Notes of RDD
Motivation
Since now with the preparation on Java I/O, some fundamental concurrency and parallel computing concepts, some fundamental concepts of distributed algorithms and systems, including distributed coordination etc, I think I am ready for studying the data processing algorithms and systems .
As a newbie, there is no shameless when borrowing or stealing the ideas from the giant. The important is that, how do I want to learn these amazing ideas.
There are a lot of materials about frameworks, such as Hadoop, Storm, Spark, etc, applications, such as Dubbo, Apache Kylin, OpenNLP, Mahout. etc. While these efforts may build or document for ease the life of product developers, the ideas behind these efforts are not so clear.
This note records the first struggle to gain knowledge about data processing model by reading the associated paper.
The technical report paper is Matei Zaharia. An Architecture of Fast and General Data Processing on Large Clusters. 2014.
Progress
- 2015.11.26 first paper skimming
- 2015.12.20 first running Spark1.5.2 examples
- 2016.01.10 init notes
- 2016.01.17 read Spark1.5.2 Programming Guide, collect Spark website materials, and start reading the paper again
Outline
- 1 Introduction
- 2 RDD concepts
- 3 RDD implementation in Spark
- 4 Model based on RDD: Shark
- 5 Model based on RDD: D-Stream
1 Introduction
1.1 论文陈述
基于RDD(resilient distributed datasets)的通用执行模型,可以有效的支持多种分布式计算。
1.2 范围和基础
大量数据的处理需要在组织内部引入集群。随之而来的集群环境中的编程模型带来两个挑战:并行化和容错。并行化在将串行算法重写为并行算法的同时,需要考虑兼容或者支持能够捕获一系列计算特征的编程模型。容错不仅要求考虑失败节点以及随之而来的失败检查和失败恢复、还需要考虑落伍者(stragglers),慢速的节点会成为应用的性能提升的障碍。
已经存在一系列专为集群环境设计的编程模型。鉴于文中尝试归纳的编程模型有:批处理、交互式(迭代式)计算、关系查询、流计算,文中陈述现有工作和比较的框架有:
迭代算法: Pregel, HaLoop, Twister, GraphLab, PowerGraph model, GraphX, Giraph
关系查询: Shark, F1, Dremel, Impala, Amazon Redshift DBMS
MapReduce系: DryadLINQ, interactive MapReduce
流处理: D-Stream, MillWheel, Storm, Impala, Piccolo, GraphLab
是否存在或者能够建立一个通用的编程模型,不仅可以抽象和刻画不同的工作负载计算的特征,还有足够的可扩展性能够应对随时出现的新型工作负载计算?
1.3 承诺
论文提出RDD,一个MapReduce框架的扩展,添加了高效的资源共享原语,极大的提升了模型的通用性。
与现有系统相比,可以具备的关键特征有:
支持多计算类型 在同一运行时环境中支持批处理、交互式、迭代式和流式计算,以及混合使用这些计算类型的应用,同时提供足够高的性能。
支持容错 以较低的成本提供上述计算类型上的节点失效、节点运行缓慢协调和处理能力。
满足性能要求 基本上达到甚至超越MapReduce系框架的性能。
支持多租户 支持多租户场景,允许应用弹性扩展、以可响应的方式共享资源。
MapReduce框架不适合于迭代式、交互式和流式查询的根本原因在于缺少跨并行计算阶段的高效数据共享机制,而RDD提供了高效的数据共享抽象和类MapReduce操作,可以在高效的表达这些工作负载的同时,能够实现现有专有系统中关键的优化努力等同的效果。
之前的容错处理模型将计算组织成任务的DAG(directed acyclic graph),在错误恢复时只需要重播部分的DAG。但由于这些模型中没有关于数据存储的抽象机制,重播的执行往往需要通过数据副本来支持。RDD是具备容错能力的分布式内存抽象,可以避免数据副本。与批处理计算模型类型,每个RDD会记住生成它的操作图,在因节点失效而引起数据丢失时可能很容易的被重新计算出。
从模型表达能力视角来看,RDD可以模拟任意的分布式系统,在容忍网络延迟的假设下表现的足够高效。从系统体系结构视角来看,与MapReduce系框架相比,在优化集群计算中瓶颈资源方面,为应用提供了更多的控制能力。
2 RDD concepts
2.1 定义
RDD是只读的记录分区集合。RDD只能够在两类资源上使用确定性的操作创建:(1) 稳定存储中的数据;(2) 其他RDD。将这些操作记为转换(transformation)。
RDD不需要每次被物化(materialized)。实际上,RDD中有足够的有关它的分区数据是如何从其他数据集中计算出的信息(世系(lineage)信息)。
用户可以在RDD上指定存储策略(storage strategy)和分区方式(partitioning)。存储策略很好理解,Spark默认在内存中存储RDD,在内存不足时才存储在磁盘上。分区方式的含义是,基于基于记录中的键,将RDD中的元素在集群机器上分区,这为联接两个数据集提供了便利。
另一类RDD上的操作被称为动作(action),其操作结果或者是一个值、或者是将数据导出到存储系统中。Spark仅在首次遇到RDD上的动作时才开始计算RDD中元素,这种惰性计算方式将转换操作管道化(pipeline),可以提供计算执行方案的优化。
2.2 RDD与分布式共享内存的比较
在分布式共享内存系统(distributed shared memory(DSM) system)中,应用可以在一个全局地址空间中读写空间中的任意位置。
RDD只能通过粗粒度的转换操作创建(即写),而DSM允许读写任意内存位置。
RDD的不可变特性可以帮助系统以类似于MapReduce中备份处理运行缓慢的任务的方式,处理运行缓慢的节点。而备份运行方式在DSM系统中,因可能存在原任务和备份任务对同一内存位置的访问,跟踪和解决内存干扰是比较困难的。
此外,与DSM相比,建立在基于粗粒度块操作的RDD之上的运行时系统可以很容易的利用数据本地化计算来提升性能。在内存不足时,RDD上的操作可以表现的如基于扫描的操作。
3 RDD implementation in Spark
尽管论文中指出RDD的实现不一定需要函数式编程语言,但从Spark提供的RDD操作接口来看,还是深深的打上了函数式编程的烙印。
3.1 RDD API
在Spark实现中,数据集被定义为对象,转换操作被定义为对象上的方法。
程序员可以通过转换稳定存储上的数据定义RDD,常见的转换操作(transformations)有map、 filter等。也可以执行RDD上的动作(actions),动作是返回一个值或者将数据导出到存储系统的操作,常见的动作有count、collect、save等。
此外,可以在调用RDD上的持久化方法(persist),指定这些RDD会在后续的操作中被重用。
3.1.1 一个示例应用
日志错误查看程序(与论文中程序不一致,在Spark1.5.2上测试运行通过)
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object ConsoleLogMining {
def main(args : Array[String]) {
// data
val logFile = "/home/zhoujiagen/workspace/spark/ConsoleLogMining/data/log.out"
// configuration and context
val conf = new SparkConf().setAppName("Console Log Mining")
val sc = new SparkContext(conf)
// application operations
val lines = sc.textFile(logFile, 2).cache()
val errors = lines.filter(_.contains("ERROR"))
errors.persist()
// application output
println("errors' count is: " + errors.count())
// errors about mysql
val errosAboutMySQL = errors.filter { _.contains("MYSQL") }
println("errors about mysql count is: " + errosAboutMySQL.count())
// errors about HDFS, retrieval the event time
val errorTimesAboutHDFS = errors.filter { _.contains("HDFS") }.map { _.split("\t")(3) }.collect()
for (errorTime <- errorTimesAboutHDFS)
println(errorTime)
}
}其中,关于HDFS的错误发生时间的RDD世系图(lineage graph):
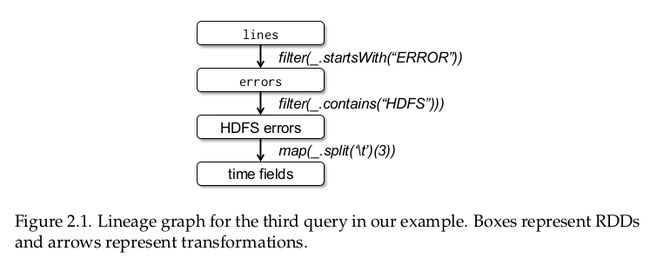
3.1.2 RDD的表示性实现
在具体实现层次,RDD由5个重要的特性刻画(详细细节可以参考RDD Scaladoc):
(1) 一组构成当前RDD中数据集的分区(partitions):
final def partitions: Array[Partition]
(2) 一组对父RDD的依赖(dependencies):
final def dependencies: Seq[Dependency[_]]
(3) 基于父RDD计算出当前RDD中数据的函数(function):
final def iterator(split: Partition, context: TaskContext): Iterator[T]
(4) 关于当前RDD分区方案的元数据(可选):
val partitioner: Option[Partitioner]
(5) 当前RDD中数据放置的元数据(可选):
final def preferredLocations(split: Partition): Seq[String]
有关Spark RDD API的使用说明参见Spark Programming Guide。
3.2 Spark运行时
论文中给出个Spark运行时的原型示意图:
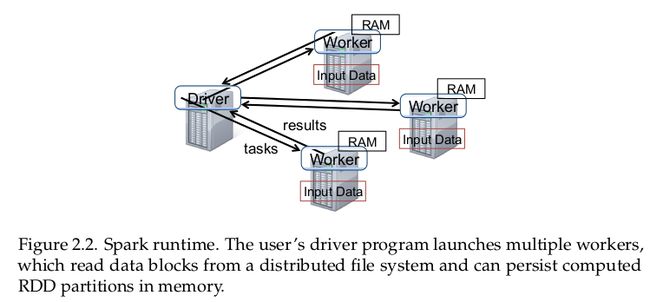
在Spark应用约定中,程序员编写一个驱动程序(driver program),与工作者(worker)集群连接。
在驱动程序中定义一系列的RDD,并调用RDD上的动作类型操作。在驱动程序节点上生成和跟踪RDD的世系图。
工作者是长时间运行的进程,能够跨操作在内存中存储RDD分区。
Spark Cluster Mode Overview中给出了最近的Spark集群模式说明。
文中甄别出RDD之间依赖的两种不同形式:narrow依赖和wide依赖。narrow依赖指父RDD中的每个分区最多只会被子RDD中的一个分区使用,wide依赖指多个子RDD中的分区可能依赖于父RDD中的同一个分区。
3.3 实现细节概述
限于篇幅和论文陈述范围约束,文中仅对实现Spark过程中5个关键部分做了概要阐述。实际上,如果需要详细的引入各关键部分的技术背景和相关工作,每个都是不小的工作量。鉴于此,这里仅记录文中陈述的重要知识点,以期凭借这些"支离破碎"的知识点,努力想象在实现分布式计算框架时有哪些可以依靠的知识和需要付出的努力。
3.3.1 作业调度
Spark的作业调度器使用了RDD的表示性实现。
总体上,Spark的作业调度器与Dryad类似,但考虑了持久化的RDD的哪些分区在内存中可用。
当用户执行RDD上的动作操作时,调度器检查RDD的世系图,以构建需要执行的一系列阶段(stage)的一个DAG。
每个阶段(stage)尽可能的包括narrow依赖的管道化转换操作。阶段之间的边界是一些shuffle操作,这些操作是wide依赖或者父RDD中分区已被计算出的分区所需的操作。
Spark作业调度器基于数据局部性,使用延迟调度策略将任务指派到机器上。如果任务需要处理已在节点内存中可用的分区,将任务指派到该节点上。另外,数据分区所在的RDD中提供了数据存放的元数据(preferredLocations,例如HDFS文件),则将任务指派到数据存放的节点上。
如果任务失败,只要任务的父stage可用则在另一个节点上重新执行任务。如果一些祖先stage不可用,则重新提交任务以并行化计算缺少的分区。
如果任务运行缓慢(即落伍者),则任意的在另一节点上执行备份任务,这与MapReduce的相应机制类似,取最先完成的任务的输出作为任务执行结果。
参考资料
Isard M., et al. Dryad: distributed data-parallel programs from sequential building blocks. 2007.
Zaharia M., et al. Delay scheduling: A simple technique for achieving locality and fairness in cluster scheduling. 2010.
Dean J., Ghemawat S.. MapReduce: Simplified data processing on large clusters. 2004.
3.3.2 多租户
因RDD模型将计算拆分为独立的细粒度的任务,为支持多用户集群中的一系列资源共享算法提供了可能。
Spark支持多个线程并发的提交任务,使用类似与Hadoop Fair Scheduler的层次化公平性调度器,在各任务上分配资源。
Spark的公平性调度器同时使用了延迟调度,通过让任务一次访问每台机器上的数据,在给任务提供高的数据局部性的同时保持公平性。
因任务之间是独立的,Spark调度器同时支持作业取消,从而可以支持基于优先级的作业调度。
使用Memos中资源提供者概念,Spark应用可以提供细粒度的资源共享机制,这使不同的应用使用一个通用的API在集群上加载细粒度的任务成为可能。
最后,扩展Spark使用Sparrow系统,可以支持分布式调度。
参考资料
Isard M., et al. Quincy: Fair scheduling for distributed computing clusters. 2009.
Ousterhout K., et al. Sparrow: Distributed, low lantency shceduling. 2013.
3.3.3 解释器集成
因存在内存中数据访问的低延迟性,使用和扩展Scala提供的解释器,支持用户交互式的运行Spark以查询大数据集。
文中工作对Scala提供的解释器做了两个扩展: 类字节码传输(class shipping)、代码生成(code generation)修改。前者是解释器将交互式Shell中每行代码生成的类通过HTTP暴露给工作者节点;后者是为正确的传输闭包(closure)而做的代码生成修改。
3.3.4 内存管理
Spark提供了三种存储持久化RDD的选项:内存中存储为反序列化的Java对象、内存中存储为序列化的数据、磁盘存储。
为管理有限的内存,使用了RDD层次上的LRU缓���算法。
当前 集 群上每个Spark运行实例有自己独立的内存空间。
3.3.5 检查点支持
尽管RDD世系图可以用于在任务失败是重新计算RDD,但在恢复较长的RDD世系链时耗时较长。在长世系链的某些点上将RDD持久化存储作为检查点,可以削减失败恢复耗时。
通常,检查点在包含wide依赖的长世系链上很有效。
Spark当前提供了支持检查点的API(persist方法中的REPLICATED标志),但将选择检查点数据的决策权留给了用户。
最后,注意到RDD的只读属性,与常见的共享内存系统相比,在生成检查点时较为便利。