维护遗留应用的实用技术
遗留应用很少如下面所示:
在这个美丽的图形中,通过定义良好的管道,使得层次和模块块划分清晰,交互便利。模块可以移动,替换,也易于添加,支持那些重要的“特性”:可扩展性,可伸缩性,可维护性……
在现实中,遗留应用更可能如下所示:
如果你是接到维护遗留应用程序任务的不幸开发者,有时你会感到像老鼠在迷宫里;每次开机时,还有更多意想不到的角落和拐弯,甚至是死亡陷阱。
我一直在负责维护这种遗留应用程序已经两年多了,在这篇文章中,我想分享我对如何务实地维护一个大的遗留应用程序的经验。
我强调“务实”,因为遗留应用程序可能有很多的技术缺陷,从技术和经济上说处理所有技术缺陷是不可行的。选择正确的方式需要有策略性。
刺探敌情
我们正在维护的大型的遗留应用程序的简要说明:
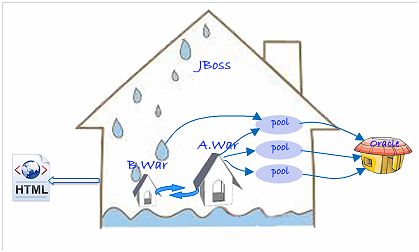
大房子标识JBoss 4.0。出于某种原因,JBoss 4.0以一些不兼容的方式进行了部分调整,使其难以升级。所以房子构建的有些孱弱(内部正在漏雨)。两个小房子代表了部署到JBoss上的两个Web应用程序(两个WAR包)。一个房子要小得多,并提供更小的功能。每一个页面必须由两个房子提供。有三个连接池,两个事务的机制,一是自制缓存,一个自制的集群机制,一是自制的RMI机制等。
维护遗留应用程序的第一步是理解它。我们要了解应用程序的每一个细节是不切实际的,但我们可以了解整体概貌:
- 为什么要用两个WAR包服务于单一页面?两个WAR包相互影响,怎么办?开销是什么?我们如何将它们合并?
- 事务是如何处理的?两个WAR包,三个连接池和两个事务机制间的交互是否存在事务失败的风险?
- 我们如何知道性能瓶颈在数据库中还是在代码中?如果在代码中,我们如何诊断?
静态代码分析或者不充分,或者不准确。我们开发了一些工具来在运行时监视应用程序,回答这些问题。我们谨慎地以附加组件形式执行这些工具:他们与应用程序代码不耦合,所以它们不产生我们必须维护的额外代码。有关这些工具的更多详细技术细节,看看我的博客。
SQLTracer
此工具可以打开任何一个网页,跟踪那个SQL查询产生问题,发生多少次,以及耗费时间。很重要的是,它为这些查询产生TKPROF,用于性能故障排除。
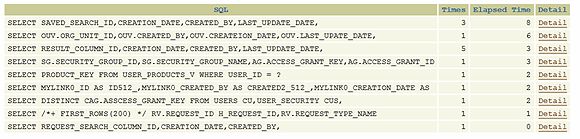
技术细节
SQLTracer 使用如下逻辑探测JDBC操作:如果页面跟踪已经打开并在ThreadLocal存储页面信息,一个页面请求获得javax.servlet.Filter的检查。当连接从连接池取出的,他们的行动是由AspectJ 切面来捕获,跟踪SQL语句,调用次数和运行时间。使用Oracle DBMS_SESSION.SET_IDENTIFIER()的连接都标有相同的标识符,它们的活动是使用dbms_monitor.client_id_trace_enable()跟踪。这种技术允许跟踪不同的连接。
Perfspy
PerfSpy是一个运行时的日志记录和性能监控工具。我们用它来监视独立页面,它会记录方法调用日志,运行时间,方法,参数和返回值,总之,它步进调试和存储的后续检查的一切信息,你没必要在IDE做到步进调试。它的运行时代码分析和诊断性能瓶颈。它有一个应用程序的用户界面,以树形式显示了方法调用,并提供方法来操作树:隐藏节点,搜索节点,标记节点诸如此类。方法的参数和值也表现为树的形式。以下是截图:
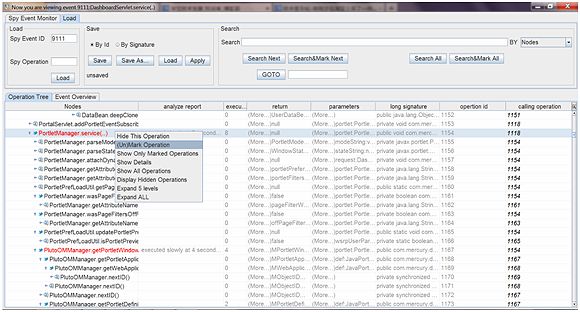
使用该工具,我们可以回答这些重要问题:
- 两个WAR包是如何协调工作的?我们可以得出结论,两个WAR包是没有必要的;它部署复杂,并增加了内存和性能开销,将两个WAR包合并是很容易的事情。
- 三个连接池和两个事务机制如何协调工作呢?最初我们认为,当一些代码初始化一个事务,它会通过交易向下传递,所有操作将在一个事务完成。然而,我们发现,在某些情况下,交易不向下传递,操作也没有在一个的事务中,这可以作为在用户问题中我们发现的很多数据损坏问题的解释。 Perfspy能够提供洞察的能力,因为它记录的方法参数和返回值的详细信息,包括系统的哈希码。因此,在方法调用树中,我们可以看到一个新的连接,Hibernation会话,或一个新的事务开始的时间和位置。
- 某个网页的性能瓶颈是什么? SQLTracer发现在数据库方面的性能问题,通过显示重复的调用和消耗时间,PerfSpy发现的代码方面的性能问题。
技术细节
PerfSpy使用AspectJ来做到运行时监控。 PerfSpy有一个抽象的切面,用于记录,监视和跟踪。一旦该切面生效,将查询配置文件来决定它应该收集多少信息和它应该执行什么代码分析。使用PerfSpy,你扩展PerfSpy抽象切面的切面,在扩展切面中指定代码流程以及你想捕获的代码流程的方法。
通常,应用程序使用一些框架服务于通用功能,应用程序扩展框架来来完成特定操作。例如,Struts 1.2有org.apache.struts.action.Action,它可以被扩展为Web页面操作提供服务。 PerfSpy就是设计来诊断上述框架的。例如,为了使用PerfSpy诊断Struts action,你可以写一个从PerfSpy切面扩展的切面:
@Aspect
public class PerfSpyStrutsAsepct extends AbstractPerfSpyAspect {
//specifies which code flow to spy on
@Pointcut("cflow (execute(* org.apache.struts.action.Action.execute(..)))")
public void cflowOps() {
}
//specifies which methods in the code flow to spy on
@Pointcut("execution(* com.myCompony.myPk1.myPk2.*(..))")
public void withinCflowOps() {
}
}
上述配置文件可以指定哪些具体的Struts action类诊断。通过这种方式,我们可以给单个页面打开和关闭诊断。
BLSpy
BLSpy多用于业务逻辑的诊断。很多时候,我们的用户(有时甚至是我们自己)困惑于我们的遗留应用程序所产生的数据;他们想知道应用程序如何计算这些数据。用户可以对业务数据的单一类型进行诊断。
有了这个工具,现在用户能够无需联系我们就能解决这样的问题。我们自己也使用这个工具判断一些计算缺陷。
技术细节
BLSpy是在PerfSpy之上开发的。 PerfSpy让我们捕捉到计算代码流程,我们以业务词汇向用户表示计算。例如,我们想传达讯息,如“来计算部门A本周的人力资源成本,我们从A部门获取人力资源的时间记录,并发现了杰森曾维护20小时数据库,以及他的时薪是30元……”。要做到这一点,我们标注了参与计算流程的方法的含义,并在运行时,获取意图,并结合由PerfSpy捕获的方法,向用户展示有意义的信息。
有选择的战斗
遗留应用程序可能像雷区。你愿意挖掘每个地方,你会发现比你预期更大的问题。堵住所有漏洞,在技术上和经济上是不可行的。通常管理方很想收缩维护遗留应用程序的人力资源,使其不断变小,因此每项投资都要算计。
每个功能点的缺陷测算有常用指标。许多用户使用应用程序,当他们遇到他们问题,会将日志工单给我们。在工单中,他们选取发生问题的功能点。然而,这个指标是不够的,因为:
- 该指标不能提供架构级缺陷的广阔视野。分类功能问题是很容易的。另一方面,非功能性的问题,如性能问题,可扩展性的问题,以及稳定性问题,尽管他们可能表现在功能点,但根本原因可能越过功能店的范围。例如,在创建订单模块处理慢,或在申诉模块的发起申诉慢,都可能是底层队列机制所造成的。
- 它创造的动机使用“权宜之计”的战术来扭转这个数字。例如,我们的交易机制导致了很多脏数据的问题。通常的“权宜之计”的战术将是直接从数据库删除脏数据或在代码中处理脏数据,这种方式可以迅速提升指标,但都没有改善系统运行状况。
我们决定在常用指标之上创建一个指标,我们称之为“高影响”指标。这个指标主要强调困扰遗留应用程序中影响最大的问题,要求高层管理人员的支持改善遗留应用程序的架构。我们定义的“性能”,“稳定性”,“脏数据”,和其他一些非功能性的问题为“高影响”,因为它们要么需要较长的时间来解决,要么经常招致用户问题升级。我们所有用户报告的问题归类到这些分类。以下是指标的简化示意图:
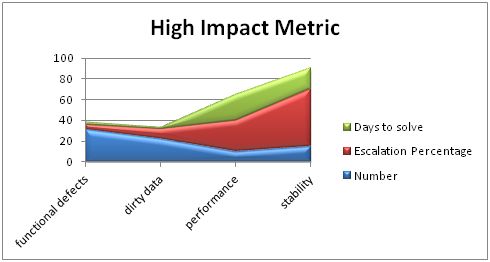
在此图中,尽管功能问题发生最多,但是它们更易于解决,用户不经常升级他们;相反,稳定性问题,尽管他们很少发生,常常引起问题升级,难以解决。用户往往易受稳定性问题困扰,因为它们是随机发生的,甚至疏忽的用户可能不知道什么时间和如何为随机事件做准备。脏数据是一种类型的稳定性问题,我们单独把它列出,是因为脏数据问题经常发生。
用户愤怒(升级)让高层管理人员的重视技术债务,引起他们投资改善遗留应用程序的架构的好方法。
进行战斗
使用“高度影响”指标,我们知道想要解决什么;通过各种诊断工具,我们知道如何深入挖掘遗留应用程序的黑盒,我们准备好迎接战斗了。
因为遗留的应用程序往往很少有单元测试,所以重构遗留应用程序可能是相当危险的。在这篇文章中描述了我们的方法。
结论
维护遗留应用程序是一场持续的战争。使用“高影响”指标,我们选择下一个大仗要打。使用各种诊断工具,我们可以发现敌人的底细。使用我们正在建设和不断完善的测试框架,我们能够征服敌人(重构旧代码)。
关于作者
 陈萍生活在中国上海,于2005年获得计算机科学的硕士学位。毕业后,她工作于Lucent和摩根斯坦利。当前,她是HP的开发经理。工作之外,她喜欢研究中国医学。.
陈萍生活在中国上海,于2005年获得计算机科学的硕士学位。毕业后,她工作于Lucent和摩根斯坦利。当前,她是HP的开发经理。工作之外,她喜欢研究中国医学。.