作者访谈:《信息管理中的模式》
在Mandy Chessell和Harald Smith共同所著的新书《信息管理中的模式》中,他们根据自己丰富的客户实施经验就如何组织和管理企业中的信息资产给出了他们自己的一些方法。他们采用了一种依靠模式的方法来确定用于解决不同的与信息相关的问题的方法,而这些问题都是在他们所服务的企业中经常会遇到的。InfoQ对本书的二位作者做了一次访谈。
InfoQ:请为我们InfoQ的读者们简单介绍一下你们自己。
我是Mandy Chessell,IBM的杰出工程师和首席发明人,同时也是IBM技术研究院领导团队的成员之一。我目前的工作是在IBM信息管理CTO办公室中担任InfoSphere解决方案的首席架构师。我领导设计过用于不同行业和解决方案的参考体系结构(reference architecture),具体包括IBM的Next Best Action解决方案、Big Data Lake解决方案以及信息虚拟化。除去我所担当的技术方面的职责之外,我还积极参与了旨在增强IBM技术社区活力的各种活动,例如技术指导,还负责对技术人员职业生涯的发展提供各种帮助,并且还参与了公司Women in Technology计划中的晋升评审委员会。在IBM之外,我还是英国皇家工程院的院士以及英国谢菲尔德大学的客座教授。在2001年,我成为了英国皇家工程院银质奖章的首位女性获得者,并且在同年获得了普利茅斯大学的名誉科学博士学位。
我是Harald Smith,IBM InfoSphere和Information Server产品的软件架构师。在我以往多样的工作经历中一直专注于信息质量、信息集成以及信息管理这类的产品和解决方案,并且长期对模式和设计实践感兴趣。我写过很多文章来帮助我们的客户使用我们IBM产品线中的产品,尤其是关于方法论、最佳实践以及系统性能这些方面,并且最近正式成为一位IBM developerWorks社区的作者。在我30年的工作生涯中,我从事过的领域覆盖了软件产品管理、信息技术、咨询服务、技术支持、系统审查以及业务流程重建。这些经历开阔了我的眼界,使我了解了很多与信息相关的跨行业的难题。
InfoQ:你们为什么要写这本书,打算通过这本书解决什么问题?
在过去的这十几年的时间里我们服务了大量的客户,在这个过程中我们逐渐找到了在企业的信息管理工作中经常遇到的那些相近的难题。这些客户可以找到介绍关于如何存储信息的书籍(例如数据仓库),也可以找到介绍关于如何清理信息的书籍(例如数据质量策略),但一直很难找到关于如何在企业内的众多信息系统和应用间管理信息流的一套完整的方法。
因此,这本书的创作始于一个名为“信息供应链”的概念。IBM的营销部门使用这个术语来描述系统间的信息流动。不同来源的信息通过企业中的业务系统被装载到数据仓库和数据集市中,然后再通过报表或者商业智能解决方案最终送达终端用户的手中。这个概念与以原材料进行产品生产的过程中所用到的制造供应链十分相似。只不过在这里“信息供应链”的目的是以所提供的原始信息来生产出某种“信息产品”(例如文档、报表、网页或者信息的存储集)。随后我们开始以架构的视角来思考这种像供应链一样的信息流动,在这个过程中我们开始观察出一些我们认为客户企业的架构可以借鉴的一些有用的模式。
InfoQ:本书所面向的读者是哪些?
本书的主要读者是那些负责决定通过什么样的方法在多样化的信息系统和应用间进行信息的共享、集成、同步和管理的企业架构师、信息架构师以及解决方案架构师们。这些人员必须要负责找到影响信息使用效率的多个因素,以此来提高企业的决策能力、创造新的附加值以及减少成本或风险。
InfoQ:怎样才算是一个“以信息为中心的企业”?为什么它如此重要?
一家“以信息为中心的企业”会依靠高质量和及时的信息驱动业务的运行,以此来实现既定的目标和任务。如今我们已经进入到了一个把信息作为一项关键的竞争资源的时代,那些关注于信息的利用,并且对所拥有的信息进行分析和学习的企业往往会比那些不关注信息利用的企业取得更大的成功。通过把信息的管理提升到企业战略的高度,以及通过开发系统和实践方法来最大程度地管理和利用信息,一家“以信息为中心的企业”能够通过对信息进行分析从而发现新的收入增长点、推动产品的创新以及进行模式识别来帮助减少欺诈和降低风险。
InfoQ:你们为什么选择使用一种基于“模式”的方法?模式究竟是什么以及它们到底有哪些作用?
对任何企业而言,而不仅仅只是那些大型企业,信息管理都是一项非常复杂的工作。而这种复杂性来自两个方面:
- 内在复杂性:所要处理的问题本身就非常复杂(例如欺诈检测、物流以及客户行为),因此会需要建立平台以及相应的解决方案来处理来自多个渠道的信息,以此来帮助我们分析和克服这种复杂性。
- 诱发复杂性(Induced complexity):在任何企业的信息供应链中都可能会出现信息不一致的情况。这种情况的产生可能是由于不同部门间相互独立的业务线、采用了来自多家厂商的架构和应用或者企业并购这些因素导致的。
模式是一种可以用来解决以上两个方面复杂性的方法。信息管理的相关技术为我们提供了实现一个信息供应链所需的架构的多种选择。其中的每种选择都针对某一特定类型的应用做了优化。模式使我们能够比较和对比这些不同的方法以及在哪些方面它们的用处最大。而模式的其他一些特性还包括:
- 模式是由自然语言写成,因此不需要使用专门的工具。
- 每个模式都含有很多信息,它们共同应用于多个理解层次。
- 在模式的描述中列举了相关的选择,以及如何在它们中间做出决定,还涵盖了采用某种方法的优缺点。
- 每个模式的描述中都提供了一个样例和一些已知应用的引用,还包括了其他类似模式的链接。
- 不同的模式关联在一起就形成了所要解决的问题的一个完整的描述。
- 模式中还描述了使用某种特定的方法而带来的新的特性。当把某一类型的组件集成到特定的配置中时会产生这种新的特性。这些新特性通常都是非功能性的特性,例如延迟、可靠性以及一致性方面的改变。
上面的最后一点特别的重要,许多与信息供应链相关的设计决策都是重点关注每种方法能够产生哪些新特性。这种模式语言很适合来解释选择的依据、利弊的权衡以及每种设计选择会给我们带来哪些好处和负担。
InfoQ:这本书通过一个案例分析的方式详细地描述了各种不同的模式。这样做是否能够更好地帮助读者来理解什么时候应该使用以及怎样使用某种模式?
人们更加容易理解那些现实世界中常见的例子,特别是那些人们在头脑中可以想象出来的,例如一个订单的处理流程。我们每个人都曾在商店或者网店中挑选并购买过某种商品。而彼此间孤立的系统可能会造成我们在一个地方能够被识别成老客户但是在另外一个地方却不能(或者是只在其中的一个系统中有我们的正确的收货地址),而这些都会给顾客造成不好的体验。与此同时,即便是在这些最基本的小型企业的例子中,我们也会开始渐渐地了解到如果要充分利用好现有的信息我们需要做哪些权衡工作。而这些权衡工作的结果会自然地引入不同的模式,包括它们的典型用法以及相关的影响因素,这样我们就可以在我们所遇到的与信息相关的难题中做出合理的决定。
InfoQ:本书所涵盖的这些模式大概能分为哪几类?
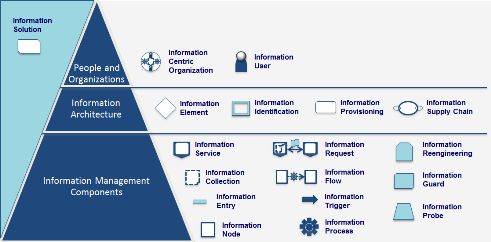
如下面这张图中所展示的一样,我们将模式分为以下几个大类。
最上面的一层是信息企业,由以信息为中心的企业的相关特性以及企业中具体使用信息的用户所组成。
中间的一层是信息架构,这几组模式主要用于分类、设计以及记录需要什么样的信息、如何使用这些信息以及在哪里存放这些信息。这种信息架构最终会形成关于企业中所使用的信息的一份当前的并持续变化的完整的描述。
最下面一层是信息管理组件。这些组件为闲置的信息、运转中的信息、信息处理和信息保护分别提供了不同的模式。
把这些模式以不同的组合方式放到一起,这样就能反映出企业正在试图解决的多个目标和影响因素,并最终会形成信息解决方案。这些信息解决方案能够帮助企业高效地管理他们的信息,从信息中获取新的发现,并最终为企业产生新的价值。
InfoQ:能为我们举几个读者可能遇到的问题的具体例子吗?读者怎样使用本书中介绍的模式来帮助他们解决这些问题?
这里让我们以一个使用一个数据集市来存储关于顾客以及订单历史信息的企业为例。销售团队希望在这个数据集市上运行一些报表,它们对历史数据执行查询并且按地区汇总出顾客所购买的产品。他们每天都需要从这个数据集市中获得稳定的响应次数。与此同时,为了给公司创建出新的分析模型,数据分析团队也希望使用这个数据集市来对历史数据执行数据挖掘。数据挖掘工作每天会不定期地占用大量的处理能力,因此就会对来自销售团队的工作造成影响。那么公司的IT团队如何做才能调节好这两种使用模式呢?
他们使用了沙盒供应(Sandbox Provisioning)模式。当数据分析团队需要为新的分析执行数据挖掘的时候,就会为他们创建一份数据的拷贝。该沙盒中的数据是以方便分析任务运行的方式进行组织,并且它们跑在另外一台机器上面。由于这种沙盒是为了运行某一特定的任务而创建的,因此在挖掘任务执行完成之后,我们会把它删除掉。
上面的这个例子虽然很简单,但它反映出了信息架构需要解决的一个常见的问题。如何才能通过使不同的用户组共享集中存储的数据的方法来减少数据拷贝的数量,而同时还要保证一个用户组所运行的任务不会影响到其它用户组?有些时候当处理模式发生冲突的时候,为一个或多个用户组单独创建一份信息的拷贝也是很有必要的。
这种数据拷贝的代价取决于数据量、数据变化的频繁程度、产生拷贝所能采用的技术以及为了方便目标用户的使用我们需要做多少数据结构的转换工作。以上这些因素都会在信息的供应模式的选择过程中产生影响。一旦我们选定了某种合适的供应方法,然后我们就该决定在供应模式的逻辑中究竟该使用哪种处理模式。是否我们可以采用一个不对数据进行任何转换的简单的信息复制模式?或者是我们需要做数据转换,所以不得不采用一种例如信息部署模式的更加复杂的处理流程。
这种模式的选择通常都是一个充满迭代的过程,而在每一层迭代中,模式的描述信息都解释了采用每种方法所需要的权衡。
InfoQ:如果采用了本书中所介绍的这些概念,会不会将读者引向某一特定的技术解决方案?请问为什么会这样?
模式中所描述的概念通常会强烈地建议使用某种特定的技术以便对一系列想要实现的业务结果作出优化。但同时,我们也可以充分考虑企业中所存在的技术约束,并且把这些技术约束当成影响我们作出其它选择的因素。
例如,单从技术上讲,一个最优的方式是使用信息队列模式把数据以消息的方式传递给应用程序,并让应用程序来负责处理任何数据上的质量问题。这种方法能够保证最快的传输速度以及数据的高可用性。但有时我们的应用程序并不具备处理这些带有质量问题的数据的能力,不正确的数据值可能会引起应用程序的崩溃。这这种情况下,这些存在于信息供应链尾端的约束条件就会对解决方案的适用性造成影响。因此,这里我们需要选择使用一个例如对数据进行提取、转换和加载(ETL)操作的信息部署流程模式,它能够对传来的数据进行转换操作。虽然这样做会增加一些系统延迟,但就该解决方案总体而言,还是能够提供快速的传输速度和数据的高可用性,同时还对数据进行了清理。
读者可以通过这里来阅读本书的样章,并且可以通过这里来购买本书。
本书作者的简介
 Mandy Chessell于1987年加入IBM。她是一位IBM的杰出工程师和首席发明人,同时也是IBM技术研究院领导团队的成员之一。她目前的工作是在IBM信息管理CTO办公室中担任InfoSphere解决方案的首席架构师。她领导设计了一些用于不同行业和解决方案的通用信息管理模式,具体包括Next Best Action解决方案以及信息虚拟化策略。在2001年,她成为了英国皇家工程院银质奖章的首位女性获得者。在2000年,她被MIT的Technology Review杂志评选为年度全球顶尖青年科技创新家。在2006年,她获得了由英国女性创新家及发明家协会(BFIIN)颁发的“才能培养”奖项以表彰她在培养创新性人才方面所做的杰出工作,并且同年她还获得了BlackBerry颁发的“年度杰出技术女性– 企业”这一奖项。最近她刚刚被工程设计研究院(IED)授予了名誉院士的头衔,获得了“2012年Cisco年度女性创新家”这一奖项,并且在2013年获得了普利茅斯大学的名誉科学博士学位。
Mandy Chessell于1987年加入IBM。她是一位IBM的杰出工程师和首席发明人,同时也是IBM技术研究院领导团队的成员之一。她目前的工作是在IBM信息管理CTO办公室中担任InfoSphere解决方案的首席架构师。她领导设计了一些用于不同行业和解决方案的通用信息管理模式,具体包括Next Best Action解决方案以及信息虚拟化策略。在2001年,她成为了英国皇家工程院银质奖章的首位女性获得者。在2000年,她被MIT的Technology Review杂志评选为年度全球顶尖青年科技创新家。在2006年,她获得了由英国女性创新家及发明家协会(BFIIN)颁发的“才能培养”奖项以表彰她在培养创新性人才方面所做的杰出工作,并且同年她还获得了BlackBerry颁发的“年度杰出技术女性– 企业”这一奖项。最近她刚刚被工程设计研究院(IED)授予了名誉院士的头衔,获得了“2012年Cisco年度女性创新家”这一奖项,并且在2013年获得了普利茅斯大学的名誉科学博士学位。
 Harald Smith目前在IBM担任软件架构师。在他以往30年多样的工作经历中一直专注于信息质量、信息集成以及信息管理这类的产品和解决方案,并且长期对模式和设计实践感兴趣。他所从事过的领域覆盖了软件产品管理、信息技术、咨询服务、技术支持、系统审查以及业务流程重建,并且在世界范围内发布了4项专利。他写过大量的文章,其中一些发布在了他当前的博客“信息之旅”中,他的文章特别关注于那些IBM产品中的方法论、最佳实践和性能问题,以及大数据和信息管理的相关话题。此外,他还是一位IBM developerWorks社区的作者以及在信息管理领域内IBM认证的解决方案开发者。
Harald Smith目前在IBM担任软件架构师。在他以往30年多样的工作经历中一直专注于信息质量、信息集成以及信息管理这类的产品和解决方案,并且长期对模式和设计实践感兴趣。他所从事过的领域覆盖了软件产品管理、信息技术、咨询服务、技术支持、系统审查以及业务流程重建,并且在世界范围内发布了4项专利。他写过大量的文章,其中一些发布在了他当前的博客“信息之旅”中,他的文章特别关注于那些IBM产品中的方法论、最佳实践和性能问题,以及大数据和信息管理的相关话题。此外,他还是一位IBM developerWorks社区的作者以及在信息管理领域内IBM认证的解决方案开发者。
查看英文原文:Author Q&A: Patterns of Information Management