Hermes实时检索分析平台
一、序言
随着TDW的发展,公司在大数据离线分析方面已经具备了行业领先的能力。但是,很多应用场景往往要求在数秒内完成对几亿、几十亿甚至几百上千亿的数据分析,从而达到不影响用户体验的目的。如何能够及时有效的获取分析结果提高工作效率,这是许多分析人员在面对大数据所不得不面临的问题。要满足这样的需求,可以采用精心设计的传统关系型数据库组成并行处理集群,或者采用一些内存计算平台,或者采用HDD的架构,但是这些都无疑需要比较高的软硬件成本。海量数据的今天,堆机器不是每个业务都愿意去做的。
实时检索分析平台(Hermes),旨在为公司大数据分析业务提供一套实时的、多维的、交互式的查询、统计、分析系统,为公司各个产品在大数据的统计分析方面提供完整的解决方案,让万级维度、千亿级数据下的秒级统计分析变为现实。
本文将粗略介绍系统的应用场景、设计架构以及相关业务接入情况。
二、Hermes实时检索分析场景

营销分析

作为营销人员,首先你需要确认营销目标群体,并且在什么时间以什么形式,开展什么营销活动效果最好?你首先需要找到目标群体号码包,通过指定条件(如性别、年龄、兴趣爱好,曾经有过类似行为)提取号码包;通过大数据分析,得知在某个时间段参与人数较多,哪种类型的活动效果更受欢迎,目标用户群体有哪些共同特征。掌握这些,你的营销活动效果更加好;
系统运营分析
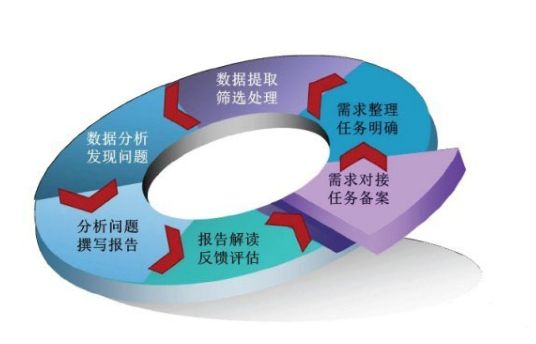
一个产品的后台有着成千上万个接口,各个接口的性能指标是开发人员、运维人员特别关注的,每个接口可能都有不同的版本号,要判断系统是否稳定不是某个时间点的数据能体现出来的,需要对比分析历史数据才能发现潜在的问题。也许问题只出现在某个接口的某个版本中,并且只有特定版本的接口发送到特定接口才会重现这种问题,开发人员除了大量的日志外,没有很直观的途径能指导开发人员有针对性的定位问题。
如果对这些性能数据进行实时的多维度的数据分析,只需要根据问题的表象分析对应的版本号、对应的接口就能查看到对应的性能数据指标,从而快速缩小问题发生范围,为问题定位提供高效的解决途径。
此外不同版本性能的周期性对比、新版本上线性能跟踪等都是系统运营分析所不可或缺的。
趋势分析

当面对每天几百几千万的数据,mysql等传统的数据库能帮你搞定,但是当你要分析周期性数据, 比如最近三十天,这个数据量,也许你没疯mysql就已经"疯"了。
当要分析的数据按月按年计算呢?肯定很多人考虑hadoop,没错,它是能帮你解决这么大的数据量的分析工作,但是hadoop不能让你即查即所见?一个分析人员效率高低,很多时候取决于工具的时效性,这直接影响着分析人员、运营人员的分析思维连贯性。
探索性分析
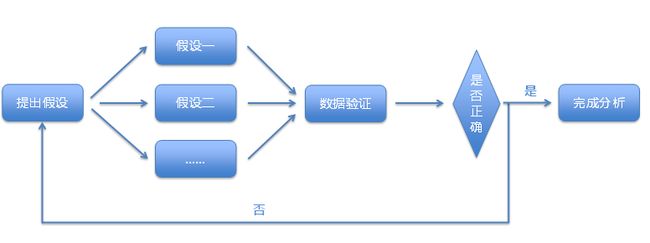
很多分析人员分析的目的是验证性的、是探索性的,在不断的调整验证自己的猜想最终发掘有效信息从而为产品发展找到决策性数据依据。
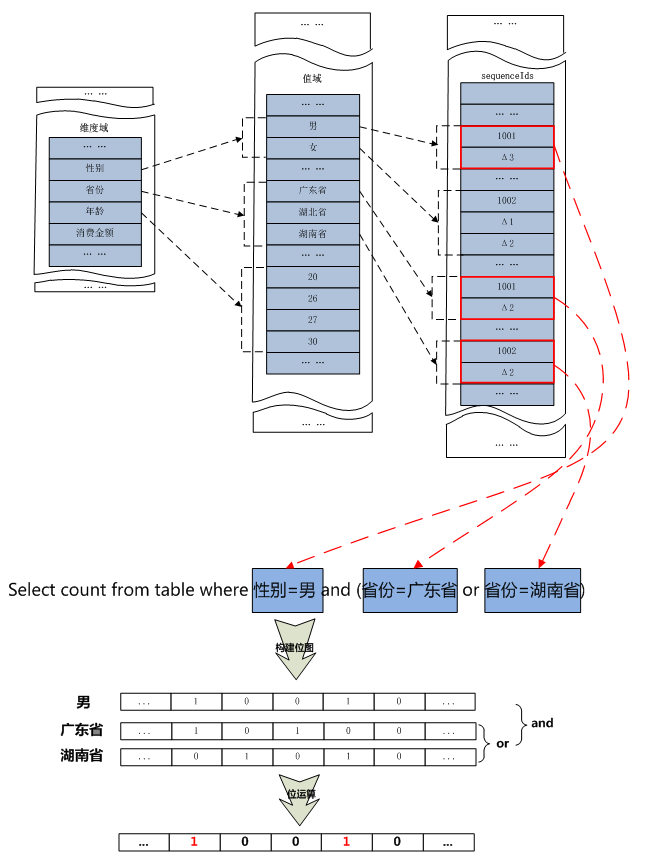
假设你有10亿的数据量,字段数达到上百个,分析人员任何一个YY分析需求都有可能是这上百个字段其中的组合,假设我们从中取5个字段做组合分析,100个字段中取五个字段的组合数能达到75287520,每次查询就算耗时500毫秒,预处理也要430多天。可见,任意组合的查询分析、即查即所见的多维组合分析是探索性分析必需具备的”硬件”条件。
全文检索
很多场景需要根据关键字对数据进行实时检索服务, 目前我们支持数据的实时接入,也支持数据的批量导入。除此高效的毫秒级检索分析服务外,我们还支持用户对结果集的导出。
三、Hermes设计概要
架构描述
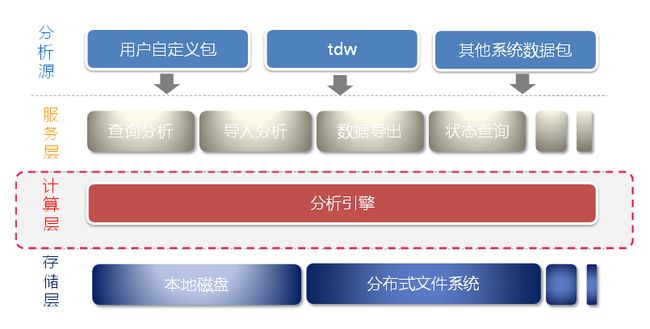
系统核心进程均采用分散化设计,根据业务发展需求,可随意扩缩容机器;
周期性数据直接通过tdw处理落地到分布式文件系统; 实时数据加载采用先落地本地磁盘,最终落地到分布式文件系统,最终都由调度进程分发到计算层;
分析引擎设计
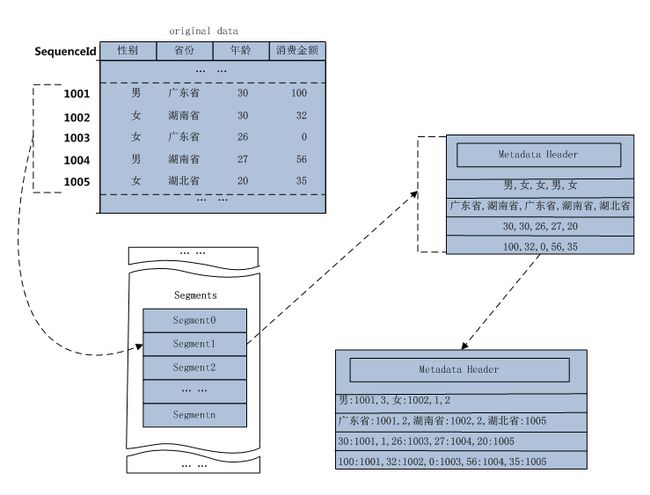
基于单个实例数据的分析处理,datasource主要包含两类数据:用户导入的数据(位图文件)以及源数据(索引文件),内核主要根据用户请求逻辑处理索引文件以及位图文件。
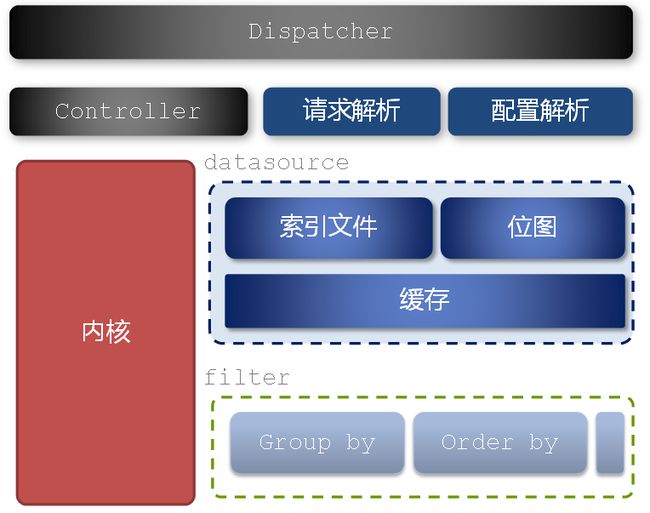
内核设计

整个数据对应多份,按照不同规则均匀分布在各个分析实例中,数据的merge服务在其中的一个分片中进行,每次请求将根据机器负载情况选择负载轻的作为merge服务器。
存储设计
通过对数据结构的重新组织,结合分析系统的特点,实现嵌套列存储,充分避开随机读,采用块读取+位图计算大幅度降低耗时弊病,使大数据的统计分析计算耗时缩短至秒级;
在词条文件中采用字典排序,并在此基础上实现前缀压缩;
在序列文件中采用递增排序,并对序列号采用可变长类型,有效压缩存储空间,便于计算位图的构建;
存储格式
存储格式主要包含四类文件
meta文件: 描述表结构,内存文件;
词条文件: 描述各个字段的词条集信息,磁盘文件;
词条索引文件: 词条文件的跳表映射文件,用于加速定位目标词条,内存文件;
序列号文件: 词条出现的序列集,采用可变长类型存储序列号, 每个词条对应的序列号集又包含跳表映射数据块,用于加速具体序列的定位,磁盘文件;

存储分析过程示例
 流程设计
流程设计

数据容灾:根据业务特点,采用分布式文件系统或冗余存储解决。
进程容灾:根据进程的特殊性,采用Master-Slave或者冗余解决进程容灾问题。
数据加载支持实时和周期性两种方式。
数据接入

实时数据服务:提供数据实时接入,保证数据即入即所查。
历史数据服务:提供T+1数据以及数据补录等场景,保证数据有效周期。
四、Hermes应用案例
微信数据门户多维分析 (约370亿)
提供系统各个性能指标数据的实时分析。
信息安全部回溯项目(目前接入约2300亿)
基于全文检索查询、分析、统计并导出相关记录。
结果秒级返回。
五、Hermes性能数据

六、结束语
数据的不断膨胀给数据分析带来了很多挑战,多维分析则是为了解决在数据不断膨胀的情况下数据分析时效性的问题,为数据分析平台提供即席的数据分析支持。
在业务实践的同时,我们仍在不断完善,使Hermes平台支持更多的应用场景,为提高开发人员、营销人员和数据分析人员数据分析效率,从海量的业务数据中挖掘有价值的金矿而努力。
转自:http://data.qq.com/article?id=817