Spark实例TopN---Spark学习笔记11
Spark是基于内存的分布式计算框架,性能是十分彪悍的。
话接上回,部署完Spark集群之后,想要测试一下,Spark的性能。
1、环境
集群概况可以参见Spark Hadoop集群部署与Spark操作HDFS运行详解。
现在集群里有一大约7G的文件,是手机号和IP地址的组合。
hadoop dfs -dus /dw/spark/mobile.txt
hdfs://web02.dw:9000/dw/spark/mobile.txt 7056656190里面我们关心的只有IP地址。
hadoop dfs -cat /dw/spark/mobile.txt | more
2014-04-21 104497 15936529112 2 2011-01-11 09:58:47 0 0 2011-01-11 09:58:50 2011-01-19 09:58:50 61.172.242.36 2011-01-19 08:59:47 0
0
2014-04-21 111864 13967013250 2 2010-11-28 21:06:56 0 0 2010-11-28 21:06:57 2010-12-06 21:06:57 61.172.242.36 2010-12-06 20:08:11 0
0
2014-04-21 116368 15957685805 2 2011-06-27 17:05:55 0 0 2011-06-27 17:06:01 2011-07-05 17:06:01 10.129.20.108 2011-07-05 16:11:05 0
0
2、count和TopN
2.1 count文件
spark可以很简单的实现类似sql中select count(1) from xxx 的功能。调用RDD 的count函数就好了。
进入spark-shell
bin/spark-shell
scala> val data = sc.textFile("/dw/spark/mobile.txt")
14/05/14 17:23:33 INFO MemoryStore: ensureFreeSpace(73490) called with curMem=0, maxMem=308713881
14/05/14 17:23:33 INFO MemoryStore: Block broadcast_0 stored as values to memory (estimated size 71.8 KB, free 294.3 MB)
data: org.apache.spark.rdd.RDD[String] = MappedRDD[1] at textFile at <console>:12
14/05/14 17:24:24 INFO SparkContext: Job finished: count at <console>:15, took 7.739683757 s res0: Long = 54240679
第二次执行用了took 6.597322016 s。
hadoop dfs -cat /dw/spark/mobile.txt | wc -l 54240679
7G 文件大约count大约5~8秒之间。
这里如果调用
data.cache data.count
7G文件在内存,count时间会在0.7秒左右,因为这里把所以分区都缓存到内存里了。
2.2 TopN
网上经常见到的问题: 给定一个大文件,求里面Ip出现最多次数的前N个Ip地址和出现次数。
我们Step By Step
1. 找出每行出现的ip地址
找出IP地址有很多方法,可以按分隔符分割,也可以用正则。
这里我用正则找出IP地址了,因为只有1列是IP。
scala> data.map(line=>"""\d+\.\d+\.\d+\.\d+""".r.findAllIn(line).mkString) take 10
14/05/14 17:41:14 INFO SparkContext: Starting job: take at <console>:15
14/05/14 17:41:14 INFO DAGScheduler: Got job 2 (take at <console>:15) with 1 output partitions (allowLocal=true)
14/05/14 17:41:14 INFO DAGScheduler: Final stage: Stage 2 (take at <console>:15)
14/05/14 17:41:14 INFO DAGScheduler: Parents of final stage: List()
14/05/14 17:41:14 INFO DAGScheduler: Missing parents: List()
14/05/14 17:41:14 INFO DAGScheduler: Computing the requested partition locally
14/05/14 17:41:14 INFO HadoopRDD: Input split: hdfs://web02.dw:9000/dw/spark/mobile.txt:0+134217728
14/05/14 17:41:14 INFO SparkContext: Job finished: take at <console>:15, took 0.072784535 s
res2: Array[String] = Array("", 61.172.242.36, "", 61.172.242.36, "", 127.0.0.1, 10.129.20.108, 10.129.20.109, 10.129.20.98, 127.0.0.1)
这里发现有的IP是空的,这些是我们不需要的。
2. 过滤掉非IP地址
scala> data.map(line=>"""\d+\.\d+\.\d+\.\d+""".r.findAllIn(line).mkString).filter(_!="") take 10 14/05/14 17:42:26 INFO SparkContext: Starting job: take at <console>:15 14/05/14 17:42:26 INFO DAGScheduler: Got job 3 (take at <console>:15) with 1 output partitions (allowLocal=true) 14/05/14 17:42:26 INFO DAGScheduler: Final stage: Stage 3 (take at <console>:15) 14/05/14 17:42:26 INFO DAGScheduler: Parents of final stage: List() 14/05/14 17:42:26 INFO DAGScheduler: Missing parents: List() 14/05/14 17:42:26 INFO DAGScheduler: Computing the requested partition locally 14/05/14 17:42:26 INFO HadoopRDD: Input split: hdfs://web02.dw:9000/dw/spark/mobile.txt:0+134217728 14/05/14 17:42:26 INFO SparkContext: Job finished: take at <console>:15, took 0.04304932 s res3: Array[String] = Array(61.172.242.36, 61.172.242.36, 127.0.0.1, 10.129.20.108, 10.129.20.109, 10.129.20.98, 127.0.0.1, 61.172.242.36, 127.0.0.1, 10.129.20.111)
3. 最经典的word count
map阶段:
形成(IP,1) 这样的key,value的map结构。
scala> data.map(line=>"""\d+\.\d+\.\d+\.\d+""".r.findAllIn(line).mkString).filter(_!="").map(word=>(word,1)) take 10 14/05/14 17:43:29 INFO SparkContext: Starting job: take at <console>:15 14/05/14 17:43:29 INFO DAGScheduler: Got job 5 (take at <console>:15) with 1 output partitions (allowLocal=true) 14/05/14 17:43:29 INFO DAGScheduler: Final stage: Stage 5 (take at <console>:15) 14/05/14 17:43:29 INFO DAGScheduler: Parents of final stage: List() 14/05/14 17:43:29 INFO DAGScheduler: Missing parents: List() 14/05/14 17:43:29 INFO DAGScheduler: Computing the requested partition locally 14/05/14 17:43:29 INFO HadoopRDD: Input split: hdfs://web02.dw:9000/dw/spark/mobile.txt:0+134217728 14/05/14 17:43:29 INFO SparkContext: Job finished: take at <console>:15, took 0.017397074 s res5: Array[(String, Int)] = Array((61.172.242.36,1), (61.172.242.36,1), (127.0.0.1,1), (10.129.20.108,1), (10.129.20.109,1), (10.129.20.98,1), (127.0.0.1,1), (61.172.242.36,1), (127.0.0.1,1), (10.129.20.111,1))reduce阶段:
累加IP出现的次数。
data.map(line=>"""\d+\.\d+\.\d+\.\d+""".r.findAllIn(line).mkString).filter(_!="").map(word=>(word,1)).reduceByKey(_+_)这里仅仅是统计出了IP次数。
逆转map,排序
将map的k,v互换,变成(value, IP) 这样才能利用sortByKey排序找出top的IPs。
data.map(line=>"""\d+\.\d+\.\d+\.\d+""".r.findAllIn(line).mkString).filter(_!="").map(word=>(word,1)).reduceByKey(_+_).map(word=>(word._2,word._1)).sortByKey(false).map(word=>(word._2,word._1)) take 50
Ps:这里我没有一步步保存中间结果,看起来可能会比较吃力。直接执行这句代码就是找出top 50的IP地址。
上结果:
topIps: Array[(String, Int)] = Array((127.0.0.1,3517348), (10.129.41.91,519688), (10.129.41.92,515434), (10.129.41.93,503120), (10.129.41.94,484359), (10.129.41.95,466621), (10.129.41.96,441576), (10.129.41.97,397698), (10.129.41.98,393082), (10.66.63.21,255484), (61.172.242.36,151109), (10.66.63.22,97582), (10.129.20.109,90529), (10.129.20.111,90472), (10.129.20.110,89783), (10.129.20.108,89411), (10.129.20.99,88445), (61.160.212.242,84373), (10.129.20.98,82245), (114.80.132.9,71766), (10.127.41.31,46312), (10.129.20.102,33377), (61.172.254.185,26054), (218.206.68.237,24529), (10.129.8.22,21361), (10.129.8.21,21136), (10.127.41.32,19309), (10.150.9.241,12631), (61.172.251.20,12496), (10.150.9.240,12340), (61.172.254.152,6509), (10.131.28.25,5908), (61.172.254.9,5566), (10.131.28.26,494...
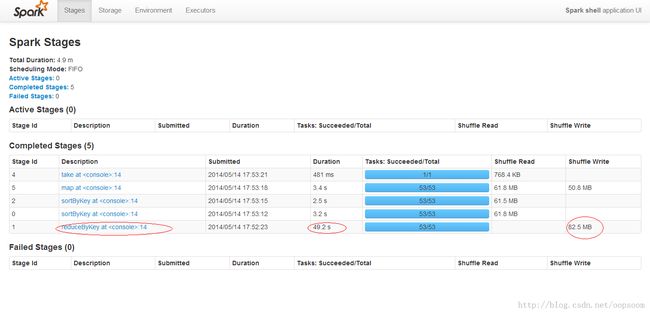
看一下执行到底用了多久,大约58秒+。最耗时的是reduce,用了49秒。
3、总结
Spark性能还是比较突出的,无论有没有将数据cache到内存。
相较于hive,在相同的配置下,无法做到秒级的count,更没法做到毫秒级。
对于TopN的问题,Spark是基于DAG 的,性能相较hive,肯定也是天壤之别了。
原创文章,转载请注明出自:http://blog.csdn.net/oopsoom/article/details/25815443
-EOF-