.GDB输出确认了前一个假设,下面检查后一个假设。
这个假设也得到了确认,执行next命令,到达41行。
采用自定向下的调试方法,在第40行选择next命令,而不是step命令。
查看scoot_over()有没有正确地移动12.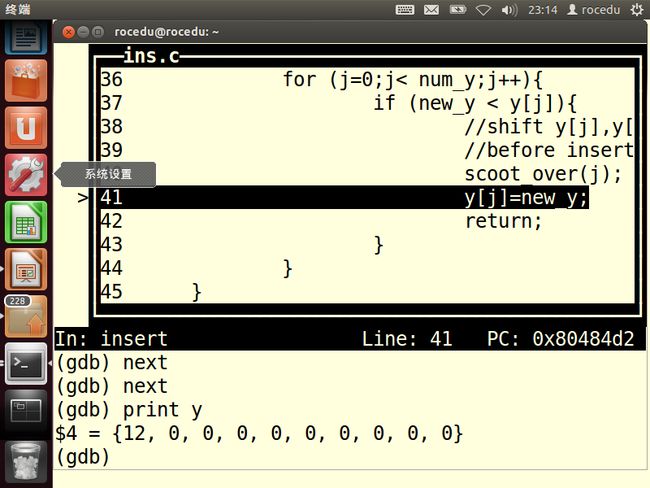
没有。问题出现在scoot_over()中。删除insert()开头的断点看看,并在scoot_over()中放置一个断点,同样采用一个可在第49行的第二次迭代时停止的条件。
再次运行程序
再次遵循确认原则,预期第23行的循环应当恰好通过异常迭代。通过next命令来但不调试该程序,以便确认这种预期。
发现循环没有执行,显然第23行有一个错误:k>jj没有得到满足。从而发现循环初始化错了,应该是k==num_y。
修复这个错误,重新编译程序,再次运行(在GDB之外)。
当运行程序试图访问不允许范根的内存时发生了段错误。原因通常是由于数组索引超出了边界,或者采用了错误额指针值。
在GDB中运行insert_sort,并重建段错误。首先删除断点,用clear命令。
再次在GDB中运行程序。
GDB告诉了我们段错误发生的确切位置——第24行,与名为k的数组索引有关。重新确定k的值。
首先,确定段错误发生时这个重要循环迭代在第49行
修复这行代码并咋次重新编译并运行程序
检测该程序对于较大的数据集是否运行正确
该列表正的第一个美欧正确排序的数字是19,因此在第36行设置一个断点,这次采用new_y==19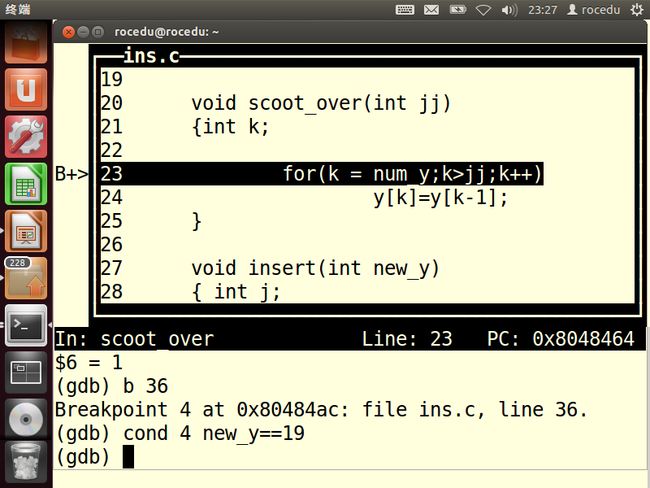
然后再GDB中运行程序,使用与之前相同的参数。当遇到断点时。确认到目前为止数组y已经被正确地排序
尝试确定程序如何处理19,一次一行代码进行调试,当遇到几次n后,程序运行在第45行,打算退出循环而没有对19进行任何操作。这表明new_y大于目前为止处理的任一元素,而我们忽略了这一情况,第34行和第35行的注释还揭露了一个纰漏:
// need to insert just before the first y // element that new_y is less than
在44行后面添加如下代码:
y[num_y]=num_y;
重新编译运行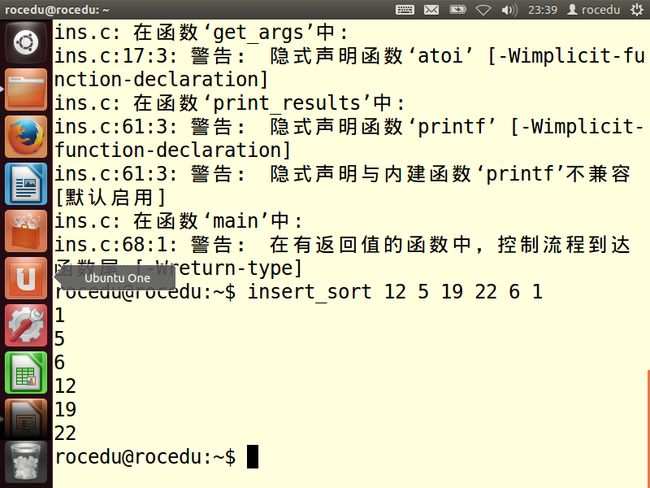
DDD运行示例
同样的会话在DDD中的情况
用GCC 编译源代码,使用-g选项,然后键入:ddd insert_sort调用DDD。
单击Program->Run,将看到如下所示的屏幕。

这时弹出了Run窗口。可以选择或键入参数,然后按下Run按钮。

同样研究无限循环,通过命令工具单击Interrupt工具来挂起程序。
通过源窗口中num_y的任意实例上移动鼠标来检查该变量。
右击断点行中的停止标记,然后选择Properties在第30行设置一个断点。这时会弹出一个窗口,然后键入条件:num_y==1
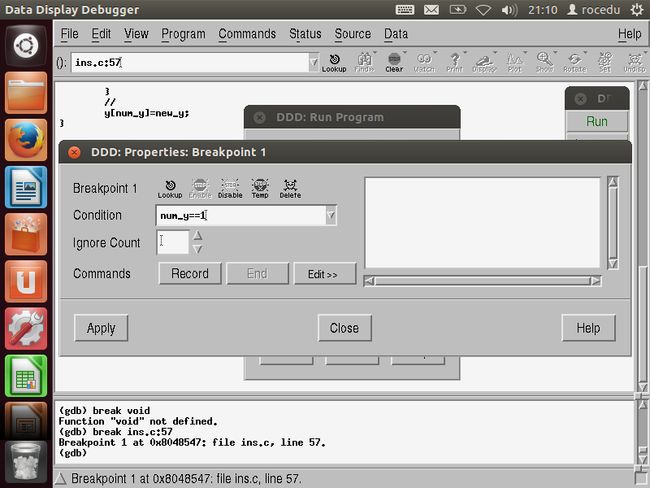
重新运行程序,单击Run按钮。
在DDD中,与GDB的S命令相对应的是next和step。对应于GDB中的C命令的是cont按钮。
多进程和多线程
操作系统将运行程序的每个实例表述为进程或任务。在只有一个CPU的机器上,进程必须依次操作。操作系统中有一个进程表,列出了关于当前所有进程的信息。一般来说,每个进程在进程表中被标记为RUN或者sleep状态。
线程与进程非常类似,只是线程占用的内存比进程少,创建线程和在线程间切换所需的时间也少。多线程应用程序一般会执行一个main()过程,该过程创建一个或多个子进程。父线程main()也是线程。
下面的程序用经典的埃拉托色尼筛法。要求2~n之间的素数,首先列出所有这些数字,然后去掉所有2的倍数,再去掉3的倍数。以此类推,剩下的是素数。
1 // finds the primes between 2 and n; uses the Sieve of Eratosthenes, 2 // deleting all multiples of 2, all multiples of 3, all multiples of 5, 3 // etc.; not efficient, e.g. each thread should do deleting for a whole 4 // block of values of base before going to nextbase for more 5 6 // usage: sieve nthreads n 7 // where nthreads is the number of worker threads 8 9 #include <stdio.h> 10 #include <math.h> 11 #include <pthread.h> 12 13 #define MAX_N 100000000 14 #define MAX_THREADS 100 15 16 // shared variables 17 int nthreads, // number of threads (not counting main()) 18 n, // upper bound of range in which to find primes 19 prime[MAX_N+1], // in the end, prime[i] = 1 if i prime, else 0 20 nextbase; // next sieve multiplier to be used 21 22 int work[MAX_THREADS]; // to measure how much work each thread does, 23 // in terms of number of sieve multipliers checked 24 25 // lock index for the shared variable nextbase 26 pthread_mutex_t nextbaselock = PTHREAD_MUTEX_INITIALIZER; 27 28 // ID structs for the threads 29 pthread_t id[MAX_THREADS]; 30 31 // "crosses out" all multiples of k, from k*k on 32 void crossout(int k) 33 { int i; 34 35 for (i = k; i*k <= n; i++) { 36 prime[i*k] = 0; 37 } 38 } 39 40 // worker thread routine 41 void *worker(int tn) // tn is the thread number (0,1,...) 42 { int lim,base; 43 44 // no need to check multipliers bigger than sqrt(n) 45 lim = sqrt(n); 46 47 do { 48 // get next sieve multiplier, avoiding duplication across threads 49 pthread_mutex_lock(&nextbaselock); 50 base = nextbase += 2; 51 pthread_mutex_unlock(&nextbaselock); 52 if (base <= lim) { 53 work[tn]++; // log work done by this thread 54 // don't bother with crossing out if base is known to be 55 // composite 56 if (prime[base]) 57 crossout(base); 58 } 59 else return; 60 } while (1); 61 } 62 63 main(int argc, char **argv) 64 { int nprimes, // number of primes found 65 totwork, // number of base values checked 66 i; 67 void *p; 68 69 n = atoi(argv[1]); 70 nthreads = atoi(argv[2]); 71 for (i = 2; i <= n; i++) 72 prime[i] = 1; 73 crossout(2); 74 nextbase = 1; 75 // get threads started 76 for (i = 0; i < nthreads; i++) { 77 pthread_create(&id[i],NULL,(void *) worker,(void *) i); 78 } 79 80 // wait for all done 81 totwork = 0; 82 for (i = 0; i < nthreads; i++) { 83 pthread_join(id[i],&p); 84 printf("%d values of base done\n",work[i]); 85 totwork += work[i]; 86 } 87 printf("%d total values of base done\n",totwork); 88 89 // report results 90 nprimes = 0; 91 for (i = 2; i <= n; i++) 92 if (prime[i]) nprimes++; 93 printf("the number of primes found was %d\n",nprimes); 94 95 }
这个程序有两个命令行参数,一个参数用来检查素数范围上边界的n,另一个参数表示要创建的工程线程数量的nthreads。
Main()创建工作线程,每个工作线程是对函数worker()的一次调用。这些工作线程共享3个数据项:上边界变量n,指定要从2~的范围内删除其倍数的下一个数字的变量nextbase,以及记录2~n的范围内的每个数字是否被消除的数组prime[]。每次调用反复的取得一个尚未处理的被乘数base,然后消除2~n范围内base的所有倍数。创建了工作线程后,main()就使用pthread_join()等待所有线程完成各自的工作,然后在统计留下的素数的数量后恢复程序,并发出报告。
任何的工作线程都可能被被另一个工作线程在不可预测的时间抢占,而抢占的工作线程会在worker()中不可预测的位置。特别是,可能碰巧在如下的语句中间中断当前线程。
base=nextbase+=2
而且下一个时间片被赋予了也执行这个语句的另一个线程。在这种情况下,有两个线程试图立即修改共享变量nextbase,它可能导致隐伏且难以重现的程序错误。用防护语句将操作共享变量的代码括起来,可以防止发生这种情况。
现在假设我们忘掉解锁语句:pthread_mutex_unlock(&nextbaselock)
使用GDB进行调试
编译程序,确保包括-lpthread –lm标记,以便链接pthreads和数学函数库。
然后运行GDB中的代码,n=1000000,nthread=200,通过按下ctrl+c组合键中断它

在这种时候,关键要知道每个线程在什么,通过GDB的info thread命令来确定:
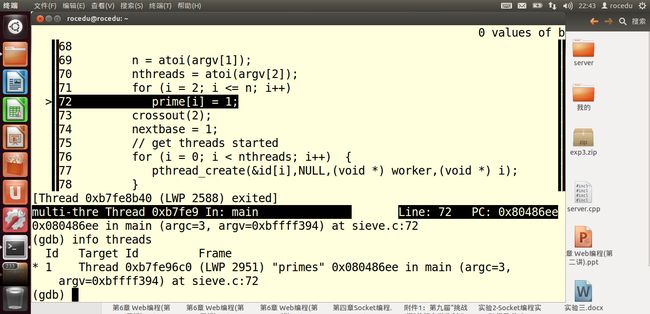
星号表示当前在线程1中,现在看看那个线程是在做什么:

从上图可以看出,该线程正在向主函数传递参数。
段错误
当某个错误导致程序突然和异常地停止执行时,程序崩溃。迄今最常见的导致程序崩溃的原因是试图在未经允许的情况下访问一个内存单元。硬件会感知这件事情并执行对操作系统的跳转。在Unix平台上,操作系统一般会宣布程序导致了段错误。
下面将详细简述虚拟内存问题与段错误的关系:
先理解程序在内存中的布局:
在Unix平台上,为程序分配的虚拟地址的布局通常如下:
| .text |
| .data |
| .bss |
| 堆 |
| 未使用 |
| 栈 |
| Env |
这里虚拟地址0在最下方,堆和栈增长时,消耗掉自由区域。各个部分的区域如下所示:
1.文本区域(.text):由程序源代码中的编译器产生的及其指令组成。 一组件包括静态链接代码和做初始化工作的系统代码/usr/lib/crt0.0,然后调用main()。
2.数据区域:包含在编译时分配的所有程序变量,即全局变量。
这一区域由各种各样的子区域组成。第一个区域称为.data,由初始化的变量组成。如 int x=5;另一种用于存放未初始化数据的.bss区域,如 int y;
3.当程序在运行时从操作系统中请求额外的内存时,请求的内存在名为堆的区域中分配。如果堆空间不够,就用brk()来扩展堆。
4.栈区域:用来动态分配数据的空间。函数调用的数据都存储在栈上。每次进行函数调用时栈都会增长,每次函数返回到其调用者时栈都会收缩。
页的概念
虚拟地址空间是通过组织成页的块来查看的。物理内存也是分成页来查看的。当程序被加载到内存中执行时,操作系统会安排程序的部分页存储在物理内存的页中。这些也称为被“驻留”,其余部分存储在磁盘上。
操作系统为每个过程设立了一个页表。每个虚拟页在表中都有对应得一个项,包括如下信息:
- 这个页的当前物理位置在内存中或磁盘上。
- 该页的权限分三种:读、写和执行。
操作系统不会将不完整的页分配给程序,表明程序的一些错误内存访问不会触发段错误。
采用上图的虚拟地址空间,假设页的大小为4 096字节,然后虚拟页0包含虚拟地址空间的第0~4095字节,页1包含第4096~8191字节,依次类推。
当我们运行程序时,操作系统创建一个用来管理执行程序进程的虚拟内存页表。每当该进程运行时,硬件的页表寄存器都会指向该表。
从概念上讲,进程虚拟地址空间的每个页在页表中都有一个页表项。这个页表项存储与该页相关的各块信息。与段错误相关的数据是该页的访问权限,它类似于文件的访问权限:读、写和执行。
当程序执行时,它会连续访问各个区域,导致硬件按一下几种情况所示处理页表:
- 每次程序使用其全局变量之一时,需要具有对数字区域的读/写访问权限。
- 每次程序访问局部变量时,程序会访问栈,需要对栈区域具有读/写访问权限。
- 每次程序进入或者离开函数的时候,对该栈进行一次或者多次访问,需要对栈区域具有读写访问权限。每次程序访问通过调用malloc()或new()创建的存储器时,都会发生堆访问,也需要读/写访问权限。
- 程序执行的每个机器指令是从文本区域取出的,所以需要具有读和执行的权利。
在程序的执行期间,生成的地址是虚拟的,当程序试图访问某个虚拟地址处的内存时,比如y,硬件就会将其转换为虚拟页号v,它等于y除以4096。然后硬件会检查页表中的页表项v来查看该页的权限是否与要执行的操作匹配。如果匹配,硬件就会从这个表项中得到所需位置的实际物理页号,然后完成请求的内存操作。如果不具有恰当的权限,硬件就会执行内部中断。这会导致跳转到操作系统的错误处理例程。然后,操作系统一般会宣告一个内存违反访问,并停止程序的执行。
程序中的程序错误会导致权限不匹配,并在上面列出的任何类型的内存访问期间生成段错误。
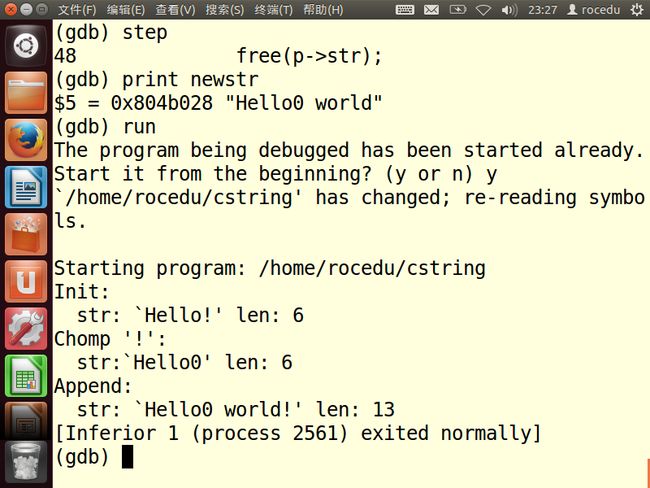
下面这个C代码类似于C++字符串的托管字符串类型的实现部分:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 5 typedef struct { 6 char *str; 7 int len; 8 } CString; 9 10 11 12 CString *Init_CString(char *str) 13 { 14 CString *p = malloc(sizeof(CString)); 15 p->len = strlen(str); 16 strncpy(p->str, str, strlen(str) + 1); 17 return p; 18 } 19 20 21 void Delete_CString(CString *p) 22 { 23 free(p); 24 free(p->str); 25 } 26 27 28 // Removes the last character of a CString and returns it. 29 // 30 char Chomp(CString *cstring) 31 { 32 char lastchar = *( cstring->str + cstring->len); 33 // Shorten the string by one 34 *( cstring->str + cstring->len) = '0'; 35 cstring->len = strlen( cstring->str ); 36 37 return lastchar; 38 } 39 40 41 // Appends a char * to a CString 42 // 43 CString *Append_Chars_To_CString(CString *p, char *str) 44 { 45 char *newstr = malloc(p->len + 1); 46 p->len = p->len + strlen(str); 47 48 // Create the new string to replace p->str 49 snprintf(newstr, p->len, "%s%s", p->str, str); 50 // Free old string and make CString point to the new string 51 free(p->str); 52 p->str = newstr; 53 54 return p; 55 } 56 57 58 int main(void) 59 { 60 CString *mystr; 61 char c; 62 63 mystr = Init_CString("Hello!"); 64 printf("Init:\n str: `%s' len: %d\n", mystr->str, mystr->len); 65 c = Chomp(mystr); 66 printf("Chomp '%c':\n str:`%s' len: %d\n", c, mystr->str, mystr->len); 67 mystr = Append_Chars_To_CString(mystr, " world!"); 68 printf("Append:\n str: `%s' len: %d\n", mystr->str, mystr->len); 69 70 Delete_CString(mystr); 71 72 return 0; 73 }
编译运行代码

用GDB分析核心文件

根据回溯输出,段错误发生在第16行的Init_CString()中,因此将当前帧改为调用Init_CString()的那一帧
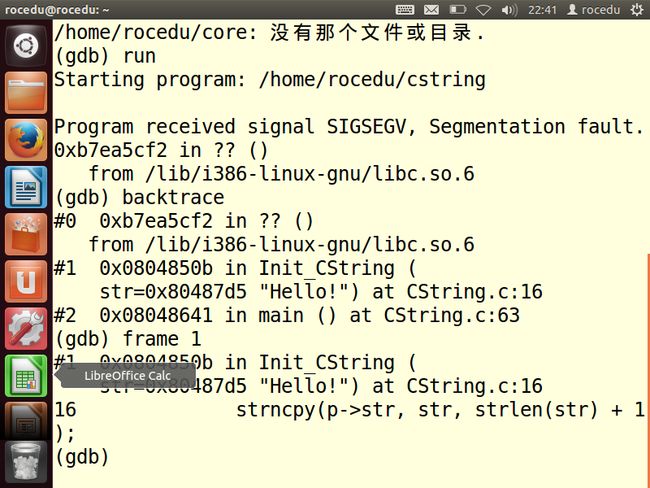
输出str的值,不等于null

输出p和p->str的值

很明显p->str=null。所以段错误的原因找到:程序试图写入到内存中的位置0。

根据上图可以看出前面只有两行代码,第14行很可能是问题的根源
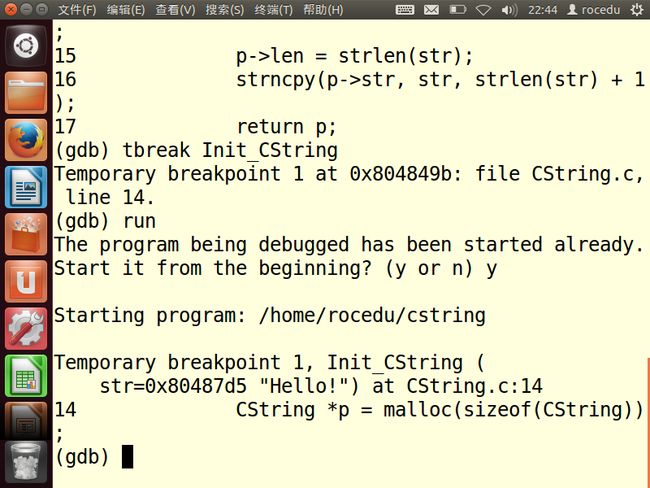
在GDB中重新运行程序,在进入Init_CString()的入口处设置一个临时断点,并逐行单步调试这个函数,查看p->str的值。

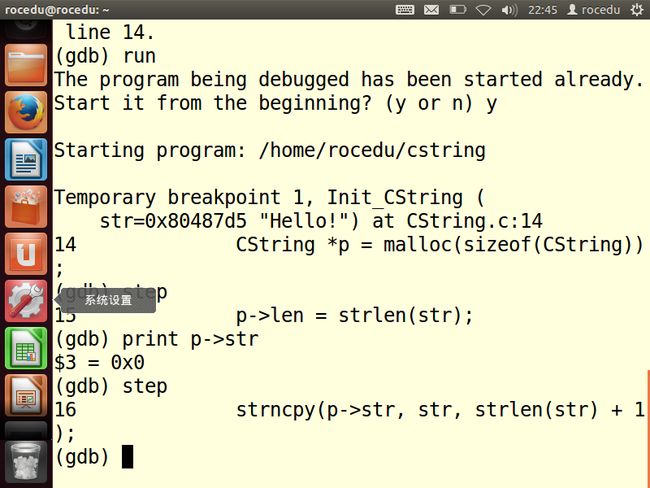
可以分析出,错误出现在我们声明指针,但是没有声明指针的任何对象。所以需要在字符串的长度上加1,因为strlen()没有将末尾的’\0’统计在内。
再次在GDB中运行程序
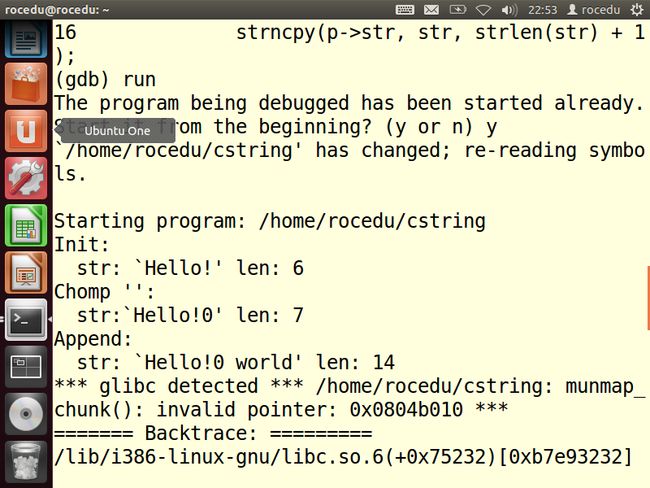
Chomp()看起来明显有错,所以在该函数的入口处放置一个临时断点。

该字符串的最后一个字符应该是!,让我们确认一下:

与预期不符,修改代码。
重新编译代码并运行

再查找另一个段错误,根据附加操作后面缺少惊叹号,下一个程序应该隐藏在Append_Chars
_CString()中。

假设错误,程序实际上在Delete_CString()中崩溃。

修复错误,重新运行

附加操作以后丢失了感叹号,但字符长度正确。推断错误出现在Appemd_Chars_CString(),在那里放置一个断点。

对第43行进行修改,使它有足够的内存空间
修改后重新编译。

由于我们修复的是“静默的程序错误”,因此在Append_Chars_To_CString()再次设置一个断点。


确认第46行的newstr

第48行的代码缺少感叹号,问题可能出在46行。修复代码,让snprintf()复制足够的字节以存放源字符串的文本和结尾空字符
编译修复后的代码并运行
汇编代码调试
1 #include <stdio.h> 2 3 int nGlobalVar = 0; 4 5 int tempFunction(int a, int b) 6 { 7 printf("tempFunction is called, a = %d, b = %d \n", a, b); 8 return (a + b); 9 } 10 11 int main() 12 { 13 int n; 14 n = 1; 15 n++; 16 n--; 17 18 nGlobalVar += 100; 19 nGlobalVar -= 12; 20 21 printf("n = %d, nGlobalVar = %d \n", n, nGlobalVar); 22 23 n = tempFunction(1, 2); 24 printf("n = %d", n); 25 26 return 0; 27 }
sample.c ,用GCC编译
启动GDB,使用“file”命令载入被调试程序 sample
使用“r”命令执行(Run)被调试文件,因为尚未设置任何断点,将直接执行到程序结束
使用“b”命令在 main 函数开头设置一个断点
再次使用“r”命令执行(Run)被调试程序

使用“s”命令(Step)执行下一行代码,显示内容表示表示已经执行完“n = 1;”,并显示下一条要执行的代码为第20行的“n++;“
用“p”命令(Print)看一下变量 n 的值是不是 1
分别在第26行、tempFunction 函数开头各设置一个断点
使用“c”命令继续(Continue)执行被调试程序,程序将中断在第二个断点(26行),此时全局变量 nGlobalVar 的值应该是 88

再一次执行“c”命令,程序将中断于第三个断点(12行,tempFunction 函数开头处),此时tempFunction 函数的两个参数 a、b 的值应分别是 1 和 2
再一次执行“c”命令(Continue),因为后面再也没有其它断点,程序将一直执行到结束


进行汇编级的调试跟踪
用display命令“display /i $pc”(display,设置程序中断后欲显示的数据及其格式。例如,如果希望每次程序中断后可以看到即将被执行的下一条汇编指令,可以使用命令“display /i $pc”,其中 $pc 代表当前汇编指令,/i 表示以十六进行显示。)
此后程序再中断时,就可以显示出汇编代码了此时应该看到“n = 1;”对应的汇编代码是“movl $0x1,0x1c(%esp))”。
并且以后程序每次中断都将显示下一条汇编指定(“si”命令用于执行一条汇编代码——区别于“s”执行一行C代码
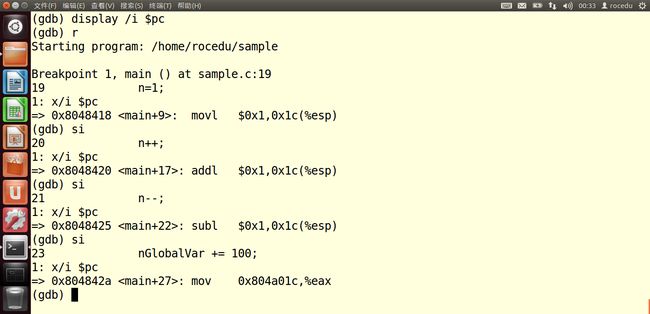
接下来我们试一下命令“b *<函数名称>”,为了更简明,有必要先删除目前所有断点(使用“d”命令——Delete breakpoint),当被询问是否删除所有断点时,输入“y”并按回车键即可。
使用命令“b *main”在 main 函数的 prolog 代码处设置断点(prolog、epilog,分别表示编译器在每个函数的开头和结尾自行插入的代码)


此时可以使用“i r”命令显示寄存器中的当前值———“i r”即“Infomation Register”

也可以显示任意一个指定的寄存器值:
