LZW压缩算法
压缩算法
压缩可以分为无损压缩和有损压缩,有损,指的是压缩之后就无法完整还原原始信息,但是压缩率可以很高,主要应用于视频、话音等数据的压缩,因为损失了一点信息,人是很难察觉的,或者说,也没必要那么清晰照样可以看可以听;无损压缩则用于文件等等必须完整还原信息的场合,LZW自然就是一种无损压缩,在通信原理中介绍数据压缩的时候,往往是从信息论的角度出发,引出香农所定义的熵的概念,这方面的介绍实在太多,这里换一种思路,从最原始的思想出发,为了达到压缩的目的,需要怎么去设计算法。 LZW和哈夫曼编码一样,是无损压缩中的一种。该算法通过建立字典,实现字符重用与编码,适用于source中重复率很高的文本压缩。
压缩原理
LZW压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch 三人共同创造,用他们的名字命名。它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图象文件的压缩效率得到较大的提高。奇妙的是,不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。 LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。压缩完成后将串表丢弃。如"print" 字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
算法流程

算法相关的概念和词汇
1)'Character': 字符,一种基础数据元素,在普通文本文件中,它占用1个单独的byte,而在图像中,它却是 一种代表给定像素颜色的索引值。
2)‘CharStream’:数据文件中的字符流。
3)'Prefix':前缀。如这个单词的含义一样,代表着在一个字符最直接的前一个字符。一个前缀字符长度可以为0,一个prefix和一个character可以组成一个字符串(string)
4)'Suffix': 后缀,是一个字符,一个字符串可以由(A,B)来组成,A是前缀,B是后缀,当A长度为0的时候,代表Root,根
5)'Code:码,用于代表一个字符串的位置编码
6)'Entry',一个Code和它所代表的字符串(string)
示例分析
输入流,也就是原始的数据为:255,24,54,255,24,255,255,24,5,123,45,255,24,5,24,54............................... 这个正好可以看到是gif文件中像素数组的一部分,如何对它进行压缩.
标号集,因为原始数据可以用8bit来表示,故清除标志Clear=255+1 =256,结束标志为End=256+1=257,目前标号集为 0 1 2 3 .................................................................................255 CLEAR END
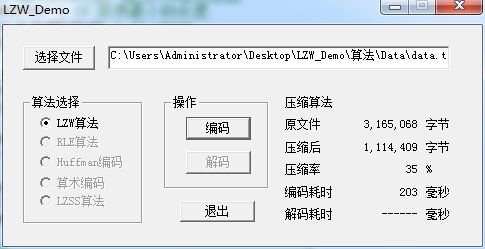
具体步骤
第一步:读取第一个字符为255,在标记表里面查找,255已经存在,我们已经认识255了,不做处理
第二步:取第二个字符,此时前缀为A,形成当前的Entry为(255,24),在标记集合不存在,我们并不认识255,24好,这次你小子来了,我就记住你,把它在标记集合中标记为258,然后输出前缀A,保留后缀24,并作为下一次的前缀(后缀变前缀)
第三步:取第三个字符为54,当前Entry(24,54),不认识,记录(24,54)为标号259,并输出24,后缀变前缀
第四步:取第四个字符255,Entry=(54,255),不认识,记录(54,255)为标号260,输出54,后缀变前缀
第五步:取第5个字符24,entry=(255,24),啊,认识你,这不是老258么,于是把字符串规约为258,并作为前缀
第六步:取第六个字符255,entry=(258,255),不认识,记录(258,255)为261,输出258,后缀变前缀 ....... 一直处理到最后一个字符, 用一个表记录处理过程 CLEAR=256,END=257
运行结果