作者访谈与书评:“Nagios企业监控实践(原书第2版)”
David Josephsen的新书《Nagios企业监控实践(原书第2版)》最近出版了。这本书包含了构建监控平台的最佳实践、侧重使用方面对Nagios的运作原理进行了介绍,并包含了实施Nagios项目的实用指南。David编写这本书虽然以帮助系统工程师和企业架构师为主,但书中包含的内容依然与大多数技术角色相关。David以官方在线文档中的内容为基础提供了系统集成的细节信息,并结合自身使用Nagios的经验介绍了一些高级主题,带领读者对Nagios的软件生态系统进行系统化的思考。 最佳实践 David明确了在监控解决方案的建设过程中,对被监控的业务和技术的深刻理解非常重要。他声称这是一个“过程方法”,实施过程应当是经过深思熟虑,而非东拼西凑的。在他看来,拼凑的方法存在很多问题,通常不会探讨监控解决方案中深层次关键技术方面。这本书为大家提供了一些建议,主要聚焦于被关注系统的一些全局特征,包括:需求的处理、系统所处的网络位置、网络依赖、系统安全、报警的滥用以及端口与应用监视的对比分析。
尽管本书前面预先介绍了实施中所需的大量架构和业务知识,但Nagios依旧避免对被监控的大量系统作出假设。其实,Nagios自身无任何监控功能,设计它的目的是对监控检测的调度,并根据检测结果进行相应的通知。Nagios将实际的监控功能委托给能够返回状态文本的插件,通过这种方式,它可以避免对一体化的Agent产生依赖,从而符合Unix的设计哲学。Doug Mcllroy将Unix的设计哲学总结如下:
“编写专一并且专注的程序(只做一件事,并把它做好)。编写能够协作的程序(程序间能够相互调用)。编写能够对文本流进行处理的程序,因为这是一种通用的接口。”
运作原理
Nagios使用一套定义明确的范式,其中包含“主机”和“服务”两个主要的逻辑对象,这是对被监控系统及其组成部分抽象的结果。服务属于主机,并且能够包含主机间或是服务间的关系——这就是依赖的概念。Nagios将主机和服务检测的重任转交给状态评估的插件管理,基本上每种类型的检测都拥有自己的插件。David借此机会详细介绍了Windows和Unix系统的监控方式。在Windows环境中提供的脚本开发技术包括:Wscript、OLE、COM、WMI以及PowerShell。NSClient++通过NRPE协议为Nagios和Windows脚本开发技术之间提供了提供了接口层。David认为NRPE插件是Unix/Linux系统的远程执行的首选工具,通过它作为接口可以调用bash、Python、Ruby、PERL等语言编写的插件以及命令行系统工具。David通过检查Nagios为其他对象(如网络设备和环境传感器)扩展监控的能力,完善了Nagios使用插件监控的精髓。
书中很清楚地表明Nagios实质上是一套调度和通知系统。Nagios通过先进的算法调度服务检测——如长检测(Long Check Execution)执行、故障状态重试、为避免避免远程系统产生较高负载的交错检测以及延迟检测等手段,从而管控Nagios服务器负载。Nagios依然会并发运行检测,然后使用信息收集进程(Reaper)从消息队列中获得结果。Nagios根据状态的变化以及状态的类型(确定(Hard)或待定(Soft))触发通知。通知事件可以转而配置为发送电子邮件、或调用类似Pager Duty这样的系统(译者注:Pager Duty是一款告警通知系统,支持告警聚合、自动升级等功能,提供多种通知方式。)。另外,当问题持续时间过长时,还可以通过升级规则(Escalation)进行进一步的告警。此外,正常(OK)状态会先过渡到待定(Soft)状态,从而减少重要性较低的瞬态问题的通知。
Nagios通过提供灵活的I/O接口完善了其以高度集中为目的的算法核心,从而使自身成为一套更为强大的记录、监控解决方案架构的一部分。主要的I/O接口包括Web界面、报表、Nagios用于处理命令的外部命令文件、性能数据处理以及先进的低层事件代理集成功能。性能数据处理功能为使用轮循数据库工具(如RRDtool)、图形系统(如Graphite)的高级可视化提供了集成点(Integration Point)。事件代理提供了先进的集成功能,包括通过诸如MKLiveStatus这样的插件所进行的Nagios状态查询,可以实现战术视图(Tactical Display)的集成(如NagVis)。
Nagios XI是Nagios Core衍生出的商业版本,它在Nagios Core基础上增强了配置的易用性——这部分工作通常被认为是Nagios最困难的部分。此外,商业版本同时还提供了专业支持并将一系列功能集成在系统中,而对于开源版本来说,这些功能就需要用户自己动手去集成了。
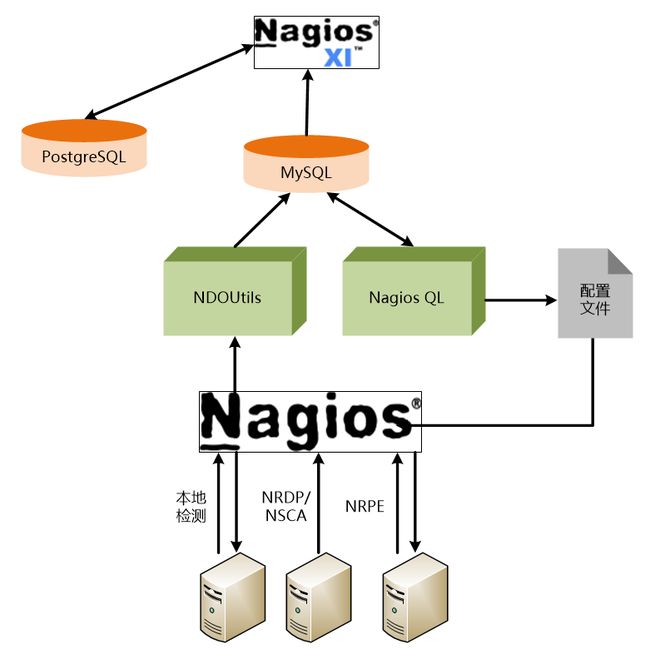
Nagios是一款开源软件,专门为集成而设计。David虽然不打算让本书成为一本介绍编程的深奥书籍,但为了更好的介绍“事件代理(Nagios Event Broker,简称NEB)接口”,为了让读者能够进一步了解构建扩展Nagios核心功能组件的过程,他在本书中恰到好处引入了一份C语言编写的程序。
Nagios系统
David使本书成为一本全面的、深入的介绍Nagios安装、配置、集成、操作的书籍。他编写的内容足以使本书作为参考文档,不仅如此,他带领读者一步步熟悉Nagios软件生态系统,这样,读者就会明白Nagios的目的以及针对特定用途所需要深入研究的技术。
“Nagios守护进程是专为Linux系统设计和运行的,但它也能够在任何类UNIX的操作系统上运行。”
Nagios的守护进程(或服务器)能够很容易地安装在大多数Linux发行版和Unix变种上。在不同系统上安装的过程中,最大的区别就是文件的位置,但大多数人会按照文件系统层次结构标准进行安装:
- 配置文件——/etc/nagios
- HTML——/usr/share/nagios
- CGI目录——/usr/share/nagios或/usr/lib/nagios
- 守护进程以及其他可执行文件——/usr/bin/nagios
- Lock文件以及FIFO文件——/var/lib/nagios或/var/log/nagios
- 日志文件——/var/log/nagios
- 插件——/usr/libexec/nagios或/usr/lib/nagios
由于Nagios是使用C语言编写的,因此只有很少的依赖关系。Nagios的依赖关系完全由所使用的功能和插件所决定。Web前端需要一个支持CGI的Web服务器(例如Apache)。而插件所需的依赖关系就更多了,因为它们才是真正去进行监控的程序——可能会依赖诸如:Ping、OpenSSL、Bind工具、Perl以及Python等等。
Nagios能够通过Linux/Unix分发的特定软件包安装,也可以从源码包安装。两者都使用了标准机制。真正具有难度的是安装后的配置过程。David并不想对文件的设置进行漫长的介绍,虽然他确实在第4章中对配置的设置进行了说明:时间段(Timeperiods)、命令、联系人、联系人组、主机、服务、主机组、服务组、升级规则(Escalations)以及依赖关系(Dependencies)。
在Nagios的架构中,插件需要同时安装在Nagios服务器以及远程系统中。Nagios通过NRPE协议与远程系统上的插件交互。因此,用户必须在在远程系统上安装NRPE,以便通过TCP/IP协议访问NRPE。在远程系统上的NRPE将以服务的形式运行,用户可以通过配置文件对访问服务器的地址以及执行的命令进行限制。
David针对基于独立部署的Nagios守护进程,还专门增加了一整章内容来介绍Nagios的扩展。他从技术方面介绍了:分布式被动检测、二级Nagios守护进程、DNX、Op5 Merlin以及Mod Gearmen等内容。
InfoQ就本书对David Josephsen进行了采访。
InfoQ:在Nagios的实施工作中,提高开发和运维人员之间协作的关键是什么?
David:在过去的20年中,DevOps可能为我们的行业带来了剧变。同时,这是个不错的问题,因为在我来看,系统监控看来就像DevOps中退化回割裂(开发和运维)的那部分,我不认为这是件好事。在此情境下,Nagios的问题一直都出在配置方面。运维类型人员喜欢灵活、稳定的后端(是文件而非数据库),以及针对大量挂钩(Hook)的丰富、复杂的配置参数。开发类型人员则喜欢“能够工作”、清晰的接口以及合适的通用数据模型。Nagios的核心以及如同太阳系一般围绕着它的工具,都趋向于突出这些个性类型的正交性。在类似#monitoringsucks等运动中,记录了开发人员是如何打破了传统Nagios风格的工具的……我想说的是,实施中连接运维和开发的桥梁是围绕接口展开的。如果你在一家公司中负责运维,并且有一支积极向上的开发或DevOps队伍,你需要确保他们有一些看着很熟悉的接口(如JSON/SQL/Web服务等),这就(如果可能)使他们能够在贵公司的变更管理框架下进行变更。否则,他们会围绕着你开展工作。想做到这一点,可能最简单的方法就是为自己的组织购买XI,但是肯定有很多方法可以无需花费金钱,并使开发成为沟通中的一部分。NRDP和其用于被动检测结果的HTTPS/XML接口就是很好的接口示例,可能会吸引我们中间的开发类型的人员。首先是了解他们想要的(他们可能不知道他们想要什么,所以可能第一步是帮助他们了解他们自己想要什么),然后是与他们配合,创建他们所需要的简洁、(他们)无需配置的接口。千里之行,始于足下。
InfoQ:有没有什么软件产品、服务或开源项目能够作为优秀的工单/帮助台系统,并能与Nagios集成?
David:如果读者现在没有帮助台系统,那么Nagios集成将会是各位决策过程中的一个巨大的因素,因为Nagios自带的事件管理——由Nagios Enterprise出品的新一代工单系统将是一个显而易见的选择。XI和事件管理模块简直就是天生一对,所以读者不会有任何集成上的问题。个人而言,我曾经将Nagios与RT、Jira、VersionOne等工具集成,我可以明确的告诉各位,很少会在技术方面出现问题。但将Nagios通过REST API或类似的东西粘合到其它系统是相当繁琐的。如果你不想从头开始,那么也可以依赖于现成的插件。但一旦牵扯到干系人员之间的相互作用时,就不是小事了。如果读者想要与帮助台集成,就需要明确并消除那些误报和无谓的事件。在读者开始计划接口之前,应当花时间考虑下目前发送的Nagios告警内容,这些内容可能会成为帮助台工单不错的“原料”。理想情况下,在系统集成之前,读者应该有一份长度有限的列表——包含了所有可能的告警以及它们的意义/升级参数,从而自如地向帮助台传递信息(更加明确的提示:这份清单应该相当简洁)。
InfoQ的:你是否曾经在测试驱动基础设施开发(Test Driven Infrastructure)的环境中使用Nagios?我的意思是,在被监控系统部署监控之前,这份检查列表就已经做完了——这样当所有的检查都正常时,你就可以认为系统实施完成了。如果你有此经历,能否介绍一下?如果没有,你如何看待这种方式呢?
David:我个人从来没有以这种方式使用Nagios,虽然我认为这是一个好主意——在它们投入生产之前,测试预期系统达到了正确的和预期的状态,但或许有更好的工具来完成类似的事情。比如,现在有很神奇的持续集成系统可供使用,如Hudson和Travis,将这类测试交给它们,比硬塞给Nagios要更加容易。然而,对于这个问题,正式的正确答案可能是使用Chef或其他配置管理引擎。这些才真正是测试驱动基础设施开发的捷径。在Chef的帮助下,用户可以在系统安装到硬盘之前,设计出验证和测试结果都正确的系统。虽然我认为Nagios也可以使用,但我还是要推荐一些别的东西——有两个原因,但读者的环境有所不同,它们也可能不适用,所以我应该告诉各位它们是什么。首先,Nagios实际上是个通知引擎,在这种情境下读者们需要阻止它来避免通知——要么将其配置为不发送通知,要么配置为通知后关闭通知。无论哪种方式,实际上都是在浪费时间,只是会引发我脑海中的强迫症异常(OCD Exception)。第二个读者的测试将会很难设计,或者测试过于简单。我想说的是,读者们可以为Web建立一个测试套件:包含checkhttp、checkping等等。但这些测试太过具体,并且它们明确让各位知道:是的,Web服务器可以工作在这个新环境中,这是唯一一种接近测试驱动基础设施开发的定义。在我将一台服务器投入生产环境中之前,有很多我想了解的内容。理想情况下,我希望它以一个已验证状态工作在生产环境中,而这类工作是依靠Chef来完成的。
关于本书作者
 David Josephsen是DBG公司的系统工程总监,负责维护一群分布在各地的服务器农场(Server Farm)。他有超过十年的运维经验,亲自在复杂、大规模网络环境下维护过UNIX系统、路由器、防火墙、负载均衡等设备。他是《通过Nagios构建监控平台》(原书由Addison Wesely出版)一书的作者,他还撰写了《使用Ganglia进行监控》(原书由O'Reilly Media出版)一书的三个章节。目前他正在负责编写《;login》杂志中的“iVoyer“专栏。
David Josephsen是DBG公司的系统工程总监,负责维护一群分布在各地的服务器农场(Server Farm)。他有超过十年的运维经验,亲自在复杂、大规模网络环境下维护过UNIX系统、路由器、防火墙、负载均衡等设备。他是《通过Nagios构建监控平台》(原书由Addison Wesely出版)一书的作者,他还撰写了《使用Ganglia进行监控》(原书由O'Reilly Media出版)一书的三个章节。目前他正在负责编写《;login》杂志中的“iVoyer“专栏。
查看英文原文:Book Review: "Nagios: Building Enterprise-Grade Monitoring Infrastructures for Systems & Networks"