虚拟面向服务网格的出现
在不断变化发展的世界和IT环境中,了解新模型的出现以及它们改变商业的能力是非常必要的。正如当年Internet永远地改变了商业世界,虚拟面向服务 网格计算也具备再次改变世界的能力。若要更好的理解这种可能性,就必须要理解虚拟化和面向服务是如何工作的。除此之外,还要了解这些技术如何同网格计算结 合起来,互补不足。该领域的很多基础工作已经完成,剩下的就是如何推动(IT)朝这个方向发展的事情。
用别人的钱还是用别人的系统?
业务扩展经常需要OPM(用别人的钱),或者以合作伙伴的形式,或者通过IPO(首次公开募股)发行股票的形式。这些做法立足的法律框架需要上百年的发展才能形成。
在真实世界,扩展计算系统也遵循类似的方法(以资源外包的形式),如使用别人的系统(或OPS)。OPS的使用具有强烈的经济学动机——为偶尔使用的大系统投资数百万是没有意义的。
即便很大的项目(需要相当多的计算能力),它都往往从小规模尝试或开发试运行开始,然后逐步扩大。因为数据收集的周期因素,一些项目把最大、最壮观的运行保留到最后。开发阶段被闲置的大型系统是一种资本浪费。
《虚拟面向服务网格》一书(由Intel出版社出版)中介绍的另外两种技术(虚拟化和面向服务)推动着OPS的使用。虚拟化让物理资源的共享成为现实,而面向服务的应用原则则加速了资源的重用。
OPS使用的早期试验是在90年代初Wisconsin大学开始的研究项目Condor1 ,它基于的想法是共享闲置工作站。
在宏观经济规模上,OPS具有强烈的经济学动机。大型的网格系统意味着一旦增加物理和人员基础设施的投入,需要是的不是数千万而是几亿的投资。障碍 不会像乍一看的那么高。这么大的资源投资通常需要合伙,和航空系统,航海系统或者甚至摩天大楼一样,都要使用共享的合伙资源。因此,若没有工业上的动力就 不会有发展,只有当企业家意识到该技术背后可行的商业时,强有力的商业动机才会出现。
在经济学生态系统中,一群拥有这个领域技能的人可能打算成立一个公司,专门提供提供网格服务,这样做比一个部门的网格会更有效,因为部门网格的很多人可能另有其他工作要做,因此,专门的网格服务公司降低了向社会提供网格服务的整体成本。
不幸的是,完全成熟的OPS使用——计算资源能够像商品一样在充满生机和活力的生态系统中被买卖——目前还不现实,因为基础设施所需的复杂技术和法 律基设尚不成熟,这里说的基础设施要能支持SLA、隐私性、确保知识产权和交易秘密不会泄漏、用户,系统以及性能管理、记账和其他管理程序等。
当今的网格所处的状态是非常原始的,就像17世纪欧洲的经济活动相对于今天复杂的交易市场和金融设施一样原始。尽管如此,网格技术作为独特的学科还 不到20岁,而且令人高兴的是它的发展越来越快。作者们估计在不到20年的时间里,网格时代就会到来。那时,网格将会和社会网络交织在一起,直到它失去今 天所拥有的独特身份。
可喜的是,我们不需要等20年。网格的发展是连续的,也将会有越来越多的应用作为基础设施参与进来。有些公司采用网格比较快,其他的则慢一些,最后整个社会将从网格中收益。
举个例子,在数据中心(由数据公司托管)存储数据的做法即将过时。今后,存储将成为一个商品,能够以tb,pb或者eb(取决于时下最流行的单元和 由SLA定义的服务质量)为单元购买。存储代理商可能成为存储提供商,在他们的本地保存数据;对于大客户他们也可能作为纯代理商,根据复杂的统计学上的分 发规则,将客户的数据分发到其他存储提供商,这样即能满他们为客户承诺的SLA,又能最大限度地降低风险。这种做法就如同再保险系统,大型保险公司使用它 来管理风险和分发责任。
本文的一个基本前提是在企业计算中逐步采用网格技术的想法,这种结合将会给股东创造绝佳的增值机会。规划一个战略路线可以帮助企业实现这种技术合并带来的益处。
虚拟化,面向服务和网格
加速企业采用网格的进程的原因之一是它与两种技术趋势(虚拟化和面向服务)的协作。下面让我们分别探讨这些技术,然后探讨他们是如何协作的。
关于网格
网格计算中的“网格”这个词语的起源被一层神秘而朦胧的外衣笼罩着。由于网格和效用计算的关系以及效用计算与电网系统的类比,“网格”这个词语很可能起源于电力网格的概念,而现在应用于计算机系统。
电力系统包含着一组连接到母线的传输线,母线上可能有发电机(即电力的源头),也可能带有电力负载。最初,母线被称为节点,传输线和节点的汇合在一起就形成了一个网络,尽管可能是一个不规则的零星网络。地图上一组引线有时也被称之为网格
一个城市的电力分发系统在结构上无异于跨整个州或全国的传输系统。而区别是电力分发系统的内部连接更为紧密,原因是在每条街道之间都需要连接,而在跨州和全国的系统则只需要城市间的纽带。
依据上述类比,网格计算系统应包含如图1中描述的一组网络中的计算机。网格中的计算机都是功能完备的计算机,并可以独立运行。网络应该是基于标准的网络,如以太网网或公共网。
集群是一种特殊的网格,其中的节点通常是等同的并且可以部署在同一房间或大楼中。节点之间的网络可能是使用低延迟且高带宽的私有网络。
网格的定义是递归的,例如,集群在网格中还可以被看成是它的一个节点。
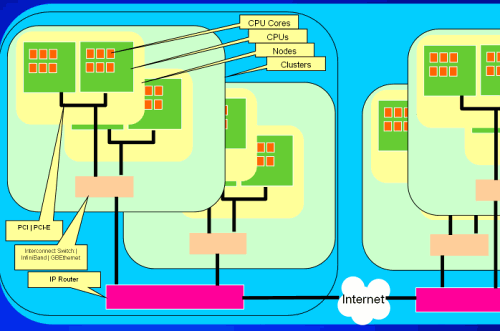
图 1 网格计算的结构
网格计算的发展始于90年代初,当时为运行高性能应用程序往往要使用数百万美金的专用超级计算机,网格的出现就是为了取代它,因为网格使用的工作站所需的费用要便宜很多(几万美金)。随着商业PC越来越强大,它们又逐渐取代了工作站而成为网格中的节点。
高性能计算应用程序是并行运行的:使用多个节点或计算机来解决一个问题,目的是尽可能缩短解决问题所需的时间。由于计算的复杂性和数据集庞大等原因,即使这样的问题可以在一个节点解决,它也需要若干天、周甚至更长时间才能完成。
在本文中的后续章节中,我们将使用通用的方式来引用“grid"。有些作者使用“GRID”来表示“GRID计算”,这种说法不太准确,因为grid不 是一个缩写。同样,有些作者使用“Grid”,把它看成是一个无人不知,无所不能的网格,就像George Orwellian书中的“老大哥”一样(译者注:老大哥是George Orwellian科幻小说中的人物,为西方人所熟知)。而事实上正好相反,网格计算解决的分布式和联邦资源管理的问题,它和“牧猫”的谚语故事中描述的 任务(译者注:指得是一种及其困难,几乎无法完成的工作,原因是很多变化且不可控的因素)并无多大差别。成功执行网格战略的回报主要是:更有效地使用资金 和获得业务敏捷。要实现这些目标,首先就要揭密它们背后的概念和技术。
网格能够解决的问题的类型是有限的。超级计算机的节点能够进行高速信息交换:它们拥有低延时和高数据带宽的传输通道。运行并行程序的计算机节点需要 实时获取来自其他节点的即时结果,依赖程度或多或少,取决应用程序的不同。如果节点间的信息交互不能足够快的话,整体计算进程就会受到影响,节点越多,影 响越大。对于特定的计算,存在这样一个点,计算节点个数在这个点可以非常有效的运行,而超过这个点以后效率反而下降。这个数量指出了特定系统架构在可扩展 性上的限制。 在扩展性方面,网格的限制要比专用的超级计算机的限制要小。对于特定应用,这些超级计算虽然可以有效支持数百个节点在一起的运行,而扩展性可能在几个节点 就遇到瓶颈了。
网格计算的精髓是一组通过网络连接起来的一组计算资源,这些计算资源包括处理和存储能力。网络必不可少,原因是缺省情况下计算资源是分布式的,可以 在一个房间里,也可以跨楼层,甚至是跨城市或跨国家。网络可以支持数据在计算单元之间传输,也支持数据在存储单元和计算单元之间的传输。
分布带来了复杂性。对一台计算机编程和使用要比在1000台更小的联合起来的计算机网格上(跨洲分布,拥有相同的处理和存储能力)容易得多。显然, 分布式的存在不是偶然的,必然存在很多能够证明它合理的理由,或反驳它不应存在的理由。从经济学的角度,这最终会反映了单节点计算机的能力在物理上的局 限。
当打开性能这个话题时,构建单台强大的计算机与构建与之性能等同的一组计算机相比,构建单台计算机要昂贵很多。追求单个处理的技术极限来提高性能的做法最终会只能事倍功半。
从这个角度来看,以复制的方式获得性能的做法更经济,这种动态性曾在很多场合都有发生。例如,2004年Intel发现奔腾4处理器的后代(也称为 Prescott的)可能会达到热能瓶颈(thermal wall),因为在同一块芯片上放置更多的晶体管,而且处理器要以更高频率运转,Prescott的运行时可能会太热,消耗太多的热能,而当今能耗已经成 为客户选择产品的一个重要因素。意识到这点后,第一代双核处理器的芯片在2006年问世,单个CPU的处理能力有所下降,但两个处理器合起来的性能要比它 的前辈的性能高很多,能耗也小很多。
从类似的经济学考虑出发,在处理器中增加内核的数量类似于在计算机中增加处理器。
复制可以超越单处理单元在物理上的限制。例如,如果一个单核处理器可以16分钟内更新十万条记录,那么一台拥有2个4核CPU的服务器理论上可以在 2秒钟内完成相同的工作。4台这样的服务器可以在30秒内完成。这里说的用8核(2×4)处理器或4台服务器的解决同一问题的方式就是所谓的并行
然而,并行也带来了重复。即使是4台服务器,总的处理时间也可能是1分钟,而不是前文中的理论上的30秒。为什么?就如同在一个厨房中用几个锅同时 煮饭一样。数据库可能无法为单个记录加锁,那么,如果两个或两个以上的记录在一个事务中被锁住,那么对这些记录的访问必须排队,而对其他记录的更新必须等 到第一条记录的完成后才可以开始。此外,在分布式系统中传输数据也需要耗费一定时间,因此一定会有延时。
复制的另一个动机是提高可用性。例如,一个拥有1万个存储节点的网格潜在1万重(译者注:重复)冗余。在这样环境下丢失数据的可能性几乎为0。 1000重冗余太过了,在实际中,使用重复资源的目的或是在不可靠的节点和网络中提高可用性,或者提高扩展性。因此,对于1万个节点的数据网格,最后可能 由2500个4重冗余的节点组成,这样仍然比一个节点的存储能力强,同时还具备高可用性。
网格的根本功能是高性能计算,而与另外两种技术(面向服务和虚拟化)的合并让它超越其自身的能力。
网格的物理描述
在上一节我们讨论了网格的属性,把网格定义成一种通过互联网连接起来的计算节点。在本节,我们将描述网格的结构,在介绍各组成元素的时候,回头再看看图1是很有用的。
事实上,网格中的节点与在某些特定场景下互联起来共同完成某种工作的计算机并无很大差异。互联网络应该使用一种开放的协议,如TCP/IP,不然连通性可能很难实现。
以下是一些网格节点的例子:
- 笔记本或个人PC:任何联网的PC都可以是网格的成员。将个人PC互联起来的网格应用的典型案例是SETI@home程 序。它也是循环利用(cycle scavenging)的一个例子,在PC的主人不工作时,应用程序就像一个屏保程序一样运行。在一个更正式的环境里,循环利用(cycle scavenging)是通过高端工作站实现的,在一个国际性团队,由于国家间可能跨好几个时区,有时候一个国家的用户要使用另一个国家空闲的资源。
- 数据中心服务器:循环利用(cycle scavenging)的缺点是时间的不可预测性,原因是可能在最需要的时候目标资源处于忙或不可用状态。在这种环境下,网格节点应该部署成完全服务于网 格应用。此外,节点不一定是部门级的,它们可以是企业资源池的一部分。一旦超越企业界限,就和网格服务提供者的商业模型不远了,这种模型和网络宿主模型相 似,服务提供者为多个企业客户提供服务。
- 集群和并行节点:网格中节点没有结构上的限制。而实际上单节点也可以获得高性能,可以是包含多个CPU的计算机也可 以是多核计算机甚至是集群。我们这样来区别集群和网格,集群中的计算机(或节点)通常位于同一栋楼中;此外,和网格相比,集群节点往往是通过高带宽和低延 时的特殊网络连接起来的,而这些特殊网络往往是私有的或者独家的。在集群中使用私有协议并无大碍,因为和集群外的连接是通过标准协议完成的。
- 嵌入式节点:另外一个极端,网格中的节点也可以是一些简单的,专属的计算机。我们称这类节点是嵌入到应用程序的节点。比如网络路由器、无线访问、是微处理驱动、智能电子表(如煤气表,水表等)或者是电缆公司的客户居住地的设备里所使用的计算机。还有大量安装在城市里的网络监控以及交通录像和环境传感器等。
在网络方面,物理媒介因距离的不同而不同,从InfiniBand技术到局域网中的以太网(如果节点离城域网很近),可能是连接各建筑物的城市网络,也可能是广域网(如果节点是越洋跨洲的),传输协议通常是TCP/IP。
网格应用由哪些元素构成,有些模棱两可,不是所有的分布式应用都是网格应用。从另一个角度看,如果一个现有应用程序在某方面存在限制,网格的方法也 许能够指导该应用向网格的方向发展。比如金融衍生品风险计算或者数据中心热能模型的热交换方程的计算,可能需要好几个小时才能得到结果,这些计算密集型的 应用就可以向网格发展。
由于性能及软件提供商的许可问题,通常的解决办法是让应用通过一个排队系统到达某个高速服务器进行处理。随着客户群越来越精明,要处理的应用越来越多,用户群的扩大,以及提交的任务越来越复杂,一个任务可能要等待更久才会被处理。
如果需要等待一天才能得到运行结果,那么解决问题的时间肯定不止一天。原因是在运行中时常会出现操作或技术上的问题,从而必须要重新提交。还有,用户经常会提交一组参数化的运行请求,它们之间只有细微的数据上的差异,而可能这些差异是由前一次运行的结果决定的。
如果可能,将每次得到运行结果的周期时间从24小时降低到1小时,那么开发时间将可能大大缩减。相反,如果周期超出了用户的预期也会让客户不耐烦。
通用的降低周期时间的方法是期望软件提供商提供多线程版本的应用,这样就可以利用到多核处理器或多CPU服务器的优势。
如果负载超越了最强大的服务器的能力,下一个方法就是在集群中运行应用,但如果负载不平和或呈季节性规律,那么集群就很昂贵,而且很难调整开销。在 这样的情况下,基于网格的解决方案可能是最有效的,负载可能被分流到公司的其他服务器,或者也可能是公司外的服务器。同时,我们也要理解这些并非轻而易举 就能实现,因为应用程序需要被重新开发使其可以在网格环境中运行。
虚拟化
虚拟化使用计算机的固有能力去模拟计算机本来不具备的一些能力,可以是模拟完整的计算机,也可以模拟不同架构的计算机。
虚拟化是数学上可行的,因为所有的计算机在本质上是自动机,简单来说,是一组被称为“有限状态机”的状态机:在特定操作条件或状态下的计算机执行一 个指令的结果永远是相同的。自动机在行为上是确定的:在相同情况下,相同的触发总会得到相同的行为。计算机的虚拟版本需要上亿个状态改变和很大数量的记分 板,也就是说,宿主计算若要模拟一台虚拟机器,就要在每一步模拟时记住它所虚拟的计算机的状态。有幸的是,该记分板的工作是由宿主计算机维护的,而当代计 算都能胜任该工作。
模拟动作,也就是虚拟计算机在宿主计算机中的状态改变,在宿主计算机上做的工作比被虚拟的计算机的工作更多。如果要模拟虚拟计算机的一个指令周期, 那么在宿主计算机上要用去几个指令之后,附加记分板的负载。在不同的环境里,负载有所差异,在最高效的虚拟化环境里是5%,但在较差的环境里可能会达到减 缓计算机运行的程度。在典型的虚拟服务器环境里,如果虚拟化机器和宿主机器的体系结构相同的话,5%至15%是正常的负载。如果一台机器虚拟化运行一个原 先需要15%负载因子应用程序,能够以60%的负载因子运行4个应用程序,这就意味着通过虚拟化获得了4倍于原来的生产力,所以即使是15%的负载相对于 带来的价值来也是一个可接受的抵消(traceoff)。
对于以下环境,虚拟化也是合理的,如硬件成本只占交付成本的一小部分;数据中心;或者由于能量和空间的原因限制了在数据中心部署物理服务器的数量等。
最早的虚拟化应用程序是20世纪60年代在实验室完成的虚拟内存的研究。虚拟化使有物理内存限制的机器拥有大得多的虚拟内存空间,这是通过将数据保 存在位于其他形式存储空间(如硬盘)的虚拟内存中。在使用数据时将数据交换到物理内存,而不用时将其交换到虚拟内存。虚拟内存的一个弊端是它要比相同的物 理内存体系要慢很多。
另一方面,尽管存在弊端,虚拟化体现了一些不可否认的操作上的优势。网格中的节点如果都是等同的,则管理起来要容易得多。注意,它们只需要在虚拟上等同,而不是物理上相同。
虚拟化在目前的数据分离,应用(操纵这些数据的应用)分离以及计算机(运行这些应用程序的计算机)分离的的趋势中扮演着非常重要的角色。
面向服务
面向服务的说法来自于商业世界。任何商业社区或生态系统都是由一组服务构成的。例如,一汽车修理店提供汽车修理服务,反过来他们使用电力系统服务、 电信服务、会计和法律服务等。汽车修理店的客户在提交汽车修理需求时使用的是非常程式化的接口,它无异于其他服务提供者系统的接口:任何汽车修理店,接受 用户预约,设有接待处和记账部。相反,与业务直接相关的活动,如交税的程序,就不必暴露成接口了。
服务是可组装的:某企业提供服务供客户或其他企业使用,同时也通过集成和聚集的方式使用其他企业提供的服务来组建自己的服务,如图2所示
服务还可以递归组装:Intel从原设备工厂购买笔记本,而反过来,笔记本使用的是Intel的微处理器。工厂能够集成微处理器而组建成产品,而Intel正好受益于这种能力。图2描述了递归的过程:S4服务于S1,同时又使用S1的服务。
如联邦政府和数万亿的全球性大公司,被人们认为是世界上最大最复杂的组织。他们依赖于成千上万的来自全球各处的服务,而提供这些服务的公司本身就可能是一个全球性的企业。
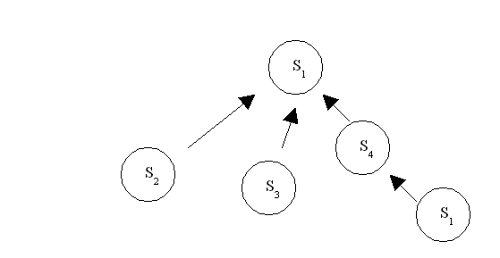
图 2 组合服务 S1 通过S2, S3, S4 和S1 (通过递归的方式)实现
即使是那些世界上最大的汽车制造公司,将集铁矿开采(为了造汽车轮子)和石油钻井方面的核心技能集于一身也是很难想象的。
经济学生态系统中的各部分之间的关系是松耦合的,有时非常之松:一旦汽车卖出去,汽车制造商就不再负责汽车今后的加油,购买者依赖于能源服务提供者 网络(来加油),然而若没有能源服务,那就没人买汽车了。这种情况导致了引入使用其他能源的交通工具的门槛很高。目前使用氢气油箱的汽车市场非常小,而且 因为其本身的技术复杂性,这样做也没有必要,另一个原因是支持这种新兴技术的服务网络尚未形成。
同样地,有人可能会说,纯电力或双动力汽车之所以没有得到发展的原因是由于现有电池技术的里程限制而导致电动汽车“太贵”,这里的太贵指的是超过2 万5千美元。然而,传统的内燃机汽车的价格在3万到6万美元之间,但并没有被看成奢侈品。这并不能说明电力汽车使用不同的标准,这恰恰反映价格可能并不是 采用的真正障碍。真正原因是支撑电力汽车大市场的基础服务尚未完善:如果每个停车位都有一个防震感应充电站,那么小范围地使用电动汽车是不成问题的。
为支持和运行商业界服务而明确设计的IT应用和基础设施被称之为面向服务的。面向服务的架构,或SOA就是为支持面向 服务的模型而设计的任何结构化的服务和技术的组合。不是某人在某天发明了这种技术,相反,它是一种已有技术的进化和发展。随着21世纪初期.com蜂拥而 至,导致了IT部门的现有危机,这对加速面向服务的采用起到了很大的推动作用。成果之一是IT和业务需求对齐的复苏,从而强调了技术在支持业务和缩减裁员 方面的功劳。
面向服务在今天是变革力,就连最大的IT公司也通过SOA来整合他们的业务操作。整合背后的动机是因为SOA可以带来运营成本的大幅降低。
工业界至少已经达成这样的共识,计算能力至少要以服务的方式实现和业务应用的对齐。从广义上讲,服务是业务服务的一个抽象,通过接口定义。从接口的 角度看,服务可以简单如信用卡消费授权(传入一个账号和消费金额,返回结果是否批准消费),也可以复杂如分期贷款处理或几乎任何业务交易(企业合并或事务 性约定)
服务可以来自多个实体,也可以被发现(要存在发现服务的机制);它可以被替换(替换成其他服务提供者),还要能互相协作:如果换一个服务提供者,服务必须仍然能工作。
服务还应提供可以被用做分类的绑定机制或合约,直到服务被调用的那一刻。绑定机制可以包含功能性规范(在一次调用或事务中被交换的特定元件)和非功能性规范(通常指QoS和SLA等)
服务和一些编程语言中的方法,过程以及子过程之间存在着一定的相似性。区别是服务超越了编程语言,并且应用于业务流程或者人工活动。
早在20世纪70年代一些软件工程师和语言设计者就提出了由服务这个概念带来的相关需求。而只有在今天,在21世纪的最初几年,技术才发展到实现这个梦想的水平。服务概念的第一个化身是通过Web服务实现的,它定义了信息传输机制以及使用广泛理解的XML作为数据格式。
在服务环境里,基本的前提是IT系统和流程是对齐的,并且对它们的设计要支持服务的概念。遵循这个概念的IT实体可以被看成是面向服务的。最后,把所有的遵循面向服务的IT实体放在一起(以一种架构)可以看成是遵循SOA的。
理论上,每一个服务都可以独自从平地而起。这种策略非常昂贵,因为那些基础的、通用的功能需要在很多地方复制。常见的例子是公司的员工表,人力资源 部门为了跟踪福利会有一份拷贝,而在IT通讯部也有一份拷贝,用于记录电话目录,整个公司的其他部门或多或少也会散布着部分信息。大多数信息系统都是本地 开始,慢慢或多或少发展成孤立的仓筒。面向服务的仓筒没有任何优势,事实上,我们在它身上找不到任何传统方式下不具备的能力。SOA的优势主要是经济学上 的。
由于服务是可替代的,因此也可以被重用:每次服务被重用,我们就拿到了一个不需要重写的服务实例。因为IT服务要设计成业务对齐的,所以使用到新业 务时,语义上就不会有太大的鸿沟。 在成熟的SOA环境里,从底层构建服务是很少见的,大部分服务都是从现有服务的基础上组装而成的,或者通过合成可用服务的方式创建的新服务。
通过这种方式构建的应用被称之为复合应用。除了可能的性能或组织上的障碍,复合过程的深度是没有限制的。
通常,服务本质上可以是任何人工活动,而IT人员所关注的是有限的一部分服务概念。尽管可以从服务发起一个物理活动,如房屋抵押贷款申请过程中的对 住宅鉴定员的访问,信息技术中的服务应该有一个前端接口供其他应用程序和服务来访问。最通用的服务调用技术是Web服务,在Web服务的环境里,我们称服 务的实现为servicelet或microservice。
换言之,servicelet就是复合应用的基础元素。它通常被实现成一个自包含的软件和硬件单元。复合应用使用Web服务技术把 servicelets和其他servicelets结合起来。一个servicelet可以是一个服务,然而并非所有服务都能以servicelet的 方式使用,除非有合适的前端。
SOA不是免费的。不能把功能的实现无限地交给其他服务,最终总要有一个应用程序来实现实际的功能,而且这个功能块至少要有一次实现。SOA环境下 的系统需要消耗更多的工作和费用来设计重用。例如,让服务可以被其他组织发现通常意味着维护一个服务存储库,这个存储库可以是非正式的,当架构师和服务实 现者之间互相认识的情况下可以是口头描述的或者email问询的方式。可以是正式的UDDI(统一发现,描述和集成的)存储库,协同WSDL(Web服务 描述语言)机制来描述服务和端点。
虽然建立SOA环境面临着许多额外的付出,但它可以影响项目并产生长期的收益。这无疑是一个艰难的任务,若没有自上而下的深思熟虑的计划,向SOA环境的转型将无法获得成功。
另一个方面,SOA带来的战略性好处改变了游戏规则。SOA为企业带来的好处不是体现在Gartner基础设施成熟度模型的最高级阶段(在这个阶 段,基于策略的环境一种规范),就是体现在MIT Sloan信息系统研究中心(CISR:Center for Information Systems Research)在研究时所记载的企业架构的最后阶段。
在SOA的环境中,为支持任何传略和战术性的需求,IT资源可以被非常便捷地传输。战术性需求的例子是为相应特定市场情况而开展的市场营销活动。
这些目标的实现不仅仅因为数据中心的物理车间可以按意愿扩展(尽管数据中心将具备更多的能力),另一个重要的原因是为响应需求,SOA支持对现有资源的重组和重用。
IT不再只是业务发展的有限因素,而成为它的手段。谈论IT预算不再围绕具体的请求,取而代之讨论价值——IT可以为业务带来多大贡献,由于可能花费很大,讨论可能不能付诸实施。
面向服务被人们所知最初是在应用层,所以当我们听到SOA时,我们通常想到业务应用。事实上,每一层业务抽象带来的影响都是意义深远的。
虚拟化+面向服务+网格=虚拟面向服务网格
为了运行高性能计算(HPC)应用,虚拟服务网格已从原始的网格进化成独立的子群。这种进化拓宽了最初的HPC网格的市场魅力,原始HPC网格继续强调性能的进化。
根据宿主硬件的存放位置的不同,有两种不同的企业网格,他们是数据中心网格和PC网格。PC网格是最初的工作站网格发展而来的,它可能还被用做循环利用(cycle scavenging)的宿主;PC网格中的节点在公司里被分派给个人。图3描述了这种关系。
数据中心网格使用基于服务器的,匿名节点,每一个节点不会分派给任何个人甚至应用程序。在数据中心环境中进行循环利用(cycle scavenging)是可能的,但基本不切实际。在一个独立的管理结构下进行循环利用(cycle scavenging)来清除未被主应用使用的计算机时钟的做法会是投入大于产出,这种模式还很容易遭受来自主应用所有者的强烈的政治阻力。较之于将工作 量分为主工作量和循环利用工作量,更有意义的做法是把工作量分派给一组一致的服务器,按照服务器资源的优先级统一分派工作量。
有人可能会提出异议,因为笔记本客户端是独立拥有的,所以循环利用模型(scavenging model)仍然是有意义的。然而,正如瘦客户端和胖客户端的之间的区别不清晰,服务端和客户端的界限将变得模糊,对PC客户端的循环利用模型也将过时。 保留下来的是一组基于服务的应用运行在一组硬件池中。而在什么地方运行服务的决策将最终由作环境决定,同时受到适当的政策约束。
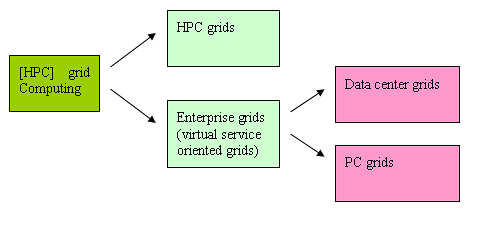
图 3 ——从最初的低成本HPC需求到现在的可扩展的网格计算的网格进化史
对这种趋势的分析指出从另一个角度看数据。在某种程度上,技术的合并导致了数据的分离,应用程序的分离以及计算机宿主的分离。
在虚拟化网格环境中,数据将不再绑定在具体的计算机上,因而某台计算机被盗不再是严重的问题。现在,数据没有实际形态,只是在需要时,以合适的形式 展现到访问它的设备上。对于程序或用户来说,数据可能看起来像一个实体,如单个文件。事实上,系统会把数据存储、复制、迁移到不同的设备,同时维持其逻辑 实体的假象。
欲了解关于虚拟面向服务网格的更多信息,请阅读由Enrique Castro-leon,Jackson He,Mark Chang和Parviz合著的《虚拟面向服务网格的价值》一书。
关于作者
Enrique Castro-Leon是Intel数字企业组的企业级架构师,数据中心架构师以及技术战略家。他的工作包括操作系 统设计和架构,软件工程,高性能计算,平台定义和业务开发等。他经常将新兴的技术和创新的商业模型应用于不断发展的新兴市场。他曾在多家公司、非营利组织 和政府部门担任过技术和数据中心规划方面的咨询师。
他曾是梦想家,也曾担任过解决方案架构师,项目经理,还曾担任过技术总监,负责高级POC项目,向企业用户和Intel内部用户展示新技术的使用。 他发布了40多篇文章、会议论文,技术战略管理方面甚至SOA和Web服务方面的白皮书。他的硕士和博士学位是在Purdue大学电子工程和计算机科学专 业获得的。
Jackson He是Intel数字企业组的主管架构师,专攻易用性管理和企业级解决方案。他获得Hawaii大学的博士和MBA 学位,拥有20多年的IT经验,从事过多种工作,如教书、编程、工程管理、数据中心维护、架构设计和企业级标准定义等。Jackson是Intel在 OASIS、RosettaNet以及分布式管理任务组的代表。从2002到2004年,他是OASIS的技术咨询组成员之一。今年来,他致力于动态IT 环境下的企业基设管理,和平台能源效率的研究,他的研究课题颇为广泛,包括虚拟化,Web服务,分布式计算等。他曾在Intel技术杂志和IEEE会议上 发表过20多篇论文。
Mark Chang是Intel技术销售组的主要战略者,他专攻面向服务的企业、高级客户端系统的业务和全球技术战略。Mark拥 有20多年的企业经验,包括软件产品开发、数据中心现代化和虚拟化、统一消息服务部署和无线服务管理等。他参与过多个企业标准组织,定义CIM虚拟模型和 相关的Web服务协议的标准。此外,Mark和系统集成以及IT外部社区有着密切的联系。他拥有Austin Texas大学的硕士学位。
Parviz Peiravi是Intel公司的主要架构师,负责全球企业级解决方案及设计。他在Intel有11年多的工作经历,主要负责设计和驱动面向服务的开发。
阅读英文原文:The Emergence of Virtual Service Oriented Grids。
This article is based on material found in book The Business Value of Virtual Service-Oriented Grids by Enrique Castro-leon, Jackson He, Mark Chang and Parviz Peiravi. Visit the Intel Press web site to learn more about this book: www.intel.com/intelpress/sum_grid.htm.
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Publisher, Intel Press, Intel Corporation, 2111 NE 25 Avenue, JF3-330, Hillsboro, OR 97124-5961. E-mail: [email protected].