Hadoop Serialization -- hadoop序列化详解 (3)【ObjectWritable,集合Writable以及自定义的Writable】
前瞻:本文介绍ObjectWritable,集合Writable以及自定义的Writable TextPair
回顾:
前面了解到hadoop本身支持java的基本类型的序列化,并且提供相应的包装实现类:
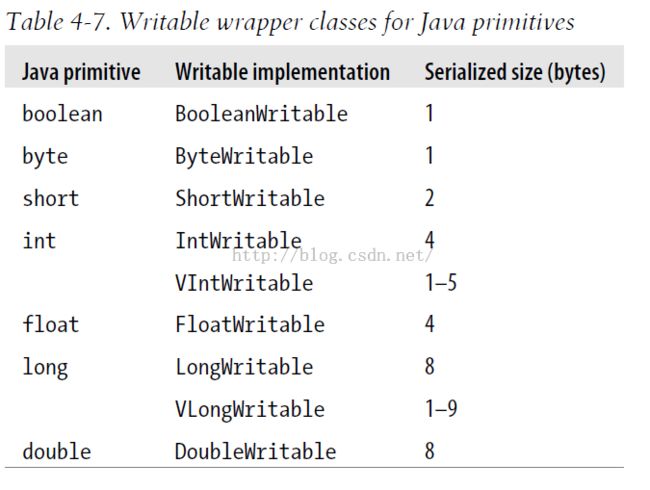
这并不是包含了所有的java数据类型,比如我们要序列化的对象是Object类型的,或者是常用的集合类型list,map那该怎么办呢?
别怕,我们hadoop也提供相应的序列化实现,可以轻松的面对这样的问题。
ObjectWritable ,GenericWritable
ObjectWritable 是一种多用途的封装,他针对Java 基本类型、字符串、枚举、Writable 、空值或任何一种此类类型的数组, 它使用Hadoop 的RPC 来封送(marshal)和反封送(unmarshall )方法参数和返回类型.
譬如说,当我们面临一个字段需要使用多种类型时,ObjectWritable 是一个绝佳选择。它如同java的Object一样,可以指向他的任何子类。例如,如果在一个SequenceFile 中的值有多种类型,就可以将值类型声明为ObjectWritable 并把每个类型封装到一个Objectwritable 中。
当然,Objectwritable 作为一个通用机制,这是相当浪费空间的,因为每次它被序列化肘,都要写入被封装类型的类名。GenericWritable 对此做出了改进,如果类型的数量不多并且事先可知,那么可以使用一个静态类型数组来提高效率,使用数组的索引来作为类型的序列化引用.这是GenericWritable 使用的方法,我们必须继承它以指定支持的类型。
但我们需要序列化一个list或者map的时候,我们怎么办呢?
Writable 集合
org .apache.hadoop.io 包中有四种Writable 集合类型,分别是ArrayWr itable.TwoDArrayWritable , MapWritable 和SortedMapWritable ,ArrayWritable 和TwoDArrayWritable 是Writable 针对数组和二维数组(数组的数组)实例的实现.所有对ArrayWritable 或者 woDArrayWritable 的使用都必须实例化相同的类,这是在构造时指定的,如下所示:
ArrayWritable writable = new ArrayWritable(Text.class);
在上下文中,Writable由类型来定义,如在SequenceFile 中的键或值,或是作为MapReduce 的输入数据类型,需要继承ArrayWritable( 或恰当用TwoDArrayWritable )以静态方式来设置类型。例如:
public class TextArrayWritable extends ArrayWritable {
public TextArrayWritable() {
super(Text.class);
}
}
ArrayWritable 和TwoDArrayWritable 都有get ( ) 和set ( ) 方法,也有toArray() 方泣,后者用于创建数组(或者二维数组)的拷贝。
MapWritable 和SortedMapWritable 分别是java.util.Map(Writable ,Writable) 和java. util.SortedMap ( WritableComparableWritable) 的实现.每个键/值字段的类型都是此字段序列化格式的一部分。类型保存为单字节,充当一个数组类型的索引。数组是用。apache . hadoop . io 包中的标准类型来填充的,但自定义的Writable 类型也是可以的.编写一个头,为非标准类型编码类型数组。正如它们所实现的那样. MapWritable 和SortedMapWritable 使用正值byte 值来表示自定义类型,因此最大值为127 的非标准Writable 类可以用于任何MapWritabl e 或SortedMapWritable 实例.下面是MapWritable 的用法示例,针对不同的键/值对,使用不同的类型:
MapWritable src = new MapWritable();
src.put(new IntWritable(1), new Text("cat"));
src.put(new VIntWritable(2), new LongWritable(163));
MapWritable dest = new MapWritable();
WritableUtils.cloneInto(dest, src);
assertThat((Text) dest.get(new IntWritable(1)), is(new Text("cat")));
assertThat((LongWritable) dest.get(new VIntWritable(2)), is(new LongWritable(163)));
很显然Writable 没有对集合和列表的实现,也就是没有对collection list sets 和table的实现。集合可以使用值为NullWritable的MapWritable(或对一个排序集使用SortedMapwritable )来模拟.也就是存储在key里面,value统一存储NullWritable。对Writable单类型的列表 ArrayWritable 足够了,但是存储不间的类型在一个单列表中,可以使用GenericWritable 封装到ArrayWritable 中。同时,也可以用MapWritable 的思路写一个通用的ListWritable。
没有集合和列表的实现,可能会导致不便,但是暂时的替换方法已经足够。而且hadoop多处理键值对这样的数据,所以应该不是一个很大的问题。
自定义的Writable(以一个含有两个Text的TextPair为例)
Hadoop 自带一系列有用的Writable 实现,可以满足绝大多数用途.但有时,我们需要编写自己的自定义实现.通过自定义Writable , 我们能够完全控制二进制表示和排序顺序. Writables 是MapReduce 数据路径的核心,所以调整二迸制表示对其性能有显著影响。现有的Hadoop Writable 应用已得到很好的优化,但为了对付更复杂的结构, 最好创建一个新的Writable 类型,而不是使用已有的类型。为了横示如何创建一个自定义的Writable ,我们编写了一个表示一对字符串的实现,名为TextPair:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
// cc TextPair A Writable implementation that stores a pair of Text objects
// cc TextPairComparator A RawComparator for comparing TextPair byte representations
// cc TextPairFirstComparator A custom RawComparator for comparing the first field of TextPair byte representations
// vv TextPair
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
//同上调用成员对象本身的readFields方法,从输入流中反序列化每一个成员对象
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
/*MapReduce需要一个分割者(Partitioner)把map的输出作为输入分成一块块的喂给多个reduce)
* 默认的是HashPatitioner,他是通过对象的hashcode函数进行分割,所以hashCode的好坏决定 * 了分割是否均匀,他是一个很关键性的方法。
/
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
//* 如果你想自定义TextOutputformat作为输出格式时的输出,你需要重写toString方法
@Override
public String toString() {
return first + "\t" + second;
}
// * implements WritableComparable必须要实现的方法,用于比较 排序
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
|
此实现的第一部分直观易懂:有两个Text 实例变量( first 和second )和相关的构造函数、get 方法和set 方法。所有的Writable 实现必须有一个默认的构造函数,以便MapReduce 框架能够对它们进行实例化,进而调用readFields ()方法来填充它们的字段。Writable 是易变的、经常重用的,所以我们应该尽量避免在write() 或readFields ()方法中分配对象。
通过委托给每个Text 对象本身. TextPair 的write() 方法依次序列化输出流中的每一个Text 对象。同样,也通过委托给Text 对象本身, readFields () 反序列化输入流中的字节。DataOutPut 和Datalnput 接口有丰富的整套方法用于序列化和反序列化Java 基本类型.所以在一般情况下,我们能够完全控制Writable 对您的数据传输格式。
正如为Java 写的任意值对象一样,我们会重写java . lang . Object 的hashCode ( ), equals ( )和toString () 方法。HashPartitioner 使用hashCode ()来选择reduce 分区,所以应该确保写一个好的哈希函数来确保reduce 函数的分区在大小上是相当的
.TextPair 是Writablecomparable 的实现, 所以提供了compareTo ( ) 方泌的实现,加入我们希望的顺序:它通过一个一个String 逐个排序.我们利用Text本身自带的compare就可以实现比较了。
改进:实现一个高速的RawComparator
以上代码能够有效工作, 但还可以进一步优化.正如前面所述,在MapReduce 中. TextPair 被用作键时, 它必须被反序列化为要调用的compareTo ( )方法的对象(因为我们使用的是Text自带的compare啊,Text自带的compare是需要反序列化才能够compare的)。那么,是否可以通过查看其序列化表示的方式就可以来比较两个TextPair对象?
想起之前我们接触到的RawComparator,我们发现可以这样做,因为TextPair 由两个Text 对象连接而成, 二进制Text 对象表示是一个可变长度的整型,包含UTF-8 表示的字符串中的字节数, 后跟UTF-8 字节本身.关键在于该取开始的长度,从而得知第一个Text 对象的字节表示有多长,然后可以委托Text 对象的RawComparator ,然后利用第一或者第二个字符串的偏移量来调用它。下面给出具体方法(注意, 该代码嵌套在TextPair 类中)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2) {
try {
/**
* Text是标准的UTF-8字节流,
* 由一个变长整形开头表示Text中文本所需要的长度,接下来就是文本本身的字节数组
* decodeVIntSize返回变长 整形的长度,readVInt 表示 文本字节数组的长度,加起来就是第一个成员first的长度
*/
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);//首先比较first
if (cmp != 0) {
return cmp;
}
//如果first一样,那就比较second second的位置要在s1的位置上加firstL1,长度要总长度减去第一个first的长度
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
static {
WritableComparator.define(TextPair.class, new Comparator());//定义我们compare用哪个
}
|
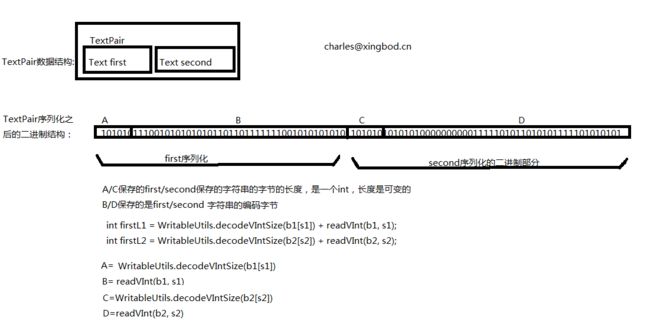
事实上,我们一般都是继承WritableComparator ,而不是直接实现RawComparator ,因为它提供了一些便利的方法和默认实现。这段代码的精妙之处在于计算' firstL1 和firstL2 ,每个字节流中第一个Text 字段的长度。每个都可变长度的整型(由WritableUtils 的decodeVlntSize() 返回}和它的编码值(囱readVint ()返回)组成。静态代码块注册原始的comparator 以便MapReduce 每次看到TextPair 类,就知道使用原始comparator 作为其默认comparator 。
自定义comparator
从TextPair 可知,编写原始的comparator 比较费力,因为必须处理字节级别的细节。如果需要编写自己的实现, org. apache .hadoop.io包中Writable 的某些前瞻性实现值得研究研究。WritableUtils 的有效方法也比较非常方便。如果可能,还应把自定义comparator 写为RawComparators . 这些comparator 实现的排序顺序不同于默认comparator 定义的自然排序顺序。下面代码 显示了TextPair的comparator ,称为First Comparator ,只考虑了一对Text 对象中的第一个字符。请注意,我们重写了compare () 方法使其使用对象进行比较,所以两个compare () 方法的语义是相同的。
这样完整的TextPair如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
|
// cc TextPair A Writable implementation that stores a pair of Text objects
// cc TextPairComparator A RawComparator for comparing TextPair byte representations
// cc TextPairFirstComparator A custom RawComparator for comparing the first field of TextPair byte representations
// vv TextPair
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
//同上调用成员对象本身的readFields方法,从输入流中反序列化每一个成员对象
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
/*MapReduce需要一个分割者(Partitioner)把map的输出作为输入分成一块块的喂给多个reduce)
* 默认的是HashPatitioner,他是通过对象的hashcode函数进行分割,所以hashCode的好坏决定 * 了分割是否均匀,他是一个很关键性的方法。
/
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
//* 如果你想自定义TextOutputformat作为输出格式时的输出,你需要重写toString方法
@Override
public String toString() {
return first + "\t" + second;
}
// * implements WritableComparable必须要实现的方法,用于比较 排序
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
// ^^ TextPair
// vv TextPairComparator
public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1,
b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
static {
WritableComparator.define(TextPair.class, new Comparator());//注册WritableComparator
}
// ^^ TextPairComparator
// vv TextPairFirstComparator自定义实现的comparator
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
// ^^ TextPairFirstComparator
// vv TextPair
}
// ^^ TextPair
|
此致。
Charles 2015-12-26 于Phnom Phen
版权说明:
本文由Charles Dong原创,本人支持开源以及免费有益的传播,反对商业化谋利。
CSDN博客:http://blog.csdn.net/mrcharles
个人站:http://blog.xingbod.cn
EMAIL:[email protected]