模式识别:分类回归决策树CART的研究与实现
摘 要:本实验的目的是学习和掌握分类回归树算法。CART提供一种通用的树生长框架,它可以实例化为各种各样不同的判定树。CART算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的决策树的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。在MATLAB平台上编写程序,较好地实现了非剪枝完全二叉树的创建、应用以及近似剪枝操作,同时把算法推广到多叉树。
一、技术论述
1.非度量方法
在之前研究的多种模式分类算法中,经常会使用到样本或向量之间距离度量(distance metric)的方法。最典型的是最近邻分类器,距离的概念是这个分类方法的根本思想所在。在神经网络中,如果两个输入向量足够相似,则它们的输出也很相似。总的来说,大多数的模式识别方法在研究这类问题中,由于特征向量是实数数据,因此自然拥有距离的概念。
而在现实世界中,另外一类酚类问题中使用的是“语义数据”(nominal data),又称为“标称数据”或“名义数据”。这些数据往往是离散的,其中没有任何相似性的概念,甚至没有次序的关系。以下给出一个简单的例子:
试用牙齿的信息对鱼和海洋哺乳动物分类。一些鱼的牙齿细小而精致(如巨大的须鲸),这种牙齿用于在海里筛滤出微小的浮游生物来吃;另一些有成排的牙齿(如鲨鱼);一些海洋动物,如海象,有很长的牙齿;而另外一些,如鱿鱼,则根本没有牙齿。这里并没有一个清楚的概念来表示关于牙齿的相似性或距离度量,打个比方,须鲸和海象的牙齿之间并不比鲨鱼和鱿鱼之间更相似。本实验的目的是将以往以实向量形式表示的模式,转变成以非度量(nonmetric)的语义属性来表示的模式。
2.判定树
利用一系列的查询回答来判断和分类某模式是一种很自然和直观的做法。有一个问题的提法依赖于前一个问题的回答。这种“问卷表”方式的做法对非度量数据特别有效,因为回答问题时的是“是/否”、“真/假”、“属性值”等并不涉及任何距离测度概念。这些实际问题可以用有向的判定树(decision tree)的形式表示。从结构上看,一棵树的第一个节点又称为根节点,存在于最上方,与其他节点通过分支实现有序的相连。继续上述的构造过程,知道没有后续的叶节点为止,下图给出了一个判定树的实例。
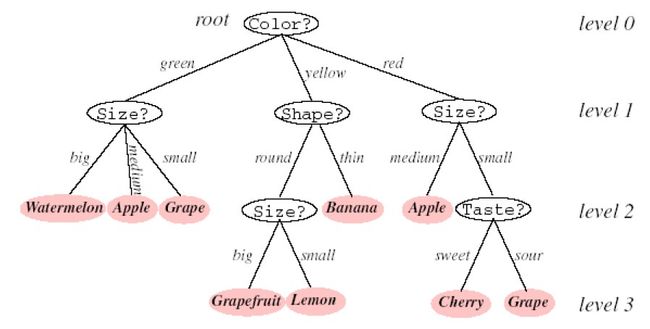
从根节点开始,对模式的某一属性的取值提问。与根节点相连的不同分支,对应这个属性的不同取值,根据不同的结果转向响应的后续子节点。这里需要注意的是树的各分支之间必须是互斥的,且各分支覆盖了整个可能的取值空间。
在把当前到达的节点视为新的根节点,做同样的分支判断。不断继续这一过程直至到达叶节点。每个叶节点都拥有一个相应的类别标记,测试样本被标记为它所到达的叶节点的类别标记。
决策树算法相比其他分类器(如神经网络)的优点之一是,树中所体现的语义信息,容易直接用逻辑表达式表示出。而树分类器的另外一个有点是分类速度快。这是因为树提供了一种很自然的嵌入人类专家的先验知识的机制,在实际中,当问题较为简单且训练样本较少的情况下,这类专家知识往往十分有效。
3.分类和回归树(CART)算法
综合以上概念,这里讨论一个问题,即基于训练样本构造或“生成一棵判定树”的问题。假设一个训练样本集D,该训练集拥有类别标记,同时确定了一个用于判定模式的属性集。对于一棵判定树,其任务是把训练样本逐步划分成越来越小的子集,一个理想的情况是每个子集中所有的样本均拥有同种类别标记,树的分类操作也到此结束,这类子集称为“纯”的子集。而一般情况下子集中的类别标记并不唯一,这时需要执行一个操作,要么接受当前有“缺陷”的判决结果,停止继续分类;要么另外选取一个属性进一步生长该树,这一过程是一种递归结构的树的生长过程。
若从数据结构的角度来看,数据表示在每个节点上,要么该节点已经是叶节点(自身已拥有明确的类别标记),要么利用另一种属性,继续分裂出子节点。分类和回归树是仅有的一种通用的树生长算法。CART提供一种通用的框架,使用者可以将其实例化为各种不同的判定树。
3.1 CART算法的分支数目
节点处的一次判别称为一个分支,它将训练样本划分成子集。根节点处的分支对应于全部训练样本,气候每一次判决都是一次子集划分过程。一般情况下,节点的分支数目由树的设计者确定,并且在一棵树上可能有不同的值。从一个节点中分出去的分支数目有时称为节点的分支率(branching ratio),这里用B表示。这里需要说明一个事实,即每个判别都可以用二值判别表示出来。由于二叉树具有普适性,而且构造比较方便,因此被广泛采用。
3.2 CART算法中查询的选取与节点不纯度
在决策树的设计过程中,一个重点是考虑在每个节点处应该选出测试或查询哪一个属性。我们知道对于数值数据,用判定树的方法得到的分类边界存在着较为自宏观的几何解释;而对于非数值数据,在节点处作查询进而划分数据的过程并没有直接的几何解释。
构造树的过程的一个基本原则是简单。我们期望获得的判定树简单紧凑,只有很少的节点。本着这一目标,应试图寻找这样一个查询T,它能使后继节点数据尽可能的“纯”。这里需要定义“不纯度”的指标。用i(N)表示节点N的“不纯度”,当节点上的模式数据均来自同一类别时,令i(N)=0;若类别标记均匀分布时,i(N)应当比较大。一种最流行的测量称为“熵不纯度”(entropy impurity),又称为信息量不纯度(information impurity):
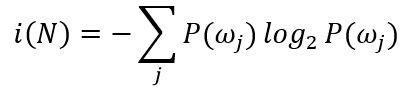
其中P(ωj)是节点N处属于ωj类模式样本数占总样本数的频度。根据熵的特性,如果所有模式的样本都来自同一类别,则不纯度为零,否则则大于零。当且仅当所有类别以等概率出现时,熵值取最大值。以下给出另外几种常用的不纯度定义:
“平方不纯度”,根据当节点样本均来自单一类别时不纯度为0的思想,用以下多项式定义不纯度,该值与两类分布的总体分布方差有关:
![]()
“Gini不纯度”,用于多类分类问题的方差不纯度(也是当节点N的类别标记任意选取时对应的误差率):
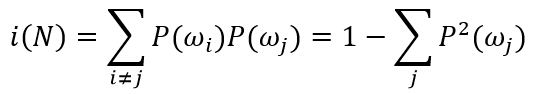
当类别标记等概率时“Gini不纯度”指标的峰度特性比“熵不纯度”要好。
“误分类不纯度”,用于衡量节点N处训练样本分类误差的最小概率:
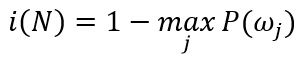
该指标在之前讨论过的不纯度指标中当等概率标记时具有最好的峰值特性。然而由于存在不连续的导数值,因而在连续参数空间搜索最大值时会出现问题。
当给定一种不纯度计算方法,另一个关键问题是:对于一棵树,目前已生长到节点N,要求对该节点作属性查询T,应该如何选择待查询值s?一种思路是选择那个能够使不纯度下降最快的那个查询,不纯度的下降公式可写为:
![]()
其中N_L和N_R分别表示左右子节点,i(N_L)和i(N_R)是相应的不纯度。P_L是当查询T被采纳时,树由N生长到N_L的概率。若采用熵不纯度指标,则不纯度的下降差就是本次查询所能提供的信息增益。由于二叉树的每次查询仅仅给出是/否的回答,所以每次分支所引起的熵不纯度的下降差不会超过1位。
二、实验步骤
训练数据:
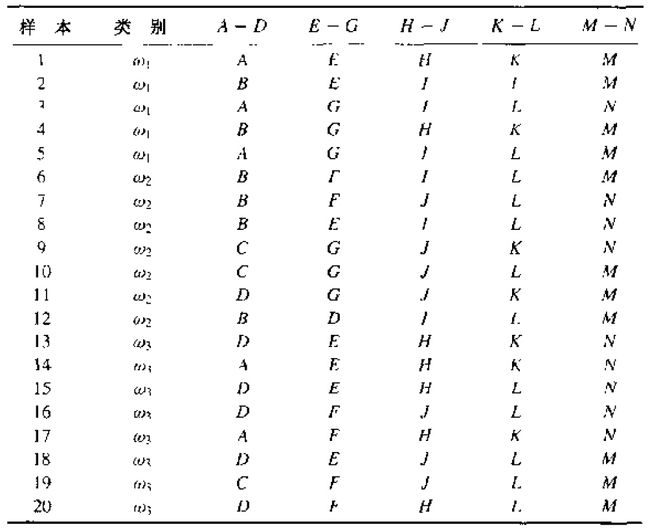
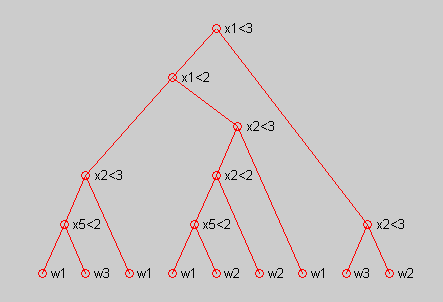
编写一个生成二叉分类树的通用程序,并使用上表中的数据来训练该树,训练过程中使用熵不纯度进行分支。通过过程中的判决条件,使用treeplot函数画出决策二叉树,如下图所示。
用上述程序训练好的非剪枝完全树,分类下列模式:
{A,E,I,L,N},{D,E,J,K,N},{B,F,J,K,M},{C,D,J,L,N}
用上述程序训练好的非剪枝完全树,选择其中的一对叶节点进行剪枝,使剪枝后树的熵不纯度的增量尽可能小。
三、实验结果
使用未剪枝的树进行分类:

使用剪枝后的树进行分类:

四、MATLAB代码
主函数:
clear all; clc; close all;
%% 数据预处理 % 训练样本
w1 = ['AEHKM'; 'BEILM'; 'AGILN'; 'BGHKM'; 'AGILM'];
w2 = ['BFILM'; 'BFJLN'; 'BEILN'; 'CGJKN'; 'CGJLM'; 'DGJKM'; 'BDILM'];
w3 = ['DEHKN'; 'AEHKN'; 'DEHLN'; 'DFJLN'; 'AFHKN'; 'DEJLM'; 'CFJLM'; 'DFHLM'];
w = [w1; w2; w3];
C = [ones(5,1); 2*ones(7,1); 3*ones(8,1)]; % 分类标签
% 数据范围
Region = ['AD'; 'EG'; 'HJ'; 'KL'; 'MN'];
%测试样本
T1 = 'AEILN';
T2 = 'DEJKN';
T3 = 'BFJKM';
T4 = 'CDJLM';
%字符串矩阵 数据转化为 相应的自然数矩阵,方便后续处理
w = w + 0; % w=abs(w)
Region = abs(Region);
global Tree;
global Flag;
%% 非剪枝完全树 %建立一二叉树并用样本进行训练
Tree = CART_MakeBinaryTree(w, C, Region)
p=[0 1 2 3 4 4 3 2 8 9 10 10 9 8 1 15 15];
treeplot(p)%画出二叉树
%使用该分类树
W1 = CART_UseBinaryTree(Tree,T1)
W2 = CART_UseBinaryTree(Tree,T2)
W3 = CART_UseBinaryTree(Tree,T3)
W4 = CART_UseBinaryTree(Tree,T4)
%% B 剪枝 W1=CART_PruningBinaryTree(Tree,T1) W2=CART_PruningBinaryTree(Tree,T2) W3=CART_PruningBinaryTree(Tree,T3) W4=CART_PruningBinaryTree(Tree,T4) %% 多叉树分类
%AnyTree=CART_MakeAnyTree(w, C, Region)
%MultiTree=CART_MakeMultiTree(w, C, Region)
function Tree = CART_MakeBinarySortTree(Train_Samples, TrainingTargets, Region)
% 基于 熵不纯度 递归地实现 非剪枝完全二叉树
% 输入变量:
% Train_Samples:n个d维训练样本,为(n * d)的矩阵
% TrainingTargets:对应的类别属性,为(n * 1)的矩阵
% Region:特征向量维度顺序下上限,为(d * 2)的矩阵(特征值取离散的自然数区间,左小右大)
% 输出变量:一个基本树形节点 Tree
% 基本树形节点结构
% 一:标签(记录当前节点判定所用的维度,表叶子时为空);
% 二:阈值(记录当前所用维度判定之阈值,叶子节点时表类别);
% 三:左枝(小于等于阈值的待分目标 归于此,表叶子时为空)
% 四:右枝(大于阈值的 归于此,表叶子时为空)
[n,Dim] = size(Train_Samples);
[t,m] = size(Region);
if Dim ~= t || m ~= 2
disp('参数错误,请检查');
return;
end
%检查类别属性是否只有一个属性,若是则当前为叶节点,否则需要继续分
if ( length(unique(TrainingTargets)) == 1)
Tree.Label = [];
Tree.Value = TrainingTargets(1);
% 无左右子节点
Tree.Right = [];
Tree.Left = [];
Tree.Num = n;
return;
end
% 如果两个样本 为两类 直接设置为左右叶子
% 差异最大维度做为查询项目
% 单独处理此类情况,做为一种优化方法应对 后面提到的缺陷
if length(TrainingTargets) == 2
[m,p] = max(abs(Train_Samples(1,:) -Train_Samples(2,:)));
Tree.Label = p;
Tree.Value = ((Train_Samples(1,p) +Train_Samples(2,p))/2);
Tree.Num = n;
BranchRight.Right = [];
BranchRight.Left = [];
BranchRight.Label = [];
BranchRight.Num =1;
BranchLeft.Right = [];
BranchLeft.Left = [];
BranchLeft.Label = [];
BranchLeft.Num =1;
if Train_Samples(1,p) > Tree.Value
BranchRight.Value = TrainingTargets(1);
BranchLeft.Value = TrainingTargets(2);
else
BranchRight.Value = TrainingTargets(2);
BranchLeft.Value = TrainingTargets(1);
end
Tree.Right = BranchRight;
Tree.Left = BranchLeft;
return;
end
%确定节点的标签(当前节点判定所用的维度),熵不纯度下降落差最大的维度当选
%依次计算各个维度当选之后所造成的不纯度之和
%每个维度中可选值中 最大值代表本维度
Dvp=zeros(Dim,2); %记录每个维度中最大的不纯度及相应的阈值
for k=1:Dim
EI=-20*ones(Region(k,2)-Region(k,1)+1,1);
Iei=0;
for m = Region(k,1):Region(k,2)
Iei =Iei +1;
%计算临时分类结果 去右边的记为 1
CpI = Train_Samples(:,k) > m;
SumCpI = sum(CpI);
if SumCpI == n || SumCpI == 0 %分到一边去了,不妥,直接考察下一个
continue;
end
CpI = [not(CpI),CpI];
EIt = zeros(2,1);
%统计预计 新分到左右两枝的类别及相应的比率,然后得出熵不纯度
for j = 1:2
Cpt = TrainingTargets(CpI(:, j));
if ( length(unique(Cpt)) == 1) %应对 hist() 在处理同一元素时所存在的异常问题
Pw = 0;
else
Pw = hist(Cpt,unique(Cpt));
Pw=Pw/length(Cpt); % 被分到该类的比率
Pw=Pw.*log2(Pw);
end
EIt(j) = sum(Pw);
end
Pr = length(Cpt)/n;
EI(Iei) = EIt(1) *(1-Pr) + EIt(2) *Pr;
end
[maxEI, p] = max(EI);
NmaxEI = sum(EI == maxEI);
if NmaxEI > 1 %如果最大值有多个,取中间那一个, 稍微改进了默认地只取第一个最大值的缺陷
t = find(EI == maxEI);
p = round(NmaxEI /2);
p = t(p);
end
Dvp(k,1) = maxEI;
Dvp(k,2) = Region(k,1) +p -1;
end
%更新节点标签和阈值
[maxDv, p] = max(Dvp(:,1));
NmaxDv = sum(Dvp(:,1) == maxDv);
if NmaxDv > 1 %如果最大值有多个,采用取值范围较小的那一个维度属性, 稍微改进了默认地只取第一个最大值的缺陷
t = find(Dvp(:,1) == maxDv);
[D,p] = min(Region(t,2) -Region(t,1));
p = t(p);
end
Tree.Label = p;
Tree.Value = Dvp(p,2);
%将训练样本分成两类,对左右子节点分别形成二叉树,需要进行递归调用
CprI = Train_Samples(:,p) > Dvp(p,2);
CplI = not(CprI);
Tree.Num = n;
Tree.Right = CART_MakeBinarySortTree(Train_Samples(CprI,:), TrainingTargets(CprI), Region);
Tree.Left = CART_MakeBinarySortTree(Train_Samples(CplI,:), TrainingTargets(CplI), Region);% 针对 由函数 CART_MakeBinaryTree()生成的二叉树 Tree,给出 Test 类属 W
function W = CART_UseBinarySortTree(tree, testSamples)
% 当前节点不存在左右子结点时,判定为叶节点并返回其类别属性
if isempty(tree.Right) && isempty(tree.Left)
W = tree.Value;
return;
end
% 非叶节点的判决过程
if testSamples(tree.Label) > tree.Value
W = CART_UseBinarySortTree(tree.Right,testSamples);
else
W = CART_UseBinarySortTree(tree.Left,testSamples);
endfunction W = CART_PruningBinarySortTree(tree, Samples)
% 针对 由函数 CART_MakeBinaryTree()生成的二叉树 Tree,按样本 Samples 遍历Tree
%如果 发现有与叶子共父节点的长枝条,并且其数量不多于叶子中的样本数,则将其父节点设为叶子,类别属性取多数
%由于程序编写上一时间没能用Matlab语言实现对二叉树的修改,所以没有真实地修剪树,但是起到的修剪之后的效果,
%遇到叶子时,就可以返回其类别属性
TempLift=tree.Left;
TempRight=tree.Right;
LeftEmpty =isempty(TempLift.Right) && isempty(TempLift.Left);
RightEmpty=isempty(TempRight.Right) && isempty(TempRight.Left);
if LeftEmpty && RightEmpty %遇到挂有 两叶子节点,执行剪枝,择多归类
if TempLift.Num > TempRight.Num
W=TempLift.Value;
else
W=TempRight.Value;
end
return;
elseif LeftEmpty || RightEmpty %遇到挂有 一个叶子 和 一个子父节点,比较,择多归类
if LeftEmpty && (TempLift.Num > TempRight.Num /3)
W=TempLift.Value;
return;
elseif RightEmpty && (TempRight.Num > TempLift.Num /3)
W=TempRight.Value;
return;
end
end
if Samples(tree.Label) > tree.Value
if RightEmpty
W = tree.Right.Value;
return;
else
W = CART_PruningBinarySortTree(tree.Right,Samples);
end
else
if LeftEmpty
W = tree.Left.Value;
return;
else
W = CART_PruningBinarySortTree(tree.Left,Samples);
end
end参考书籍:Richard O. Duda, Peter E. Hart, David G. Stork 著《模式分类》