Machine Learning - X. Advice for Applying Machine Learning机器学习应用上的建议 (Week 6)
http://blog.csdn.net/pipisorry/article/details/44119187
机器学习Machine Learning - Andrew NG courses学习笔记
Advice for Applying Machine Learning机器学习应用上的建议
{解决应用机器学习算法遇到的trainning set和test set预测不高的问题}
Deciding What to Try Next 决定接下来做什么
机器学习算法不佳时可能需要做的

But sometimes getting more training data doesn't actually help.
选择怎么做之前要学会的

So next talk about how evaluate your learning algorithms and after some diagnostics.
Evaluating a Hypothesis假设评估
how do you tell if the hypothesis might be overfitting如何判断模型是否过拟合

problems with a large number of features is hard or impossible to plot what the hypothesis and need other way to evaluate hypothesis.
Way to evaluate a learned hypothesis评估假设的方法

Note:
1. if data were already randomly sorted,just take the first 70% and last 30%.
2. if data were not randomly ordered,better to randomly shuffle the examples in your training set.
3. overfitting is why the training set's error is not a good predictor for how well the hypothesis will do on new example.
procedure for train and test the learning algorithm训练和测试学习算法的过程


an alternative test sets metric that might be easier to interpret,and that's the misclassification error.

Model Selection and Train_Validation_Test Sets 模型选择和Train_Validation_Test集
model selection process模型选择过程
{choose features or choose the regularization parameter}
choose what degree polynomial to fit to data选择多项式的度数
it's as if there's one more parameter, d, that you're trying to determine using your data set.
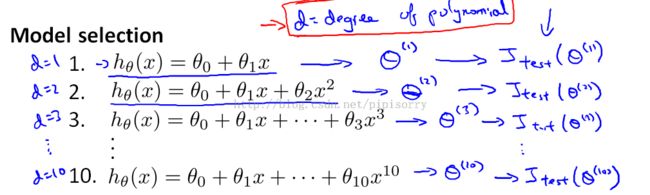
choose the model which has the lowest test set error.

Note:在测试集上选择参数会导致的问题:because I had fit this parameter d to my test set is no longer fair to evaluate my hypothesis on this test set, because I fit my parameters(the degree d of polynomial) to this test set,And so my hypothesis is likely to do better on this test set than it would on new examples that hasn't seen before.也即不能在test set中同时选择degree参数和评估hypothesis.
评估参数和hypothesis更优的方法(split the data set into three pieces)

Note:Sometimes cross validation set also called the validation set.
模型选择(在交叉验证集上选择模型参数!这是重点!)


pick the hypothesis with the lowest cross validation error.(fourth order).
use the test set to measure, or to estimate the generalization error of the model that was selected.
总结:take your data,split it into a training,validation, and test set.And use your cross validation data to select the model and evaluate it on the test set.
Diagnosing Bias vs. Variance 诊断:偏差与方差
{If run the learning algorithm doesn't do well almost all the time, it will be because you have either a high bias or a high variance problem.In other words they're either an underfitting or an overfitting problem}
训练错误和测试错误

鉴别overfit(high variance)和underfit(high bias)

Note:也就是说训练集和测试集上的错误率都要计算来比较。
Regularization and Bias_Variance 规格化和偏差_方差
how regularization affect the bias and variance规格化对偏差和方差的影响
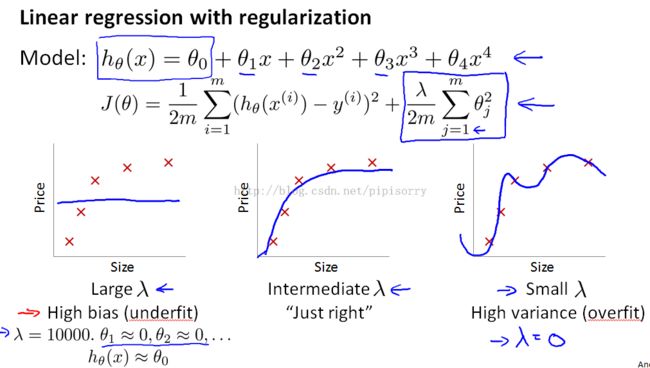
how automatically choose the regularization parameter lambda自动选择规格化参数lambda

Note:交叉验证集上选择规格化参数:then pick whichever one of these 12 models gives me the lowest error on the cross-validation set.

Note:
1. the right: large lambda corresponds a high bias(underfit) where you might not even fit your training set well.
2. the left:high-variance .overfitting the data then it across validation error will also be high.
3. You should not use test set data in choosing the regularization parameter, as it means the test error will not be a good estimate of generalization error.见前面讲的在测试集上选择参数会导致的问题。
Learning Curves学习曲线
learning curves : diagnose if a learning algorithm suffering from bias, variance problem or both.
判断学习算法是high bias(underfit)还是high variance(overfit)

Note:
1. m equals 1 or 2 or 3,training error is going to be 0 assuming not using regularization or it may slightly large in 0 if using regularization and if I have a large training set and I'm artificially restricting the size of my training set in order to plot J train.
2. the more data you have, the better the hypothesis you fit: your cross validation error and your test set error will tend to decrease as your training set size increases because the more data you have, the better you do at generalizing to new examples.
high bias(underfit)的情形

Note:
1. the training error will end up close to the cross validation error, because you have so few parameters and so much data, at least when m is large.The performance on the training set and the cross validation set will be very similar.
2. high bias is reflected with high value of both Jcv and the j train.
high variance(overfit)的情形
 {overfitting}
{overfitting}
Note:
1. high varience的显著特征: large gap
2. Using fewer training examples should never improve test set performance, as the model has fewer data points from which to learn.
Deciding What to Do Next(Revisited)决定下一步操作
根据上面的知识决定机器学习算法不佳时怎么做

Note: fixes high bias: e.g. keep increasing the number of features/number of hidden units in neural networkuntil you have a low bias classifier.
some way to figure out which of these might be fruitful options:
1. the first option is useful only if plot the learning curves and figure out that you have at least a bit of a variance, meaning that the cross-validation error is quite a bit bigger than your training set error.
2. it's again something that fixes high variance.if you figure out, by looking at learning curves that have a high high variance problem,indeed trying to select out a smaller set of features,that might indeed be a very good use of your time.Reducing the feature set will ameliorate(改善) the overfitting and help with the variance problem.
3. a solution for fixing high bias problems.So if you are adding extra features it's usually because your current hypothesis is too simple, and get additional features to make our hypothesis better able to fit the training set.
4. similarly, adding polynomial features;is another way of adding features and so to fix the high bias problem.
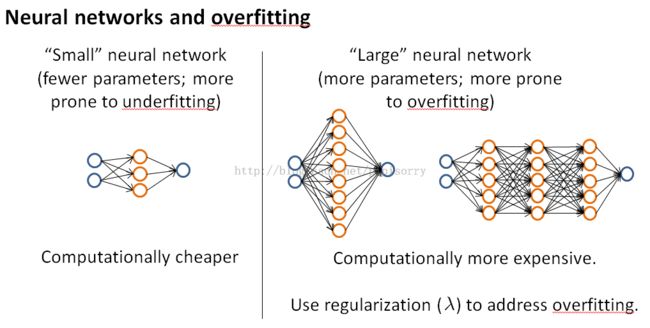
神经网络中每层单元个数的选择及hidden layler个数的选择
practical advice for choose the architecture or the connectivity pattern of the neural networks.
the other decisions: the number of hidden layers:
using a single hidden layer is a reasonable default, but if you want to choose the number of hidden layers, one other thing you can try is find yourself a training cross-validation,and test set split and try training neural networks with one hidden layer or two or three and see which of those neural networks performs best on the cross-validation sets.
Review



{The poor performance on both the training and test sets suggests a high bias problem,should increase the complexity of the hypothesis, thereby improving the fit to both the train and test data.}

{The learning algorithm finds parameters to minimize training set error, so the performance should be better on the training set than the test set.}

{A model with high variance will still have high test error, so it will generalize poorly.}
from:http://blog.csdn.net/pipisorry/article/details/44245347
ref:Advice for applying Machine Learning
Andrew Ng-Advice for applying Machine Learning.pdf