python开发学习-day04(迭代器、生成器、装饰器、二分查找、正则)
s12-20160123-day04
pytho自动化开发 day04
Date:2016.01.23
@南非波波
课程大纲:
day03
http://www.cnblogs.com/wupeiqi/articles/5133343.html
day04
http://www.cnblogs.com/alex3714/articles/5143440.html
一、迭代器 && 生成器
1.迭代器
迭代器是访问集合元素的一种方式。迭代器只能往前不能往后。迭代器对象从集合的第一个集合开始访问,直到所有的元素被访问完。
优点:不需要事先准备整个迭代过程中的所有元素
测试代码
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
names = iter(['swht','shen','jack'])
print(names)
print(names.__next__())
print(names.__next__())
print(names.__next__())
返回结果:
<list_iterator object at 0x000000000114C7B8>
swht
shen
jack
2.生成器
定义:generator,一个函数调用时返回一个迭代器,那这个函数就叫做生成器。
作用:yield实现函数中断,并保存函数中断时的状态。中断后,程序可以继续执行下面的代码,而且可以随时可以回头再执行之前中断的函数。
可以通过yield实现在单线程的情况下实现并发运算的效果
测试代码
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def money(num):
while num > 0:
print("取款100元!")
num -= 100
yield 100
print("你当前还有%s元" % num)
ATM = money(500)
print(type(ATM))
print(ATM.__next__())
print(ATM.__next__())
print("吃包子....")
print(ATM.__next__())
print(ATM.__next__())
返回结果:
<class 'generator'>
取款100元!
100
你当前还有400元
取款100元!
100
吃包子....
你当前还有300元
取款100元!
100
你当前还有200元
取款100元!
100
实现异步:【生产者-消费者模型】
yield参数可以实现返回参数和接收参数,使用send方法可以将值传递到生成器中去
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
import time
def consumer(name):
print("%s 开始准备吃包子!" % name)
while True:
baozi = yield #yield可以返回一个值,也可以接收一个值
print("第[%s]波包子来了,被[%s]吃了!" % (baozi,name))
def producer(name):
c1 = consumer('swht')
c2 = consumer('shen')
c1.__next__()
c2.__next__()
print("==%s开始准备做包子!==" % name)
for i in range(10):
time.sleep(1)
print("**%s做了两个包子!**" % name)
c1.send(i) #使用send方法将值传递给yield
c2.send(i)
producer('alex')
返回结果:
swht 开始准备吃包子!
shen 开始准备吃包子!
==alex开始准备做包子!==
**alex做了两个包子!**
第[0]波包子来了,被[swht]吃了!
第[0]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[1]波包子来了,被[swht]吃了!
第[1]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[2]波包子来了,被[swht]吃了!
第[2]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[3]波包子来了,被[swht]吃了!
第[3]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[4]波包子来了,被[swht]吃了!
第[4]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[5]波包子来了,被[swht]吃了!
第[5]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[6]波包子来了,被[swht]吃了!
第[6]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[7]波包子来了,被[swht]吃了!
第[7]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[8]波包子来了,被[swht]吃了!
第[8]波包子来了,被[shen]吃了!
**alex做了两个包子!**
第[9]波包子来了,被[swht]吃了!
第[9]波包子来了,被[shen]吃了!
二、装饰器
装饰器又叫语法塘
装饰器调用原理
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def login(func):
print("To passed!")
return func
def home(name):
print("Welcome [%s] to home page!" % name)
def tv(name):
print("Welcome [%s] to TV page!" % name)
def moive(name):
print("Welcome [%s] to Moive page!" % name)
tv = login(tv) #将tv函数的内存地址传递到login()函数中,然后将tv的内存地址返回并赋给变量tv
tv("swht") #变量调用相当于函数的调用
装饰器实现
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def login(func): #程序执行时返回inner函数的内存地址
def inner(*arg,**kwargs):
print("To passed!")
return func(*arg,**kwargs)
return inner
def home(name):
print("Welcome [%s] to home page!" % name)
@login
def tv(name):
print("Welcome [%s] to TV page!" % name)
def moive(name):
print("Welcome [%s] to Moive page!" % name)
tv("swht")
返回结果:
To passed!
Welcome [swht] to TV page!
多参数装饰器
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def Before(request,kargs):
print('before')
def After(request,kargs):
print('after')
def Filter(before_func,after_func):
def outer(main_func):
def wrapper(request,kargs):
before_result = before_func(request,kargs)
if(before_result != None):
return before_result
main_result = main_func(request,kargs)
if(main_result != None):
return main_result
after_result = after_func(request,kargs)
if(after_result != None):
return after_result
return wrapper
return outer
@Filter(Before, After)
def Index(request,kargs):
print('index')
Index("swht","123")
实现流程
'''
1.程序运行,读取顺序 @Filter --> Index()
2.@Filter运行机制:
1)将Before, After传递给Filter(),执行outer();
2)将Index传递给outer()函数,执行wrapper(),返回outer;
3)将Index()中的两个参数request,kargs传递给wrapper()函数,执行:
1)执行before_func()即Before()并判断返回值,打印before
2)执行main_func()即Index()并判断返回值,打印index
3)执行after_func()即After()并判断返回值,打印after
3.程序结束
'''
三、递归
演示递归进出过程:【栈的实现:后进先出】
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def calc(n):
print(n)
if n/2 > 1:
res = calc(n/2)
print('res:',res)
print('n:',n)
return n
calc(10)
'''
递归进入多少层,最后函数结束退出的时候就是退出多少层
'''
返回结果:
10
5.0
2.5
1.25
n: 1.25
res: 1.25
n: 2.5
res: 2.5
n: 5.0
res: 5.0
n: 10
斐波那契数列
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def sum(arg1,arg2,stop):
if arg1 == 0:
print(arg1,arg2)
arg3 = arg1 + arg2
print(arg3)
if arg3 < stop:
sum(arg2,arg3,stop)
sum(0,1,500)
返回结果:
0 1
1
2
3
5
8
13
21
34
55
89
144
233
377
610
四、二分查找
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
def binary_search(data_source,find_num):
mid = int(len(data_source)/2) #列表折中
if len(data_source) >= 1: #如果列表的长度值大于1,则递归
if data_source[mid] > find_num: #如果中间值大于查找值,这说明查找值在中间值的左侧
print("%s\tis\tthe\tleft\tof \t%s" % (find_num,data_source[mid]))
binary_search(data_source[:mid],find_num)
elif data_source[mid] < find_num: #如果中间值小于查找值,这说明查找值在中间值的右侧
print("%s\tis\tthe\tright\tof \t%s" % (find_num,data_source[mid]))
binary_search(data_source[mid:],find_num)
else:
print("已经查找到\t%s" % find_num)
else: #否则返回值,查找不到
print("查不到该数值!")
if __name__ == "__main__":
data = list(range(1,90000))
binary_search(data,65535)
五、二维数组
二维数组的概念是在c、c++等语言中出现并定义,在python没有数组概念,对应的则是列表。所以我们这里称为二维数组则是对二维列表的称谓。
需求:
转换二维数组
初始列表:
[0, 1, 2, 3]
[0, 1, 2, 3]
[0, 1, 2, 3]
[0, 1, 2, 3]
=================
转换后列表:
[0, 0, 0, 0]
[1, 1, 1, 1]
[2, 2, 2, 2]
[3, 3, 3, 3]
代码实现:
#!/usr/local/env python3
'''
Author:@南非波波
Blog:http://www.cnblogs.com/songqingbo/
E-mail:[email protected]
'''
data = [[col for col in range(4)] for row in range(4)]
# for i in a:
# print(i)
for col in range(4):
for row in range(col,4):
data[col][row],data[row][col] = data[row][col],data[col][row]
for i in data:
print(i)
print(a)
改进型:
data = [[col for col in range(4)] for row in range(4)]
for col in range(len(data)):
for row in data[col]:
data[col][row],data[row][col] = data[row][col],data[col][row]
for i in data:
print(i)
六、正则表达式
熟悉Linux环境的朋友肯定熟悉,用来操作字符或者文本文件时操作的快速匹配语言。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。
语法:
一般字符
匹配自身
示例:
import re
str1 = '23434sjsjdd523^&(csd#@52'
print(re.match('abc',str1))
返回值为:None #说明此时没有匹配到。
print(re.match('23',str1))
返回值为:<_sre.SRE_Match object; span=(0, 2), match='23'> #匹配到自身并返回类型
.
匹配任意除换行符'\n'外的字符,在DOALL模式中也能匹配换行符。
示例:
import re
str1 = '23434sjsjdd523^&(csd#@52'
print(re.match('.',str1))
返回结果:<_sre.SRE_Match object; span=(0, 1), match='2'> #匹配到任意字符'2'
**
转义字符,使后一个字符改变原来的意思。如果字符串中有字符*需要匹配,可以使用\*或者字符集[*]
示例:
a\\c -->a\c
[...]
字符集(字符类).对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。第一个字符如果是^则表示取反,如[^abc]表示不是abc的其他字符。
所有的特殊字符在字符集中都失去其原有的特殊含义。在字符集中如果要使用]、-或^,都可以在前面加上反斜杠,或把]、-放在第一个字符,把^放在非第一个字符。
示例:a[bcd]e -->abe ace ade
预定义字符: 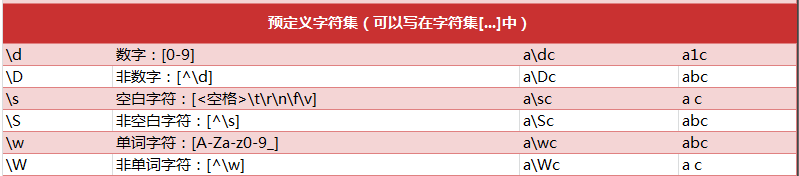
数量词: 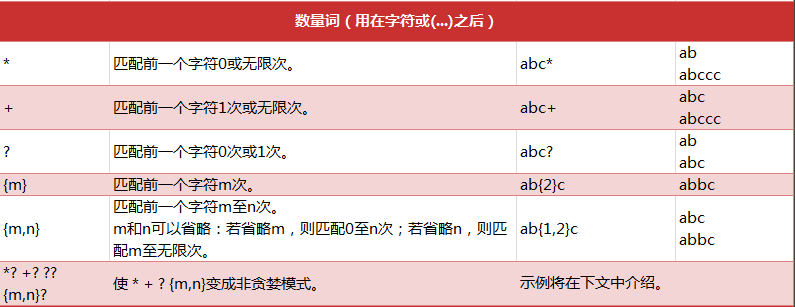
边界匹配: 
逻辑、分组 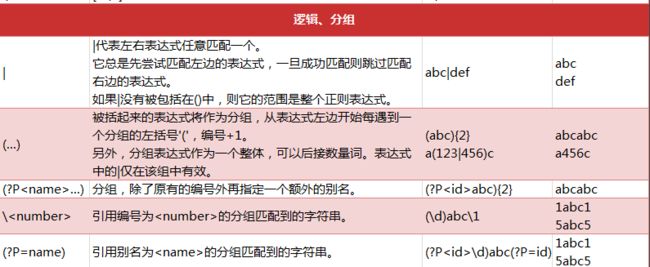
正则表达式模块re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
示例:
import re
test1 = re.compile(r'hello') #使用re.compile编译成Pattern实例
test12 = test1.match('hello world!') #使用Pattern匹配文本,获得匹配结果,无法匹配时返回None
if test12:
print(test12.group()) #使用test12获得分组信息
#输出 hello
#the same as top
m = re.match(r'hello', 'hello world!')
print(m.group())
match
match(string[,pos[endpos]])|re.match(patern,string[,flags]):
从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别是0和len(sring);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
(re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none.)
测试代码:
m = re.match('hello', 'hello world!')
print(m.group())
返回值为:hello
print(re.match('www','www.apicloud.com').span()) #在起始位置匹配
print(re.match('com','www.apicloud.com')) #不在起始位置匹配
返回结果:
(0, 3)
None
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
#.* 匹配任意字符且匹配前一个字符0或无限次
#.*? 匹配任意字符,且匹配前一个字符0或无限次,且匹配前一个字符0次或1次
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
else:
print("No match!!")
返回结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
search
功能:re.search 扫描整个字符串并返回第一个成功的匹配
语法:re.search(pattern, string, flags=0)
参数:pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
测试代码:
import re
print(re.search('www', 'www.apicloud.com').span()) # 在起始位置匹配
print(re.search('com', 'www.apicloud.com').span()) # 不在起始位置匹配
返回结果:
(0, 3)
(13, 16)
import re
line = "Cats are smarter than dogs"
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group())
print("searchObj.group(1) : ", searchObj.group(1))
print("searchObj.group(2) : ", searchObj.group(2))
else:
print("Nothing found!!")
#返回结果:
# searchObj.group() : Cats are smarter than dogs
# searchObj.group(1) : Cats
# searchObj.group(2) : smarter
对比match和search
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
示例代码:
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print("match --> matchObj.group() : ", matchObj.group())
else:
print("match --> No match!!")
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print("search --> searchObj.group() : ", searchObj.group())
else:
print("search --> No search!!")
#返回结果:
# match --> No match!!
# search --> searchObj.group() : dogs
sub
功能:re.sub用户替换字符串中的匹配项
语法:re.sub(pattern, repl, string, max=0)
测试代码:
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num1 = re.sub(r' .*$', "", phone) #匹配' '空格到字符串默认的所有任意字符,删除
print("Phone Num : ", num1) #Phone Num : 2004-959-559 最后一个字符后面没有空格
num2 = re.sub(r'#.*$', "", phone) #匹配#到字符串默认的所有任意字符,删除
print("Phone Num : ", num2) #Phone Num : 2004-959-559 最后一个字符后面有一个空格
# Remove anything other than digits
num3 = re.sub(r'\D', "", phone) #匹配非数字字符,然后删除
print("Phone Num : ", num3) #Phone Num : 2004959559
作业:
计算器开发
1. 实现加减乘除及拓号优先级解析
2. 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式,运算后得出结果,结果必须与真实的计算器所得出的结果一致
博客地址:http://www.cnblogs.com/songqingbo/p/5168125.html