持续交付:当前普遍存在的三个问题与解决方案
早在2009年,Flickr就分享了他们如何通过工具的支撑和文化的改变,使之能够支撑业务部门“每天部署10次”的要求。这些工具包括:
1) Automated infra
2) Shared version control
3) One step build and deploy
4) Feature flags
5) Shared metrics
6) IRC and IM Robots
5年时间过去了,随着云计算和开源软件的发展,我们拥有了比Flickr更好的基础条件:IaaS给我们提供了可编程的接口,我们不再受到物理资源的约束;GitHub带给我们新型版本控制和代码协作方式; Chef/Puppet等配置和自动化部署工具更加成熟;基于ELK的实时监控和日志系统也很成熟。但是,即便如此,有多少企业达到了Flickr的持续部署和交付水平呢?
这里,我们把持续交付分解成三条主线:
- 从Code到Artifacts仓库;
- 从Artifacts到Running Service;
- 从开发、测试环境到准生产、生产环境。
对于这三条主线,笔者发现大部分IT组织都存在三个类似的问题。
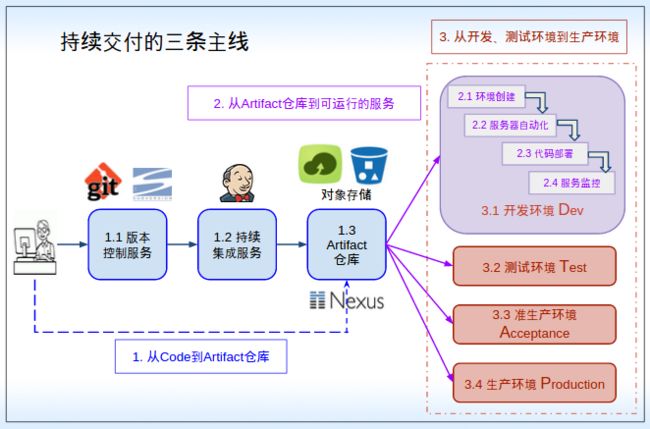
1. 从Code到Artifact仓库:没有统一的Artifacts仓库
在很多企业IT组织中,由于历史及其他各种各样的原因,不同的项目,会采用不同的开发语言、框架,版本控制服务和持续集成工具。这是不可避免的。真正的问题是出在Artifact的管理上。有些人根本就没有Artifact的概念,认为代码就是Artifact,部署应用时都是直接从svn等版本控制器上面直接获取代码进行部署。有些IT组织即便有Artifact仓库,也没有统一的规范,非常混乱。
如何改进呢?
建立统一的Artifacts仓库。这是后续自动化部署和多版本开发的基础。
Artifacts仓库的实现方式有三种,FTP、对象存储(比如阿里云OSS,AWS S3等)和专业的Artifacts存储仓库。对象存储、 FTP都重在存储,只能实现最基础的分目录和权限管理。如果你的环境都在公有云上面,那么用公有云的对象存储服务来管理Artifacts是很合适的,原因有以下几个:
- 不用担心可用性和可靠性;
- 上传和下载速度快;
- 不同的项目可以用不同的Buckets来进行权限管理。如果是AWS S3,还可以使用IAM来进行更细粒度的权限控制。
专业的Artifacts存储仓库方面,目前有三个使用比较广的选择:Artifactory、Nexus和Archiva,其中Artifactory和Nexus也有商业版本。这三个工具虽然都源自Maven,但是他们不仅仅支持Java/Maven,任何项目和语言都可以使用Maven机制来打包Artifact,区分Artifact版本,并最终存储到Repository中去。下图是Nexus的一个截图,可以清楚地看出Artifacts仓库所要解决的几个问题:不同项目、不同组件Artifacts的分类存储;Artifacts格式的统一;用户和权限控制;开发版本和发布版本区分、如何与CI服务器集成等。

2. 从Artifacts到Running service:不同环境的部署方法不一样
这条主线解决的是,如何将Build Artifacts部署到开发环境、测试环境、准生产环境和生产环境。
对于这条主线,当前普遍存在的问题是:不同环境的资源创建、服务器配置和代码部署方法是不一样的。很多时候大家只关注生产环境的部署管理,对于开发及测试的部署管理又不重视。比如,开发和测试环境是手工部署的,而生产环境是用工具进行自动部署的,因为部署方式不一致,所以在生产环境会经常出现不可预知的错误。另外,随着版本分支的增加,开发、测试和准生产环境会混乱不堪。
如何改进呢?
貌似PaaS的存在就是为了解决这个问题,开发人员只要专注于应用的开发,部署和Ops工作都是有PaaS本身完成。然而,现实是目前的PaaS仍然没有进入主流,这是因为PaaS给予太多的限制、很好解决的80%问题,但是剩下20%很难解决。
在云计算(IaaS)支撑下,在云管理和部署工具的支持下(比如Rightscale, Cloudify,AWS Cloudformation, AWS CodeDeploy, FIT2CLOUD),用户可以实现从Artifacts到Running service整个过程的自动化,包括环境创建自动化、虚机安装配置自动化和代码部署自动化。
1) 环境创建:创建VMs、网络、存储、负载均衡,协调不同角色VMs的创建过程和配置。
2) 软件安装和配置:操作系统配置,比如创建用户、组,设置ulimit参数等;基础软件安装和配置,比如Mysql/Nginx。这些软件的特点是变动不频繁。
3) 应用部署(Code Deploy):部署应用代码,比如war包、db脚本、php/rails代码等。这部分的变动是频繁的。开发人员不仅仅是提供代码,而且要提供部署代码所需的脚本,比如AWS CodeDeploy规定Artifact中必须包括的部署这份代码所需要的脚本。CodeDeploy虽然没有编排功能及完备的插件和脚本库(比如HP OO),但是实现了应用代码和部署脚本的统一融合,可以避免多版本同时开发、部署所导致的混乱。采用CodeDeploy,每个应用组件可以单独、持续的继续升级部署,不需要整体部署。

3. 从开发、测试环境到准生产、生产环境:开发、QA和运营仍然采用传统的协作方式
这条主线涉及IT组织内部的合作和协调。传统的协作方式及流程的设计是依据当时“非频繁”交付设计的,不适应于当前对频繁交付的要求。IT组织仍然固守传统的运作和分工机制,做一件事需要开很多会,是一种类似瀑布流的组织方式,需要花很多时间。当下很多IT组织采用了敏捷开发、每天都可以产生很多构建(Build),但是生产环境的部署节奏仍然很慢,这是普遍存在的问题。
如何改进呢?
实现DTAP的融合需要三个方面的支持:观念的转变,组织结构和文化的更新及技术和工具的支撑。
首先是观念上面的改变,并建立与新观念相匹配的共享服务Metric和SLA信息。在竞争激烈的新时代,原来那种Dev和Ops隔离的方式已经满足不了云时代的快速迭代交互的需求。
| 传统观念 |
新观念 |
| 开发人员的工作是:增加新功能 运维人员的工作是:保持服务稳定、快速 |
开发人、运营、测试、项目管理人员的共同工作是:enable the business |
其次是工具和流程上面的改进。基于上面第一条、第二条主线达成的基础,构建自动化的文化,并建立清晰、一致的DTAP流程。这样Dev、Ops、QA因为是在一个流程和同样工具下工作的,相互所有的细节都透明了,也就自然融合了。同时,DTAP环境都是用相同的方式进行自动化部署的,在进行生产环境部署前,这个部署方法已经在开发、测试、准生产环境上面被反复验证过。总而言之,用统一的流程和工具管理不同的环境,又能支持不同环境的不同策略,这是实现DTAP环境融合在技术和工具上的关键所在。
最后,不同角色人员之间相互融合。比如,开发人员应该更加深入地参与测试及生产环境的运营,比如参与测试环境的部署、生产环境各个层面监控指标的设计和开发。“You build it, you run it”,这是Amazon一年可以完成5000万次部署,平均每个工程师每天部署超过50次的核心秘籍。
结束语
持续部署、持续交付能力的改进,是一个从自身情况出发的,持续的、不断改进的过程。在文章结束之前,我还想分享下我的两个体会。
- 不能把希望完全寄托在新兴的技术,比如Docker,来提升持续交付能力。很多人盼着Docker来解决现在存在的问题。但这些问题都不需要Docker就可解决,Netflix/ Flickr等就是例子,关键得有持续改进的意愿和行动。松耦合的SOA/微服务架构; “you build it, you run it”的DevOps文化; 与架构和文化相适应的自动化工具和Infra。这三点都不是一朝一夕或者一个新技术可以解决的。
- IaaS会是新常态,将成为互联网和企业的基础设施。云IT和传统IT有很大的不同。 使用IaaS只是第一步,企业应该利用上云这个契机,在应用架构、部署管理工具、开发运维协作方式也进行转变,解决这三个普遍存在的问题,打通从代码到服务的通道,提升持续交付能力。
作者简介
阮志敏是AWS认证解决方案架构师(专业级别),FIT2CLOUD联合创始人。FIT2CLOUD致力于帮助企业更好地使用云来加速业务创新,实现从传统IT到Cloud IT的转型。FIT2CLOUD不仅提供一站式的应用交付及运维管理工具,同时还提供方法论来帮助企业打通从代码到服务的通道,实现云应用的持续交付和自动化运维。