存储过程和函数总结
MYSQL中创建存储过程和函数分别使用CREATE PROCEDURE和CREATE FUNCTION
使用CALL语句来调用存储过程,存储过程也可以调用其他存储过程
函数可以从语句外调用,能返回标量值
创建存储过程
语法
|
1
|
CREATE
PROCEDURE
sp_name ([ proc_parameter ]) [ characteristics..] routine_body
|
proc_parameter指定存储过程的参数列表,列表形式如下:
|
1
|
[
IN
|
OUT
|INOUT] param_name type
|
其中in表示输入参数,out表示输出参数,inout表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型
该类型可以是MYSQL数据库中的任意类型
有以下取值:
|
1
2
3
4
5
6
7
8
|
characteristic:
LANGUAGE SQL
| [
NOT
] DETERMINISTIC
| {
CONTAINS
SQL |
NO
SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT
'string'
routine_body:
Valid SQL
procedure
statement
or
statements
|
LANGUAGE SQL :说明routine_body部分是由SQL语句组成的,当前系统支持的语言为SQL,SQL是LANGUAGE特性的唯一值
[NOT] DETERMINISTIC :指明存储过程执行的结果是否正确。DETERMINISTIC 表示结果是确定的。每次执行存储过程时,相同的输入会得到
相同的输出。
[NOT] DETERMINISTIC 表示结果是不确定的,相同的输入可能得到不同的输出。如果没有指定任意一个值,默认为[NOT] DETERMINISTIC
CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA:指明子程序使用SQL语句的限制。
CONTAINS SQL表明子程序包含SQL语句,但是不包含读写数据的语句;
NO SQL表明子程序不包含SQL语句;
READS SQL DATA:说明子程序包含读数据的语句;
MODIFIES SQL DATA表明子程序包含写数据的语句。
默认情况下,系统会指定为CONTAINS SQL
SQL SECURITY { DEFINER | INVOKER } :指明谁有权限来执行。DEFINER 表示只有定义者才能执行
INVOKER 表示拥有权限的调用者可以执行。默认情况下,系统指定为DEFINER
COMMENT ‘string’ :注释信息,可以用来描述存储过程或函数
routine_body是SQL代码的内容,可以用BEGIN…END来表示SQL代码的开始和结束。
下面的语句创建一个查询t1表全部数据的存储过程
|
1
2
3
4
5
6
7
8
9
10
|
DROP
PROCEDURE
IF EXISTS Proc;
DELIMITER //
CREATE
PROCEDURE
Proc()
BEGIN
SELECT
*
FROM
t3;
END
//
DELIMITER ;
CALL Proc();
|
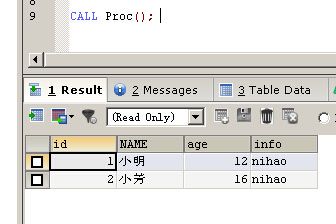
t3表是我们上一节创建的表
这里的逻辑是
1、先判断是否有Proc() 这个存储过程,有就drop掉
2、创建Proc() 存储过程
3、执行Proc() 存储过程
注意:“DELIMITER //”语句的作用是将MYSQL的结束符设置为//,因为MYSQL默认的语句结束符为分号;,为了避免与存储过程
中SQL语句结束符相冲突,需要使用DELIMITER 改变存储过程的结束符,并以“END//”结束存储过程。
存储过程定义完毕之后再使用DELIMITER ;恢复默认结束符。DELIMITER 也可以指定其他符号为结束符!!!!!!!!!!!
如果你是这样写的话,就会得到如下错误,初学者很容易犯这个错误,包括本人
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
CREATE
PROCEDURE
Proc()
BEGIN
SELECT
*
FROM
t3;
END
Query:
CREATE
PROCEDURE
Proc()
BEGIN
SELECT
*
FROM
t3
Error Code: 1064
You have an error
in
your SQL syntax;
check
the manual that corresponds
to
your MySQL server version
for
the
right
syntax
to
use near
''
at
line 3
Execution
Time
: 0 sec
Transfer
Time
: 0 sec
Total
Time
: 0.001 sec
---------------------------------------------------
Query:
END
Error Code: 1064
|
创建名为CountProc的存储过程,代码如下:
|
1
2
3
4
5
6
|
DELIMITER //
CREATE
PROCEDURE
CountProc(
OUT
param1
INT
)
BEGIN
SELECT
COUNT
(*)
INTO
param1
FROM
t3;
END
//
DELIMITER ;
|
上面代码的作用是创建一个获取t3表记录数的存储过程,名称是CountProc,
COUNT(*)计算后把结果放入参数param1中。
注意:当使用DELIMITER命令时,应该避免使用反斜杠(\)字符,因为反斜杠是MYSQL的转义字符!!!
存储函数
创建存储函数,需要使用CREATE FUNCTION语句,基本语法如下:
|
1
2
3
|
CREATE
FUNCTION
func_name([func_parameter])
RETURNS
TYPE
[characteristics...] routine_body
|
CREATE FUNCTION为用来创建存储函数的关键字;func_name表示存储函数的名称
func_parameter为存储函数的参数列表,参数列表如下
|
1
|
[
IN
|
OUT
|INOUT]PARAM_NAMETYPE
|
其中,IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;
param_name表示参数名称;type表示参数类型,该类型可以是MYSQL数据库中的任意类型
RETURNS TYPE语句表示函数返回数据的类型;characteristics:指定存储函数的特性,取值与创建存储过程时相同
创建存储函数,名称为NameByT,该函数返回SELECT语句的查询结果,数值类型为字符串型
|
1
2
3
4
5
6
7
|
DELIMITER //
CREATE
FUNCTION
NameByT()
RETURNS
CHAR
(50)
RETURN
(
SELECT
NAME
FROM
t3
WHERE
id=2);
//
DELIMITER ;
|
注意:RETURNS CHAR(50)数据类型的时候,RETURNS 是有S的,而RETURN (SELECT NAME FROM t3 WHERE id=2)的时候RETURN是没有S的
所以有时候大家可能觉得MYSQL很烦,谁不知是自己写错了
这里有一个方法,就是利用SQLYOG的代码格式化功能,选中要格式化的代码,然后按F12,如果能格式化,证明你的代码没有问题,如果不能格式化
证明你写的代码有问题!!!
不加s的话就会出现语法错误了
|
1
2
3
4
5
6
7
8
9
10
|
Query:
create
function
NameByT()
return
char
(50)
return
(
select
name
from
t3
where
id=2)
Error Code: 1064
You have an error
in
your SQL syntax;
check
the manual that corresponds
to
your MySQL server version
for
the
right
syntax
to
use near
'return char(50)
return (select name from t3 where id=2)'
at
line 2
Execution
Time
: 0 sec
Transfer
Time
: 0 sec
Total
Time
: 0.003 sec
-----------------------------
|
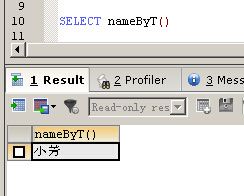
调用函数
|
1
|
SELECT
nameByT()
|
如果在存储函数中的RETURN语句返回一个类型不同于函数的RETURNS子句中指定类型的值,返回值将被强制转换为恰当的类型。
例如,如果一个函数返回一个SET或ENUM值,但是RETURN语句返回一个整数,对于SET成员集的相应ENUM成员,从函数返回的值
是字符串。
指定参数为IN、OUT、INOUT只对PROCEDURE是合法的。
(FUNCTION中总是默认是IN参数)RETURNS子句对FUNCTION做指定,对函数而言这是强制的。
他用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句
变量的使用
变量可以在子程序中声明并使用,这些变量的作用范围是在BEGIN…END程序中
1、定义变量
在存储过程中定义变量
|
1
|
DECLARE
var_name[,varname]...date_type[
DEFAULT
VALUE];
|
var_name为局部变量的名称。DEFAULT VALUE子句给变量提供一个默认值。值除了可以被声明为一个常数外,还可以被指定为一个表达式。
如果没有DEFAULT子句,初始值为NULL
|
1
|
DECLARE
MYPARAM
INT
DEFAULT
100;
|
2、为变量赋值
定义变量之后,为变量赋值可以改变变量的默认值,MYSQL中使用SET语句为变量赋值
|
1
|
SET
var_name=expr[,var_name=expr]...
|
在存储过程中的SET语句是一般SET语句的扩展版本。
被SET的变量可能是子程序内的变量,或者是全局服务器变量,如系统变量或者用户变量
他运行SET a=x,b=y,….
声明3个变量,分别为var1,var2和var3
|
1
2
3
|
DECLARE
var1,var2,var3
INT
;
SET
var1=10,var2=20;
SET
var3=var1+var2;
|
MYSQL中还可以通过SELECT…INTO为一个或多个变量赋值
|
1
2
3
|
DECLARE
NAME
CHAR
(50);
DECLARE
id
DECIMAL
(8,2);
SELECT
id,
NAME
INTO
id ,
NAME
FROM
t3
WHERE
id=2;
|
定义条件和处理程序
特定条件需要特定处理。这些条件可以联系到错误,以及子程序中的一般流程控制。定义条件是事先定义程序执行过程中遇到的问题,
处理程序定义了在遇到这些问题时候应当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。
这样可以增强存储程序处理问题的能力,避免程序异常停止运行
1、定义条件
|
1
2
3
|
DECLARE
condition_name CONDITION
FOR
[condition_type]
[condition_type]:
SQLSTATE[VALUE] sqlstate_value |mysql_error_code
|
condition_name:表示条件名称
condition_type:表示条件的类型
sqlstate_value和mysql_error_code都可以表示mysql错误
sqlstate_value为长度5的字符串错误代码
mysql_error_code为数值类型错误代码,例如:ERROR1142(42000)中,sqlstate_value的值是42000,
mysql_error_code的值是1142
这个语句指定需要特殊处理条件。他将一个名字和指定的错误条件关联起来。
这个名字随后被用在定义处理程序的DECLARE HANDLER语句中
定义ERROR1148(42000)错误,名称为command_not_allowed。
可以用两种方法定义
|
1
2
3
4
5
|
//方法一:使用sqlstate_value
DECLARE
command_not_allowed CONDITION
FOR
SQLSTATE
'42000'
//方法二:使用mysql_error_code
DECLARE
command_not_allowed CONDITION
FOR
SQLSTATE 1148
|
2.定义处理程序
MySQL中可以使用DECLARE关键字来定义处理程序。其基本语法如下:
|
1
2
3
4
5
6
7
8
|
DECLARE
handler_type HANDLER
FOR
condition_value[,...] sp_statement
handler_type:
CONTINUE
| EXIT | UNDO
condition_value:
SQLSTATE [VALUE] sqlstate_value |
condition_name | SQLWARNING
|
NOT
FOUND | SQLEXCEPTION | mysql_error_code
|
其中,handler_type参数指明错误的处理方式,该参数有3个取值。这3个取值分别是CONTINUE、EXIT和UNDO。
CONTINUE表示遇到错误不进行处理,继续向下执行;
EXIT表示遇到错误后马上退出;
UNDO表示遇到错误后撤回之前的操作,MySQL中暂时还不支持这种处理方式。
注意:通常情况下,执行过程中遇到错误应该立刻停止执行下面的语句,并且撤回前面的操作。
但是,MySQL中现在还不能支持UNDO操作。
因此,遇到错误时最好执行EXIT操作。如果事先能够预测错误类型,并且进行相应的处理,那么可以执行CONTINUE操作。
condition_value参数指明错误类型,该参数有6个取值。
sqlstate_value和mysql_error_code与条件定义中的是同一个意思。
condition_name是DECLARE定义的条件名称。
SQLWARNING表示所有以01开头的sqlstate_value值。
NOT FOUND表示所有以02开头的sqlstate_value值。
SQLEXCEPTION表示所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值。
sp_statement表示一些存储过程或函数的执行语句。
下面是定义处理程序的几种方式。代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//方法一:捕获sqlstate_value
DECLARE
CONTINUE
HANDLER
FOR
SQLSTATE
'42000'
SET
@info=
'CAN NOT FIND'
;
//方法二:捕获mysql_error_code
DECLARE
CONTINUE
HANDLER
FOR
<strong>1148</strong>
SET
@info=
'CAN NOT FIND'
;
//方法三:先定义条件,然后调用
DECLARE
can_not_find CONDITION
FOR
1146 ;
DECLARE
CONTINUE
HANDLER
FOR
can_not_find
SET
@info=
'CAN NOT FIND'
;
//方法四:使用SQLWARNING
DECLARE
EXIT HANDLER
FOR
SQLWARNING
SET
@info=
'ERROR'
;
//方法五:使用
NOT
FOUND
DECLARE
EXIT HANDLER
FOR
NOT
FOUND
SET
@info=
'CAN NOT FIND'
;
//方法六:使用SQLEXCEPTION
DECLARE
EXIT HANDLER
FOR
SQLEXCEPTION
SET
@info=
'ERROR'
;
|
上述代码是6种定义处理程序的方法。
第一种方法是捕获sqlstate_value值。如果遇到sqlstate_value值为42000,执行CONTINUE操作,并且输出”CAN NOT FIND”信息。
第二种方法是捕获mysql_error_code值。如果遇到mysql_error_code值为1148,执行CONTINUE操作,并且输出”CAN NOT FIND”信息。
第三种方法是先定义条件,然后再调用条件。这里先定义can_not_find条件,遇到1148错误就执行CONTINUE操作。
第四种方法是使用SQLWARNING。SQLWARNING捕获所有以01开头的sqlstate_value值,然后执行EXIT操作,并且输出”ERROR”信息。
第五种方法是使用NOT FOUND。NOT FOUND捕获所有以02开头的sqlstate_value值,然后执行EXIT操作,并且输出”CAN NOT FIND”信息。
第六种方法是使用SQLEXCEPTION。SQLEXCEPTION捕获所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值,然后执行EXIT操作,并且输出”ERROR”信息
定义条件和处理程序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
CREATE
TABLE
t8(s1
INT
,
PRIMARY
KEY
(s1))
DELIMITER //
CREATE
PROCEDURE
handlerdemo()
BEGIN
DECLARE
CONTINUE
HANDLER
FOR
SQLSTATE
'23000'
SET
@X2=1;
SET
@X=1;
INSERT
INTO
t8
VALUES
(1);
SET
@X=2;
INSERT
INTO
t8
VALUES
(1);
SET
@X=3;
END
;
//
DELIMITER ;
/* 调用存储过程*/
CALL handlerdemo();
/* 查看调用存储过程结果*/
SELECT
@X
|
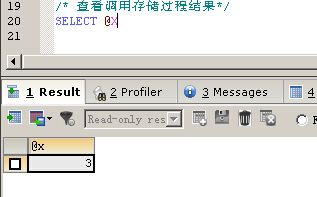
@X是一个用户变量,执行结果@X等于3,这表明MYSQL执行到程序的末尾。
如果DECLARE CONTINUE HANDLER FOR SQLSTATE ’23000′ SET @X2=1;,这一行不存在
第二个INSERT因PRIMARY KEY约束而失败之后,MYSQL可能已经采取EXIT策略,并且SELECT @X可能已经返回2
注意:@X表示用户变量,使用SET语句为其赋值,用户变量与连接有关,一个客户端定义的变量不能被其他客户端所使用
即有作用域的,该客户端退出时,客户端连接的所有变量将自动释放
这里的变量跟SQLSERVER没有什么区别,都是用来存储临时值的
MYSQL这里的条件和预定义程序其实跟SQLSERVER的自定义错误是一样的
光标
MYSQL里叫光标,SQLSERVER里叫游标,实际上一样的
查询语句可能查询出多条记录,在存储过程和函数中使用光标来逐条读取查询结果集中的记录。
光标的使用包括声明光标、打开光标、使用光标和关闭光标。光标必须声明在处理程序之前,并且声明在变量和条件之后。
1.声明光标
MySQL中使用DECLARE关键字来声明光标。其语法的基本形式如下:
|
1
|
DECLARE
cursor_name
CURSOR
FOR
select_statement ;
|
其中,cursor_name参数表示光标的名称;select_statement参数表示SELECT语句的内容,返回一个用于创建光标的结果集
下面声明一个名为cur_employee的光标。代码如下:
|
1
|
DECLARE
cur_employee
CURSOR
FOR
SELECT
name
, age
FROM
employee ;
|
上面的示例中,光标的名称为cur_employee;SELECT语句部分是从employee表中查询出name和age字段的值。
2.打开光标
MySQL中使用OPEN关键字来打开光标。其语法的基本形式如下:
|
1
|
OPEN
cursor_name ;
|
其中,cursor_name参数表示光标的名称。
下面打开一个名为cur_employee的光标,代码如下:
|
1
|
OPEN
cur_employee ;
|
3.使用光标
MySQL中使用FETCH关键字来使用光标。其语法的基本形式如下:
|
1
|
FETCH
cur_employee
INTO
var_name[,var_name…] ;
|
其中,cursor_name参数表示光标的名称;var_name参数表示将光标中的SELECT语句查询出来的信息存入该参数中。var_name必须在声明光标之前就定义好。
下面使用一个名为cur_employee的光标。将查询出来的数据存入emp_name和emp_age这两个变量中,代码如下:
|
1
|
FETCH
cur_employee
INTO
emp_name, emp_age ;
|
上面的示例中,将光标cur_employee中SELECT语句查询出来的信息存入emp_name和emp_age中。emp_name和emp_age必须在前面已经定义。
4.关闭光标
MySQL中使用CLOSE关键字来关闭光标。其语法的基本形式如下:
|
1
|
CLOSE
cursor_name ;
|
其中,cursor_name参数表示光标的名称。
【示例14-11】 下面关闭一个名为cur_employee的光标。代码如下:
|
1
|
CLOSE
cur_employee ;
|
上面的示例中,关闭了这个名称为cur_employee的光标。关闭之后就不能使用FETCH来使用光标了。
注意:MYSQL中,光标只能在存储过程和函数中使用!!
到目前为止存储函数,存储过程、变量、条件、预定义程序、光标跟SQLSERVER差不多,只不过语法不同,结构不同
刚开始的时候会有不适应
流程控制的使用
存储过程和函数中可以使用流程控制来控制语句的执行。
MySQL中可以使用IF语句、CASE语句、LOOP语句、LEAVE语句、ITERATE语句、REPEAT语句和WHILE语句来进行流程控制。
每个流程中可能包含一个单独语句,或者是使用BEGIN…END构造的复合语句,构造可以被嵌套
1.IF语句
IF语句用来进行条件判断。根据是否满足条件,将执行不同的语句。其语法的基本形式如下:
|
1
2
3
4
|
IF search_condition
THEN
statement_list
[ELSEIF search_condition
THEN
statement_list] ...
[
ELSE
statement_list]
END
IF
|
其中,search_condition参数表示条件判断语句;statement_list参数表示不同条件的执行语句。
注意:MYSQL还有一个IF()函数,他不同于这里描述的IF语句
下面是一个IF语句的示例。代码如下:
|
1
2
3
4
|
IF age>20
THEN
SET
@count1=@count1+1;
ELSEIF age=20
THEN
SET
@count2=@count2+1;
ELSE
SET
@count3=@count3+1;
END
IF;
|
该示例根据age与20的大小关系来执行不同的SET语句。
如果age值大于20,那么将count1的值加1;如果age值等于20,那么将count2的值加1;
其他情况将count3的值加1。IF语句都需要使用END IF来结束。
2.CASE语句
CASE语句也用来进行条件判断,其可以实现比IF语句更复杂的条件判断。CASE语句的基本形式如下:
|
1
2
3
4
5
|
CASE
case_value
WHEN
when_value
THEN
statement_list
[
WHEN
when_value
THEN
statement_list] ...
[
ELSE
statement_list]
END
CASE
|
其中,case_value参数表示条件判断的变量;
when_value参数表示变量的取值;
statement_list参数表示不同when_value值的执行语句。
CASE语句还有另一种形式。该形式的语法如下:
|
1
2
3
4
5
|
CASE
WHEN
search_condition
THEN
statement_list
[
WHEN
search_condition
THEN
statement_list] ...
[
ELSE
statement_list]
END
CASE
|
其中,search_condition参数表示条件判断语句;
statement_list参数表示不同条件的执行语句。
下面是一个CASE语句的示例。代码如下:
|
1
2
3
4
|
CASE
age
WHEN
20
THEN
SET
@count1=@count1+1;
ELSE
SET
@count2=@count2+1;
END
CASE
;
|
代码也可以是下面的形式:
|
1
2
3
4
|
CASE
WHEN
age=20
THEN
SET
@count1=@count1+1;
ELSE
SET
@count2=@count2+1;
END
CASE
;
|
本示例中,如果age值为20,count1的值加1;否则count2的值加1。CASE语句都要使用END CASE结束。
注意:这里的CASE语句和“控制流程函数”里描述的SQL CASE表达式的CASE语句有轻微不同。这里的CASE语句不能有ELSE NULL子句
并且用END CASE替代END来终止!!
3.LOOP语句
LOOP语句可以使某些特定的语句重复执行,实现一个简单的循环。
但是LOOP语句本身没有停止循环的语句,必须是遇到LEAVE语句等才能停止循环。
LOOP语句的语法的基本形式如下:
|
1
2
3
|
[begin_label:] LOOP
statement_list
END
LOOP [end_label]
|
其中,begin_label参数和end_label参数分别表示循环开始和结束的标志,这两个标志必须相同,而且都可以省略;
statement_list参数表示需要循环执行的语句。
下面是一个LOOP语句的示例。代码如下:
|
1
2
3
|
add_num: LOOP
SET
@
count
=@
count
+1;
END
LOOP add_num ;
|
该示例循环执行count加1的操作。因为没有跳出循环的语句,这个循环成了一个死循环。
LOOP循环都以END LOOP结束。
4.LEAVE语句
LEAVE语句主要用于跳出循环控制。其语法形式如下:
|
1
|
LEAVE label
|
其中,label参数表示循环的标志。
下面是一个LEAVE语句的示例。代码如下:
|
1
2
3
4
5
|
add_num: LOOP
SET
@
count
=@
count
+1;
IF @
count
=100
THEN
LEAVE add_num ;
END
LOOP add_num ;
|
该示例循环执行count加1的操作。当count的值等于100时,则LEAVE语句跳出循环。
5.ITERATE语句
ITERATE语句也是用来跳出循环的语句。但是,ITERATE语句是跳出本次循环,然后直接进入下一次循环。
ITERATE语句只可以出现在LOOP、REPEAT、WHILE语句内。
ITERATE语句的基本语法形式如下:
|
1
|
ITERATE label
|
其中,label参数表示循环的标志。
下面是一个ITERATE语句的示例。代码如下:
|
1
2
3
4
5
6
7
8
|
add_num: LOOP
SET
@
count
=@
count
+1;
IF @
count
=100
THEN
LEAVE add_num ;
ELSE
IF MOD(@
count
,3)=0
THEN
ITERATE add_num;
SELECT
*
FROM
employee ;
END
LOOP add_num ;
|
该示例循环执行count加1的操作,count值为100时结束循环。如果count的值能够整除3,则跳出本次循环,不再执行下面的SELECT语句。
说明:LEAVE语句和ITERATE语句都用来跳出循环语句,但两者的功能是不一样的。
LEAVE语句是跳出整个循环,然后执行循环后面的程序。而ITERATE语句是跳出本次循环,然后进入下一次循环。
使用这两个语句时一定要区分清楚。
6.REPEAT语句
REPEAT语句是有条件控制的循环语句。当满足特定条件时,就会跳出循环语句。REPEAT语句的基本语法形式如下:
|
1
2
3
4
|
[begin_label:] REPEAT
statement_list
UNTIL search_condition
END
REPEAT [end_label]
|
其中,statement_list参数表示循环的执行语句;search_condition参数表示结束循环的条件,满足该条件时循环结束。
下面是一个ITERATE语句的示例。代码如下:
|
1
2
3
4
|
REPEAT
SET
@
count
=@
count
+1;
UNTIL @
count
=100
END
REPEAT ;
|
该示例循环执行count加1的操作,count值为100时结束循环。
REPEAT循环都用END REPEAT结束。
7.WHILE语句
WHILE语句也是有条件控制的循环语句。但WHILE语句和REPEAT语句是不一样的。
WHILE语句是当满足条件时,执行循环内的语句。
WHILE语句的基本语法形式如下:
|
1
2
3
|
[begin_label:] WHILE search_condition DO
statement_list
END
WHILE [end_label]
|
其中,search_condition参数表示循环执行的条件,满足该条件时循环执行;
statement_list参数表示循环的执行语句。
下面是一个ITERATE语句的示例。代码如下:
|
1
2
3
|
WHILE @
count
<100 DO
SET
@
count
=@
count
+1;
END
WHILE ;
|
该示例循环执行count加1的操作,count值小于100时执行循环。
如果count值等于100了,则跳出循环。WHILE循环需要使用END WHILE来结束。
调用存储过程和函数
存储过程和存储函数都是存储在服务器端的SQL语句的集合,要使用这些已经定义好的存储过程和存储函数就必须要通过调用的方式来实现
存储过程是通过CALL语句来调用的。而存储函数的使用方法与MySQL内部函数的使用方法是一样的
执行存储过程和存储函数需要拥有EXECUTE权限
EXECUTE权限的信息存储在information_schema数据库下面的USER_PRIVILEGES表中
调用存储过程
MySQL中使用CALL语句来调用存储过程。调用存储过程后,数据库系统将执行存储过程中的语句。
然后,将结果返回给输出值。
CALL语句的基本语法形式如下:
|
1
|
CALL sp_name([parameter[,…]]) ;
|
其中,sp_name是存储过程的名称;parameter是指存储过程的参数。
|
1
|
CALL proc()
|
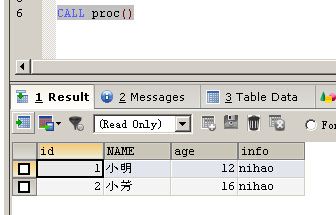
调用存储函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法是一样的。
换言之,用户自己定义的存储函数与MySQL内部函数是一个性质的。
区别在于,存储函数是用户自己定义的,而内部函数是MySQL的开发者定义的。
下面定义一个存储函数,然后调用这个存储函数。
代码执行如下:
|
1
2
3
4
5
6
7
8
9
|
-- 创建存储函数
DELIMITER //
CREATE
FUNCTION
name_from_t3(id
INT
)
RETURNS
CHAR
(80)
RETURN
(
SELECT
NAME
FROM
t3
WHERE
id=id );
//
DELIMITER ;
SELECT
name_from_t3(2);
|
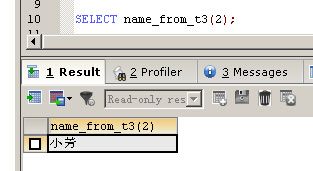
上述存储函数的作用是根据输入的id值到t3表中查询记录。
查询出id字段的值等于id的记录。然后将该记录的name字段的值返回。
查看存储过程和函数
存储过程和函数创建以后,可以查看存储过程和函数的状态和定义。
通过SHOW STATUS语句来查看存储过程和函数的状态,也可以通过SHOW CREATE语句来查看存储过程和函数的定义。
通过查询information_schema数据库下的Routines表来查看存储过程和函数的信息
1、SHOW STATUS语句查看存储过程和函数的状态
MySQL中可以通过SHOW STATUS语句查看存储过程和函数的状态。其基本语法形式如下:
|
1
|
SHOW {
PROCEDURE
|
FUNCTION
} STATUS [
LIKE
' pattern '
] ;
|
其中,PROCEDURE参数表示查询存储过程;FUNCTION参数表示查询存储函数;
LIKE ‘ pattern ‘参数用来匹配存储过程或函数的名称。
下面查询名为name_from_t3的函数的状态。代码执行如下:
|
1
|
SHOW
FUNCTION
STATUS
LIKE
'%name_from_t3%'
|
|
1
2
3
|
Db
Name
Type Definer Modified Created Security_type Comment character_set_client collation_connection
Database
Collation
------ ------------ -------- -------------- ------------------- ------------------- ------------- ------- -------------------- -------------------- ------------------
school name_from_t3
FUNCTION
root@localhost 2014-06-21 18:52:39 2014-06-21 18:52:39 DEFINER utf8 utf8_general_ci utf8_general_ci
|
查询结果显示了函数的创建时间、修改时间和字符集等信息。
注意:SHOW STATUS语句只能查看存储过程或函数是操作哪一个数据库、存储过程或函数的名称、类型、谁定义的、创建和修改时间、字符编码等信息。
但是,这个语句不能查询存储过程或函数的具体定义。如果需要查看详细定义,需要使用SHOW CREATE语句
2、SHOW CREATE语句查看存储过程和函数的定义
MySQL中可以通过SHOW CREATE语句查看存储过程和函数的状态。其基本语法形式如下:
|
1
|
SHOW
CREATE
{
PROCEDURE
|
FUNCTION
} sp_name ;
|
其中,PROCEDURE参数表示查询存储过程;
FUNCTION参数表示查询存储函数;
sp_name参数表示存储过程或函数的名称
下面查询名为name_from_t3的函数的定义。代码执行如下
|
1
|
SHOW
CREATE
FUNCTION
name_from_t3
|
|
1
2
3
4
|
Function
sql_mode
Create
Function
character_set_client collation_connection
Database
Collation
------------ -------- ----------------------------------------------------------------------------------------------------------------------------------------------- -------------------- -------------------- ------------------
name_from_t3
CREATE
DEFINER=`root`@`localhost`
FUNCTION
`name_from_t3`(id
INT
)
RETURNS
char
(80) CHARSET utf8 utf8 utf8_general_ci utf8_general_ci
RETURN
(
SELECT
NAME
FROM
t3
WHERE
id=id )
|
3、从information_schema.Routines表中查看存储过程和函数的信息
存储过程和函数的信息存储在information_schema数据库下的Routines表中。可以通过查询该表的记录来查询存储过程和函数的信息。
其基本语法形式如下:
|
1
2
|
SELECT
*
FROM
information_schema.Routines
WHERE
ROUTINE_NAME=
' sp_name '
;
|
其中,ROUTINE_NAME字段中存储的是存储过程和函数的名称;
sp_name参数表示存储过程或函数的名称。
下面从Routines表中查询名为name_from_t3函数的信息。
代码执行如下:
|
1
|
SELECT
*
FROM
information_schema.Routines
WHERE
ROUTINE_NAME=
'name_from_t3'
|
|
1
2
3
|
SPECIFIC_NAME ROUTINE_CATALOG ROUTINE_SCHEMA ROUTINE_NAME ROUTINE_TYPE DATA_TYPE CHARACTER_MAXIMUM_LENGTH CHARACTER_OCTET_LENGTH NUMERIC_PRECISION NUMERIC_SCALE CHARACTER_SET_NAME COLLATION_NAME DTD_IDENTIFIER ROUTINE_BODY ROUTINE_DEFINITION EXTERNAL_NAME EXTERNAL_LANGUAGE PARAMETER_STYLE IS_DETERMINISTIC SQL_DATA_ACCESS SQL_PATH SECURITY_TYPE CREATED LAST_ALTERED SQL_MODE ROUTINE_COMMENT DEFINER CHARACTER_SET_CLIENT COLLATION_CONNECTION DATABASE_COLLATION
------------- --------------- -------------- ------------ ------------ --------- ------------------------ ---------------------- ----------------- ------------- ------------------ --------------- -------------- ------------ ---------------------------------------------- ------------- ----------------- --------------- ---------------- --------------- -------- ------------- ------------------- ------------------- -------- --------------- -------------- -------------------- -------------------- ------------------
name_from_t3 def school name_from_t3
FUNCTION
char
80 240 (
NULL
) (
NULL
) utf8 utf8_general_ci
char
(80) SQL
RETURN
(
SELECT
NAME
FROM
t3
WHERE
id=id ) (
NULL
) (
NULL
) SQL
NO
CONTAINS
SQL (
NULL
) DEFINER 2014-06-21 18:52:39 2014-06-21 18:52:39 root@localhost utf8 utf8_general_ci utf8_general_ci
|
查询结果显示name_from_t3的详细信息。
注意:在information_schema数据库下的Routines表中,存储着所有存储过程和函数的定义。
如果使用SELECT语句查询Routines表中的存储过程和函数的定义时,一定要使用ROUTINE_NAME字段指定存储过程或函数的名称。
否则,将查询出所有的存储过程或函数的定义。
修改存储过程和函数
修改存储过程和函数是指修改已经定义好的存储过程和函数。
MySQL中通过ALTER PROCEDURE语句来修改存储过程。
通过ALTER FUNCTION语句来修改存储函数。
MySQL中修改存储过程和函数的语句的语法形式如下:
|
1
2
3
4
5
|
ALTER
{
PROCEDURE
|
FUNCTION
} sp_name [characteristic ...]
characteristic:
{
CONTAINS
SQL |
NO
SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT
'string'
|
其中,sp_name参数表示存储过程或函数的名称;
characteristic参数指定存储函数的特性。
CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句;
NO SQL表示子程序中不包含SQL语句;
READS SQL DATA表示子程序中包含读数据的语句;
MODIFIES SQL DATA表示子程序中包含写数据的语句。
SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行。
DEFINER表示只有定义者自己才能够执行;
INVOKER表示调用者可以执行。
COMMENT ‘string’是注释信息。
说明:修改存储过程使用ALTER PROCEDURE语句,修改存储函数使用ALTER FUNCTION语句。
但是,这两个语句的结构是一样的,语句中的所有参赛都是一样的。
而且,它们与创建存储过程或函数的语句中的参数也是基本一样的。
修改存储过程和函数,只能修改他们的权限,目前MYSQL还不提供对已存在的存储过程和函数代码的修改
如果要修改,只能通过先DROP掉,然后重新建立新的存储过程和函数来实现
在SQLYOG里选中选中函数,然后右键ALTER FUNCTION的时候,也是这样,先DROP掉,然后重新建立新的函数来实现
|
1
2
3
4
5
6
7
8
|