hive学习笔记之-数据定义
1. 数据库定义及操作
--创建数据库
hive(default)> SET hive.cli.print.current.db=false;
hive> CREATE DATABASE financials;
--创建库时加判断语句
hive> CREATE DATABASE if not exists financials;
--也可以使用关键字schames 代替database,是一样的
hive> CREATE SCHEMA if not exists financials;
--查看数据库
hive> SHOW DATABASE;
default
financials
hive> SHOW DATABASES LIKE 'fin*';
financials
--指定数据创建目录
hive> CREATE DATABASE financials1
> LOCATION '/user/hive/warehouse/';
--查看数据描述
hive> DESC DATABASE financials1;
financials1 hdfs://nticket1:9000/user/hive/warehouse
Time taken:0.043 seconds, Fetched: 1 row(s)
--指定自定义key-value参数创建数据库及查看
hive> drop database if exists financials;
hive> CREATE DATABASE financials
> WITH DBPROPERTIES ('creator' = 'licz','date' = '2014-01-23');
hive> DESC DATABASE financials;
financials hdfs://nticket1:9000/user/hive/warehouse/financials.db
hive> DESC DATABASE EXTENDED financials ;
financials hdfs://nticket1:9000/user/hive/warehouse/financials.db {date=2014-01-23,creator=licz}
--切换数据库
hive> USE financials1;
hive虽然没有像mysql那样有查看当前数据库的命令,但可以通过hive.cli.print.current.db参数达到同样的目的。
mysql> select database();
+------------+
| database() |
+------------+
| mysql |
+------------+
1 row in set(0.00 sec)
hive> set hive.cli.print.current.db=true;
hive(financials1)> use financials;
hive(financials)>
--删除数据库
hive> DROP DATABASE financials;
hive> DROP DATABASE IF EXISTS financials;
如果数据库下面有表存在,要删除表之后再用上面的语句,否则加cascade子句
hive> DROP DATABASE IF EXISTS financials CASCADE;
2. 修改数据库
hive (financials)>alter database financials set dbproperties ('creator' = 'lichangzai','editedby' = 'licz' );
hive(financials)> desc database extended financials;
financials hdfs://nticket1:9000/user/hive/warehouse/financials.db {edited by=licz, date=2014-01-23,creator=lichangzai}
3. 创建表
下面是一个建表的例子:
hive > create database mydb;
hive >
CREATE TABLE IF NOT EXISTS mydb.employees (
name STRING COMMENT 'Employee name',
salary FLOAT COMMENT'Employee salary',
subordinates ARRAY<STRING> COMMENT 'Names of subordinates',
deductions MAP<STRING, FLOAT>
COMMENT 'Keys are deductions names, values are percentages',
address STRUCT<street:STRING,city:STRING, state:STRING, zip:INT>
COMMENT 'Home address')
COMMENT 'Description ofthe table'
LOCATION '/user/hive/warehouse/mydb.db/employees'
TBLPROPERTIES ('creator'='li','created_at'='2014-1-23 10:00:00');
根据上节的建表语句,上面例子增加了些附加子句
--创建和其它表相同结构的表
CREATE TABLE IFNOT EXISTS mydb.employees2
LIKEmydb.employees;
--查看详细表
hive > descextended mydb.employees;
4. 管理表
Hive中分管理表和外部表,管理表又叫托管表、内部表。
以上创建的表都是管理表,可以表里的数据进行直接操作,删除表后表的内容也被告删除。
5. 外部表
下面是一个例子说明外部表的用法。
--查看外部文件
[licz@nticket1~]$ hadoop dfs -ls /data/stocks
Found 3 items
-rw-r--r-- 2 licz supergroup 8645 2014-01-24 14:17/data/stocks/sz000001.txt
-rw-r--r-- 2 licz supergroup 8368 2014-01-24 14:17/data/stocks/sz000002.txt
-rw-r--r-- 2 licz supergroup 7720 2014-01-24 14:17/data/stocks/sz000003.txt
目录下3个文件,每个文件中有100条记录
内容如下:
[licz@nticket1~]$ hadoop dfs -cat /data/stocks/sz000001.txt|head -5
sz,10000001,2013-07-0800:00:00,1983.215,1983.215,1953.121,1958.273,84136491,2007.199
sz,10000001,2013-07-0500:00:00,2006.191,2021.541,2002.367,2007.199,91345222,2006.098
sz,10000001,2013-07-0400:00:00,1982.870,2022.136,1974.103,2006.098,100394183,1994.268
sz,10000001,2013-07-0300:00:00,1996.506,1996.537,1965.519,1994.268,93466471,2006.560
sz,10000001,2013-07-0200:00:00,1992.890,2007.620,1978.428,2006.560,86415418,1995.242
--创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS stocks (
exchange STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION'/data/stocks';
--查看外部表记录
hive (mydb)>select * from stocks limit 10;
OK
sz 10000001 2013-07-08 00:00:00 1983.215 1983.215 1953.121 1958.273 84136491 2007.199
sz 10000001 2013-07-05 00:00:00 2006.191 2021.541 2002.367 2007.199 91345222 2006.098
sz 10000001 2013-07-04 00:00:00 1982.87 2022.136 1974.103 2006.098 100394183 1994.268
sz 10000001 2013-07-03 00:00:00 1996.506 1996.537 1965.519 1994.268 93466471 2006.56
hive (mydb)>select count(*) from stocks;
300
--创建结构相同的空表
和管理表一样,外部表也能用like创建和其它表管理表一样的空表
CREATE EXTERNAL TABLE IF NOT EXISTS mydb.employees3
LIKEmydb.employees
LOCATION'/path/to/data';
6. 分区表
分区管理表
--创建分区表
DROP TABLE IFEXISTS employees;
CREATE TABLE employees (
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
PARTITIONED BY(country STRING, state STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':';
hive (mydb)>desc employees;
OK
name string None
salary float None
subordinates array<string> None
deductions map<string,float> None
address struct<street:string,city:string,state:string,zip:int> None
country string None
state string None
# PartitionInformation
# col_name data_type comment
country string None
state string None
Time taken:0.129 seconds, Fetched: 13 row(s)
--导入数据
load data local inpath '/app/hadoop/data/employees_1'
overwrite into table employees partition(country = 'CH',state = 'BeiJin');
load data local inpath '/app/hadoop/data/employees_2'
overwrite into table employees partition(country = 'US',state = 'NY');
--导入后目录结构
.../employees/country=CH/state=BeiJin'
.../employees/country=US/state=NY
.../employees/country=US/state=AK
--查看表的分区
hive (mydb)>show partitions employees;
OK
country=US/state=CL
country=US/state=NY
country=CH/state=BeiJin
hive> SHOWPARTITIONS employees PARTITION(country='US');
country=US/state=AL
country=US/state=AK
...
注意:
当用户不加限制条件对一个非常大的分区表进行全表扫描时,这样触发一个巨大的MapReduce Job,会给硬盘带来很大的压力。所以Hive强烈建议使用“strict”,即当用户的查询语句不加where条件时,是禁止对分区表进行查询的。你能改成“nonstrict”模式(默认的模式)取消这种限制。
hive (mydb)>set hive.mapred.mode=strict;
hive (mydb)>select * from employees;
FAILED: SemanticException[Error 10041]: No partition predicate found for Alias "employees"Table "employees"
外部分区表:
一个分区表实例:
CREATE EXTERNAL TABLE IF NOT EXISTS log_messages (
hms INT,
severity STRING,
server STRING,
process_id INT,
message STRING)
PARTITIONED BY(year INT, month INT, day INT)
ROW FORMATDELIMITED FIELDS TERMINATED BY '\t';
上面创建外部表语句可以看到,我们没有加像非分区表那样的LOCATION子句。
外部分区表在创建时是不需要加LOCATION子句的,代替的是通过ALTER TABLE语句添加各自的分区。如下:
--添加外部表的分区
ALTER TABLE log_messages ADD PARTITION(year = 2012, month = 1, day = 2)
LOCATION 'hdfs://master_server/data/log_messages/2012/01/02';
7. 删除表
DROP TABLE IFEXISTS employees;
如果启用hadoop回收站(.Trash)功能,删除的会移动到.Trash目录,通过设置fs.trash.interval参数回收站的回收周期。但不是能保证所有版本的都能使用这咱方法。如果不小删除了重要的管理表,可以重新创建一个相同表名的空表,然后把回收站的移回原来的目录,这样就能恢复数据。
8. 修改分区表
--重命名
ALTER TABLE log_messages RENAME TO logmsgs;
--添加外部分区表分区
ALTER TABLE log_messages ADD IF NOT EXISTS
PARTITION (year= 2011, month = 1, day = 1) LOCATION '/logs/2011/01/01'
PARTITION (year= 2011, month = 1, day = 2) LOCATION '/logs/2011/01/02'
PARTITION (year= 2011, month = 1, day = 3) LOCATION '/logs/2011/01/03'
...;
注意:当添加单个分区时,分区目录会动创建,但如果同时添加多个分区时,只会创建第一个分区的目录。如上面的语句,只会创建/logs/2011/01/01目录,其它两个不会创建。
--改变分区的位置
ALTER TABLE log_messages PARTITION(year = 2011, month = 12, day = 2)
SET LOCATION 's3n://ourbucket/logs/2011/01/02';
--删除分区
ALTER TABLE log_messages DROP IF EXISTS PARTITION(year = 2011, month = 12, day = 2);
9. 列的修改
--修改列的名字并改变列的位置
ALTER TABLE log_messages
CHANGE COLUMN hms hours_minutes_seconds INT
COMMENT 'Thehours, minutes, and seconds part of the timestamp'
AFTER severity;
上面的语句作用是,修改hms列的名字为hours_minutes_seconds,并把它放在severity列之后。
改之前:
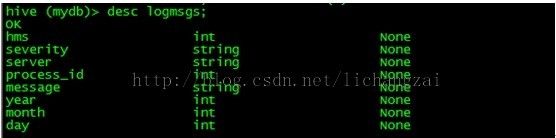
改之后:

--添加列
ALTER TABLE log_messages ADD COLUMNS (
app_name STRING COMMENT 'Application name',
session_id STRING COMMENT 'The current sessionid');
--替换列
ALTER TABLE log_messages REPLACE COLUMNS (
hours_mins_secs INT COMMENT 'hour, minute, seconds fromtimestamp',
severity STRING COMMENT 'The message severity'
message STRING COMMENT 'The rest of the message');
上面的语句是重命名原来的hms列为hours_mins_secs,删除掉原来的server和process_id列。
但注意REPLACE语句只有在本地的SerDe 模式的表上使用,后面的章节会提到。
--修改表的属性测试报错
ALTER TABLE log_messages SET TBLPROPERTIES
('notes' = The process idis no longer captured; this column is always NULL');
--修改存储属性
ALTER TABLE log_messages
PARTITION(year =2011, month = 1, day = 1)
SET FILEFORMAT SEQUENCEFILE;
ALTER TABLE stocks
CLUSTERED BY(exchange, symbol)
SORTED BY(symbol)
INTO 48 BUCKETS;
10 .其它修改表语句
--钩回语句
ALTER TABLE log_messages TOUCH
PARTITION (year =2012, month = 1, day = 1);
执行上面的语句后,当hive的外部文件被修改时,会触发一个钩回操作
--归档分区语句
ALTER TABLE log_messages ARCHIVE
PARTITION(year =2012, month = 1, day = 1);
归档分区仅是减少文件系统文件的数量,减少namenode的压力,不会减少空间使用。反操作语句是NOARCHIVE
--保护分区不会被删除
ALTER TABLE log_messages
PARTITION(year =2012, month = 1, day = 1) ENABLE NO_DROP;
hive (mydb)>ALTER TABLE logmsgs
> PARTITION(year = 2014, month =1, day = 21) ENABLE NO_DROP;
hive (mydb)>ALTER TABLE logmsgs DROP IF EXISTS PARTITION(year = 2014, month = 1, day = 21);
FAILED:SemanticException [Error 30011]: Partition protected from being droppedmydb@logmsgs@year=2014/month=1/day=21
hive (mydb)>ALTER TABLE logmsgs
> PARTITION(year = 2014, month =1, day = 21) disABLE NO_DROP;
OK
Time taken: 0.25seconds
hive (mydb)>ALTER TABLE logmsgs DROP IF EXISTS PARTITION(year = 2014, month = 1, day = 21);
Dropping thepartition year=2014/month=1/day=21
OK
Time taken:0.429 seconds
hive (mydb)>show partitions logmsgs;
OK
year=2014/month=1/day=20
year=2014/month=1/day=22
Time taken:0.105 seconds, Fetched: 2 row(s)
--保护分区不能被查询
ALTER TABLE log_messages
PARTITION(year =2012, month = 1, day = 1) ENABLE OFFLINE;