搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序.
下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试.
有多少种Debug方式
Hadoop在Eclipse上的Debug方式
一般来说, Debug最多的应用场景是调试MR中的代码逻辑, 还有部分是调试main方法中的某些代码逻辑.
无论是Standalone, Pesudo-Distributed, 还是Fully-Distributed Mode, 都可以debug.
特别值得一提的是, 如果仅仅为了验证代码逻辑, 即使没安装hadoop, 也可以在Eclipse中Debug, 姑且称为免安装Debug.
几种Debug方式的比较:
- 免安装Debug(推荐)
最简单的Debug方式, 可以随意选择需要的hadoop版本.
优势: 完全独立于你的hadoop安装环境, 无需对现在的hadoop安装环境做任何更改.
即使在Windows主机上, 也可以直接Debug. (遇到需要输入路径的地方会比较麻烦, 需要想办法转化成Linux路径或者直接在main函数中用hardcode代替入参)
- Standalone
几乎和免安装debug方式一模一样. 也是使用本地文件系统, 所有的进程都在本地JVM中. Eclipse可以直接Remote Debug.
不同之处:
1. Standalone使用安装路径下的hadoop jar包, 而免安装模式是从外部下载导入需要的hadoop jar包.
2. Standalone需要修改hadoop启动脚本.
- Pesudo-Distributed
和Standalone一样, 此时所有的daemon也都运行在一个JVM中.
不同之处:
1. 使用hdfs而非本地文件系统
2. 必须修改hadoop启动脚本才能debug进main函数. 如果要debug MR, 必须在mapred-site.xml中添加 "mapred.child.java.opts" property.
- Fully-Distributed
这种模式下要debug是比较棘手的.
Debug到main函数没有问题, 但是要进入MR代码就比较吃力. 因为Job会被分到NameNode的JVM上运行, 所以Remote Debug需要知道/猜测哪个NameNode会运行task. 操作难度很大, 除非很必要, 不然不建议在这种模式下debug.
- Hadoop-Eclipse-Plugin
原理还是一样的, 只是把修改伪分布式配置的步骤, 改成配置插件来解决, 避免了对安装环境的修改.
根据你的安装设置, 把插件配好:
Map/Reduce Master Host: localhost , Post: 9001
DFS Master Host: localhost, Post: 9000
User name: hm
对号入座, 参考core-site.xml等文件填写dfs.data.dir, dfs.name.dir, dfs.tmp.dir 等等.
mapred.child.java.opts也一定要设置好.
下载地址: https://github.com/winghc/hadoop2x-eclipse-plugin
图文攻略: http://www.powerxing.com/hadoop-build-project-using-eclipse/
下面分别讲讲各中debug方式下如何具体操作.
为了方便调用现有的hadoop jar包, 我选择在安装有hadoop的虚拟机上安装Eclipse并debug.
搭建Linux开发环境
安装Eclipse 4.4
下载Eclipse Luna安装包, 解压到/opt目录
[hm@master ~]$ sudo tar -zxvf eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz -C /opt
建立符号链接, 方便命令行启动
[hm@master ~]$ sudo ln -s /opt/eclipse/eclipse /usr/bin/eclipse
添加快捷方式到Applications
vi /usr/share/applications/eclipse.desktop [Desktop Entry] Encoding=UTF-8 Name=Eclipse 4.4.1 Comment=Eclipse Luna Exec=/usr/bin/eclipse Icon=/opt/eclipse/icon.xpm Categories=Application;Development;Java;IDE Version=1.0 Type=Application Terminal=0
也可以通过桌面右键create launcher来创建.
此时快捷栏里可以看到:
在Terminal中输入eclipse或者通过上面的快捷方式启动Eclipse.
如果下载安装非JEE版本, 则通过Marketplaces自行安装配置Egit, Maven等等必要插件.
获取MapReduce Example代码
可以通过多种途径获得Hadoop MapReduce Examples的source code
1. 直接在hadoop安装目录下找: ~/hadoop/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.2-sources.jar
2. SVN http://svn.apache.org/viewvc/hadoop/common/trunk/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/
免安装Debug
这个是重点, 大部分时候我们只需要这种debug就好. 这里以自带的wordcount为例:
新建Java Project.
从Example拷贝WordCount.java的内容, 放到自己的Java Project中以便debug.
创建input文件夹, 随意放入一些文本文件.
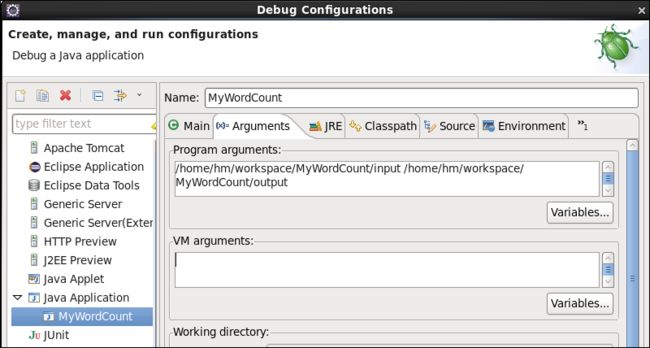
在debug选项中设置input output
对于Hadoop 1, Project上右键property->java build path->libraries->add external jars, 添加:
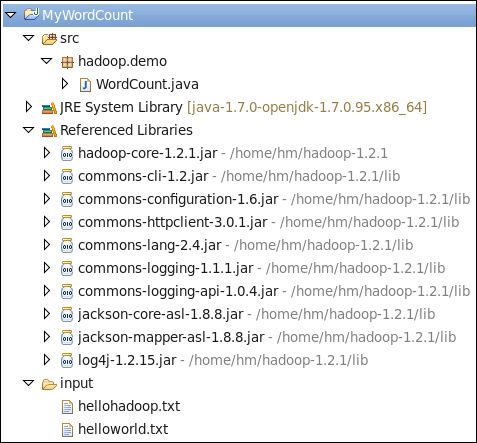
如果是hadoop 2.x版本, 则添加:

区别在于2.x版本不再用hadoop-core这个jar包, 分拆成hadoop-common和hadoop-mapreduce-client-core等等jar包.
可以在Map和Reduce函数中设置断点, 点击debug即可进入断点调试.
Standalone Mode Debug
和免安装模式一样. 在Eclipse Debug Configuration中, 选择"Remote Java Application", 而非"Java Application"进行debug.
此外需要修改安装目录下bin/hadoop文件, 添加: (端口自己随意设置, 不冲突即可)
HADOOP_OPTS="$HADOOP_OPTS -agentlib:jdwp=transport=dt_socket,address=8883,server=y,suspend=y"
在本地设置好input(e.g. 安装目路下新建input文件夹, 放入几个txt文件), 运行命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.2.jar wordcount input/wordcount output
在Eclipse上启动remote debug (端口和bin/hadoop中设置一致, 如果不是在虚拟机本机debug, 把localhost替换成ip或者hostname即可):

此时即可debug到main和MR代码.
Pesudo-Distributed Mode Debug
首先格式化NameNode.
如果要debug main函数, 和Standalone一样修改bin/hadoop, 运行即可.
如果要debug MapReduce代码, 必须修改mapred-site.xml, 添加:
<property>
<name>mapred.child.java.opts</name>
<value>-agentlib:jdwp=transport=dt_socket,address=8887,server=y,suspend=y</value>
</property>
新建一个Remote Debug configuration, 把端口设置为8887.
然后启动sbin/start-dfs.sh, 可以看到log中提示8887端口已被监听.
再启动sbin/start-yarn.sh. 运行命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.2.jar wordcount input/wordcount output
依次启动两个Remote Debug, 即可对相应代码进行调试.
一点小技巧
如果觉得经常修改hadoop启动命令不方便, 可以考虑在最后加一个自定义参数, 比如取名叫"debug":
debug=${!#}
#eval "debug=\$$#" #这样写也可以
if [ "$debug" = "debug" ]; then
HADOOP_OPTS="$HADOOP_OPTS -agentlib:jdwp=transport=dt_socket,address=8887,server=y,suspend=y"
fi
这样只有启动命令输成
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.2.jar wordcount input/wordcount output debug
才会进入debug模式. 否则正常启动.
但是, 对于像wordcount这样的程序, 会自动把最后一个参数当场output, 其他参数全部当作input. 这样就没法正常运行了.
这时需要去修改main函数的逻辑, 或者可以复制一个hadoop启动文件, 命名为hadoop-debug, 要运行debug, 就从这里启动.