关于Netflix Prize的总结
PS:内容翻译自Quora
我试着在这里说些想法。矩阵分解技术和模型组合方法可能是与Netflix Prize有关最多被讨论的算法,但我们也使用了很多其他的洞见。
Normalization of Global Effects 全局效应的正常化
假设Alice给《盗梦空间》打4分。我们可认为这个评分由以下几部分组成:
- 基准分(比如所有用户给电影打的分的均值是3.1分)
- Alice的专门效应(比如爱丽丝倾向于打出比平均值低的分,因此她的打分比我们正常所期望的要低0.5分)
- 盗梦空间的专门效应(比如盗梦空间是很棒的电影,因此它的分值比我们所希望的要高0.7分)
- Alice和盗梦空间之间难以预测的交互效应,占了余下的分值(比如Alice真心喜欢盗梦空间,因为他的莱昂纳多和脑科学的组合,因此又得到额外的0.7分)
换句话,我们把这4分分解成4 = [3.1 (基准分) – 0.5 (Alice的专门效应) + 0.7(盗梦空间的专门效应) + 0.7(特别的交互效应)因此与其让我们的模型预测4分本身,我们也可以首先试着去除基准预测的效应(前三部分)然后预测这特别的0.7分(我想你也可以认为这就是一种简单的boosting)
更一般的,基准预测的其他例子还有:
- 一个因素:允许Alice的打分(线性的)依赖于自从她开始打分的天数的(平方根)。(比如,你是否注意到随着时间增加你变成更严厉的评论家)
- 一个因素:允许Alice的打分依赖于所有人可以给电影打分的天数(如果你是一个最先看到这部电影的人,可能因为你是一个资深粉丝然后真心兴奋于在DVD上看到他,因此你会偏重于给他打高分)
- 一个因素:允许Alice的打分依赖于所有给盗梦空间打过分的人数。(可能爱丽丝是个讨厌跟风的潮人)
- 一个因素:允许Alice的打分依赖于电影的全体打分。
- 加上一堆其他的。
事实上,对这些偏倚建模被证明相当重要:在他们给出最终解决的论文中,Bell和Koren写道:
在众多有贡献的新算法中,我想强调一个——那些粗陋的基准预测(偏倚)捕捉到的数据中的主效应。虽然文献大多集中在更复杂的算法方面,但我们已经知道,对主效应的准确对待未来很可能是至少跟建模算法一样有效的突破点。
ps: 为什么消除这些偏见是有用的?我们有一个更具体的例子,假设你知道Bob和Alice喜欢同一类的电影,预测Bob对盗梦空间的评分,代之以简单预测其像Alice一样打4分,如果我们知道Bob通常比平均分高0.3分,我们就可以去掉Alice的偏倚然后加上Bob的:4 + 0.5 + 0.3 = 4.8
Neighborhood Models 邻居模型
让我们看看一些更复杂的模型。当提到上面的部分时,一个标准的方法就是用邻居模型进行协同过滤。邻居模型主要按照以下工作。为预测Alice对《铁达尼号》的评分,有两件事可以做。
- 基于item的方法:找出与铁达尼号类似的Alice也有打分的item集合,然后把Alice在其上的评分求加权和。
- 基于user的方法:找出与Alice类似的也给铁达尼号打分的user集合,然后求出他们对铁达尼号的评分的均值。
简单以基于item方法为例,我们主要的问题是
- 怎样找到相似item的集合
- 怎样确定这些相似item评分的加权值
标准的方法是使用一些相似性的度量(比如相关性和雅可比指标)来定义电影对之间的相似性,使用在此度量下K个最相似的电影(K可能是用交叉验证选择的),在计算加权平均数时用同样的相似性度量。但这有很多问题
- 邻居不是独立的,所以用标准的相似性度量定义加权平均时造成信息重复计算。举例而言,假设你询问五个朋友今天晚上吃什么。由于其中有三个人上周去了墨西哥因此厌烦了burritos(一种墨西哥玉米煎饼),所以他们强烈不建议去taqueria(一家专卖煎玉米卷的墨西哥快餐馆)。与你去五个互相完全不认识的朋友相比,这五个朋友的建议有强烈的偏见。(与此可以类比的是,三部指环王电影都是哈利•波特的邻居)
- 不同的电影应可能有不同数量的邻居。有些电影可能仅仅使用一个邻居就可以预测的很好(比如哈利波特2只需单个的哈利波特1即可预测的很好),有些电影需要很多,还有些电影可能就没有好的邻居,这时你应该完全忽略邻居算法而让其他打分模型作用到这些电影上去。
所以另一种途径是如下:
- 你可以仍然使用相关性或者预先相似性来选择相似的items
- 但并非使用相似性度量来确定插值权重的平均值计算,基本上用执行(稀疏)的线性回归以找到权重,最小化item评分和他邻居评分的线性组合的误差平方和。(一个略微复杂的基于user的方法与基于item的邻居模型也很有用)
Implicit Data 隐性数据
在邻居模型之上,也可以让隐性数据影响我们的预测。一个小的事实比如用户给很多科幻电影打分而没有给西部电影打分,暗示了用户喜欢科幻多过牛仔。所以使用与邻居打分模型相似的框架,我们可以对盗梦空间学习到与它电影邻居相联系的偏移量。无论我们想怎么预测Bob在盗梦空间上的打分,我们看一下Bob是否给盗梦空间的邻居电影打分了。如果有,我们加上一个相关的偏移;如果没有,我们不加(这样,Bob的打分就被隐性惩罚了)
Matrix Factorization 矩阵分解
用于补充协同过滤的邻居方法是矩阵分解方法。鉴于邻居方法是非常局部的评分方法(如果你喜欢哈利波特1那么你会喜欢哈利波特2),矩阵分解方法提供了更全局的观点(我们知道你喜欢幻想类的电影而哈利波特有很强的幻想元素,所以你会喜欢哈利波特),将用户和电影分解为隐变量的集合(可认为是类似幻想或者暴力的属性)。事实上,矩阵分解方法大概是赢得Netflix Prize技术中最重要的部分。在2008写就的论文中,Bell和Koren写到:
ps: 似乎基于矩阵分解的模型是最精确(因此也最流行),在最近关于Netflix Prize的出版物和论坛讨论都很明显。我们完全同意,并想将这些矩阵分解模型加上被时间效应和二元观点所需要提供的重要灵活性。虽然如此,已经在大多数文献中占很主导的邻居模型仍然会继续流行,这根据他的实际特点——无需训练就能够处理新的用户评分并提供推荐的直接解释。
找到这些分解的典型方法是在(稀疏)评分矩阵上执行奇异值分解(使用随机梯度下降并正则化factor的权重,可能是限制权重为正以得到某种非负矩阵分解)。(注意这里的SVD与在线性代数里学到的标准的SVD有所不同,因为不是每一个用户在每一步电影上都有评分因而评分矩阵有很多缺失值但我们并不像简单地认为其为0)
在Netflix Prize中一些SVD启发的方法包括
- 标准SVD:只要你已经把用户和电影都表达成隐变量的向量,就可以点乘Alice的向量和盗梦空间的向量以得到其对应的预测评分。
- 渐近SVD模型:代之以用户拥有自己观点的隐变量向量,可以把用户表达为一个由他打过分(或者提供了隐含的反馈)的items集合。所以Alice表达为她已经打过分的item的向量之和(可能是加权的),然后与铁达尼号的隐变量点乘得到预测分值。从实用的观点来看,这个模型有额外的优点即不需要用户参数化,因此用这个方法一旦用户产生反馈(可以仅仅是看过item而不必要评分)就可以产生推荐,而不需要重新训练模型以包含用户因素。
- SVD++模型:同时用户本身因素和items集合因素表达用户是以上两者的综合。
Regression 回归
一些回归模型也被用来预测。我认为该模型相当标准,因此不在这里花费太久。基本上,正如邻居模型,我们可以采取以用户为中心的方法和以电影为中心的方法来做回归。
- 以用户为中心:我们为每个用户训练回归模型,使用所有用户的评分数据作为数据集。响应变量是用户对该电影的评分,预测变量是与该电影有关的属性(可以由比如说PCA,MDS或SVD推出)
- 以电影为中心:类似的,可以对每部电影学习回归,用所有对这部电影打分的客户作为数据集。
Restricted Boltzmann Machines 有限波尔兹曼机
有限波尔兹曼机提供了另一种可使用的隐变量方法。如下论文是如何应用该方法到Netflix Prize上的描述(如果这论文难于阅读,这里有RBMs的简介).
Temporal Effects 当时效应
很多模型包含当时的效应。举例而言,当描述以上提到的基准预测时,我们使用一些时间有关的预测允许用户的评分(线性的)依赖于从他首次评分开始的时间和电影首次被评分的时间。我们也可以得到更细粒度的时间效应:把电影按时间分为几个月的评分,允许电影在每个分类下改变偏倚。(例如大概是2006年5月,时代杂志提名铁达尼号为有史以来最佳电影,因此那段时间对该电影的收视评分冲刺增长)。在矩阵分解方法中,用户因素也认为是时间相关的。也可以给最近的用户行为更高权重。
Regularization 正则化
正则化也用于很多模型的学习以防止数据集上的过拟合。岭回归在分解模型中大量使用于对较大的权重做惩罚,Lasso回归(尽管不那么有效)也是有用的。很多其他的参数(例如基准预测,邻居模型中的相似性权重和插值权重)也使用非常标准的shrinkage技术进行估计。
Ensemble Methods 组合方法
最后谈谈怎么把所有不同的算法组合以提供一个利用每个模型有点的单一评分(ps: 注意,就像上面提到的一样,这些模型中很多都不是在原始的评分数据直接训练的,而是在其他模型的剩余数据上)。论文中给出最终解决的细节,冠军叙述了怎样使用GBDT模型组合超过500个模型;之前的解决是使用线性回归来组合预测值。
简要地说,GBDT按照顺序对数据拟合了一系列的决策树;每棵树被要求预测前面的树的误差,并往往略有不同版本的数据。更长的类似的技术的描述,请参看问题.
因为GBDT内置可以引用不同的方法在数据的不同切片上,我们可以添加一些预测,帮助树们使用有用的聚类:
- 每个用户评分的电影数量
- 每部电影评分的用户数量
- 用户和电影的隐变量向量
- 有限玻尔兹曼机的隐藏单元
举例而言,当Bell和Koren在使用更早的混合方法时发现一件事,即当电影或者用户有少量评分时候RBMs更有用,而当电影或者用户有大量评分时矩阵分解方法更有用。这是一张2007年竞赛的混合规模效应的图.
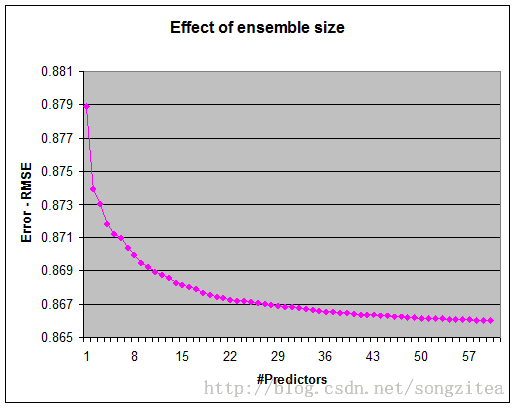
ps: 然而我们要强调的是,没有必要用这么大量的模型也能做好。下面这个图显示RMSE作为使用方法数量的函数。少于50种方法就可以取得我们赢得比赛的分值(RMSE=0.8712),用最好的三种方法可以使RMSE小于0.8800,已经可以进入前十名。甚至只使用最好的单个模型就可以让我们以0.8890进入排行榜。这提示我们,为了赢得比赛使用大量模型是游泳的,但在实用上,优秀的系统可以只使用少数经过精心挑选的模型即可。
最后, 距我完成Netflix Prize的论文已经有一段时间了,记忆与笔记都较粗略,非常欢迎指正和建议。
关于Machine Learning&Pattern Recognition更多讨论与交流,敬请关注本博客和新浪微博songzi_tea.