HashTable浅析
本文转载自: http://rock3.info/blog/2013/12/05/hashtable%E6%B5%85%E6%9E%90/
一、Hash特点
Hash,就是杂凑算法,Hash(str1)=str2,具备四种特性:
- 长变短:Hash算法可以将任意长度的数据Hash成固定长度的数据。
- 速度快:Hash算法基本上是异或和位移操作,速度很快。
- 不可逆:由hash结果找到hash前的字符串是困难的。
- 低碰撞:存在这样的情况,Hash前输入不同,Hash后输出相同,但绝大多数情况是输入不同,输出不同。
二、HashTable
据《算法导论》上讲:“很多应用中,都需要一种动态的集合结构,它仅仅支持INSERT、SEARCH和DELETE字典操作...实现字典操作的一种有效的数据结构为散列表(Hash Table)...在散列表中,查找一个元素的时间与在链表中查找一个元素的时间相同,最坏情况下都是O(n)...散列表是普通数组概念的推广...”。也就是说,Hash Table是为了解决动态的插入、搜索、删除等操作,而专门设置的一种数据结构,目的为了降低这些操作的时间复杂度。
这里面有个“字典操作”,“字典”模型时这样的:通过某个关键字,能够查到该关键字相关的信息,比如通过身份证号,可以查到姓名、性别、年龄、婚否等信息。这样,就抽象出两个关键的部分key和value,身份证号码——key,姓名、性别、年龄、婚否——value。考虑普通的数据存储方式——数组和链表,来存储key和value,先假设指有100个元素,对于数组通常这样存:
struct person {
char key[128];
struct value v;
}p[100];
对于链表这样存:
struct person_list{
struct person_list *next;
char key[128];
struct value v;
};
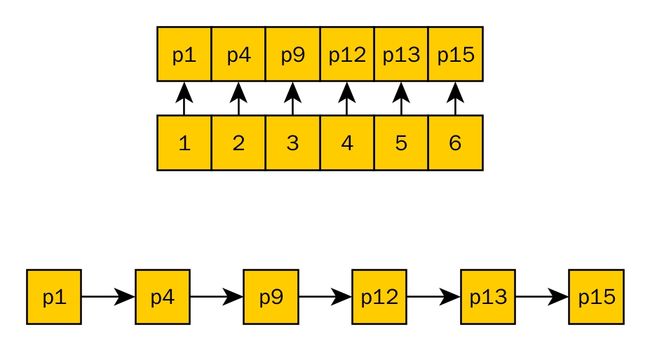
下文中,将上图中的1,2,3,4,5,6这样的数组节点称为“数组节点“,而对p1,p4,p9,p12,p13,p15这种具体的代表key和value的结构体链表节点,称为Entry。
对于INSERT、SEARCH和DELETE,以及存储空间的影响(假设key两两不同,插入、搜索、删除均以key为对象):
为了平衡数组不易插入,链表、数组均不易索引的问题,很容易想到将key值转化为数组的下标、建立一个映射(将字符串转化为整数,或者直接就是整数,先这么简单理解,这也可能产生碰撞),然后再通过指针的方式指向具体的元素,即能快速查找,又能方便插入、删除:
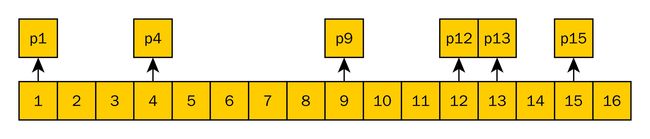
这实际上已经有了Hash Table的原型:“横向数组,纵向链表”,key到下标的映射就是Hash Table中的hash。下面的样子显得更“好看”一些,这就是一种常见的Hash Table实现:

横向数组的下标为key的hash值,纵向链表为hash值相同的元素组成的链表(这里就是举个例子,hash不会产生非常多的碰撞,hash值也的长度也是较长的)。这样做有如下好出:
- 由于hash计算速度快,对于任意一个key,可以快速的找到其所属的链表(O(n),n为hash数组的长度)。
- 在链表里进行插入、删除操作,比较方便(O(a),取决于链表中元素的个数a)。
- 整体上可以将查找的时间复杂度从原来的O(x)降低到O(1+a),其中x为原来Entry的条目数量,a=x/n,也即平均每个链表元素的个数,也叫装载因子。
但是毕竟由于碰撞的存再,使得搜索的时间复杂度没能够达到O(1)。Hash Table的一个关键工作就是尽量的降低碰撞。
四、“链接法”和“开放寻址法”
上面一个图画得就是“链接法”:对于碰撞,选择在相同的数组节点上建立链接。还有一中方法来处理“碰撞”——“开放寻址法”(时间复杂度更低):每个数组节点上就一个元素,如果待插入的Entry计算出来的hash值所在的数组节点非空闲(已经有一个Enry了),就采取某种方法再选择一个空闲的数组节点,插入该Enry。这种情况下,整个数组必须支持动态扩容:当数组空闲节点低于一个阀值时,将扩展数组容量为原来的一倍。这个阀值通常是0.72,也即数组节点有72%的比例为非空闲,就需要将数组扩容至原来的2倍。
“开放寻址法”中如何找到下一个空闲数组,有以下几种方法但并不局限于以下方法,这里就不展开了:
- 线形探查
- 二次探查
- 双重散列(较好)
五、HashTable的搜索复杂度
HashTable平衡了查找速度、插入速度,但是某些情况下,碰撞是不可避免的,只要有碰撞存在,就无法使搜索的时间复杂度达到O(1)。
对于“链接法”,搜索的时间复杂度为O(1+a),a为转载因子。而对于“开放寻址法”,因为每个数组节点上就1个Entry,基本上能够达到O(1)。
还有一种“完全散列”最好,能够使得最坏的情况时间复杂度仍然为O(1),这里就不讨论了。
因此,如果简单的用一下hash table,可以采用“链接法”,如果追求速度,或者数据量比较大,应该采用“完全散列”或者“开放寻址法”(我猜的,没验证)。
六、HashTable的应用
估计,HashTable肯定会应用到数据库的实现中,数据库是典型的字典模型。另外HashTable在Linux内核中也有应用,很多场景均使用了hash table(hlist),如tasklet、页表维护等,其类型定义于include/linux/types.h:
|
1
2
3
4
5
6
7
|
struct
hlist_head {
struct
hlist_node *first;
};
struct
hlist_node {
struct
hlist_node *next, **pprev;
};
|
Linux内核中的hlist采用的是”链接法“,此处不展开了。
七、总结
java里有HashMap这个词,看了一些文章,感觉与《算法导论》上说的Hash Table没有太大的区别,只不过是java的一种实现而已,java里面也有一种叫做HashTable的,是散列表的不同实现。
HashTable是根据Hash的特点去解决这种问题:海量数据的索引、插入、删除时,可以先hash一下,将海量数据进行分块,然后再进行搜索、插入、删除等操作,以便降低时间复杂度。在最好的情况下,能够将时间复杂度降低到O(1)。
HashTable的“横向数组、纵向链表”的样子,可以以“链接法”解决时间复杂度的问题,也可以以“开放寻值法”解决时间复杂度的问题,后者每个数组节点上就一个元素,hash后在相应的数组节点位置顺序向后查找,在找到的第一个位置插入该元素,这种情况下,整个数组必须支持动态扩容:当数组空闲节点低于一个阀值时,将扩展数组容量为原来的一倍。这个阀值通常是0.72。
实际上Hash以后可以接多种数据结构,HashTable就是接的链表,如果衔接树也是可以的,就是HashTree。
存疑:
1、我列的hash特点是传统的md5、sha1等hash算法的特点,hash table中用的hash算法比md5、sha1要简单很多,可能有一定的区别。
2、感觉对hash table的理解还是不太到位,《算法导论》上比较关注hash的构造方法,怎么才能构造出好的hash,但在我理解,hash就是一个使用O(1)时间完成长变短的操作,至于分布是不是均匀,那就看设计了,设计的好一些可能更均匀吧(还得看输出,不仅仅是hash算法本身),但不好也就哪样了。但是《算法导论》上认为分布是否均匀与查找的时间复杂度密切相关,而且应该尽量避免碰撞的情况,并给出了几种处理碰撞的方法。
3、关于hash的设计的方法和技巧,如何能够更加均匀分布,如何尽量快,如何碰撞少,不列了,可能里面涉及比较多的数学知识。