Hadoop学习之传递命令行参数给Mapper和Reducer
在Hadoop-1.2.1进行作业开发时,由于输入文件的特殊性,需要将日期作为参数传递到Mapper和Reducer任务。而通常情况下在使用hadoop jar运行作业时,传递的参数为输入文件路径和输出文件路径,那如何做到添加额外参数到作业中呢?仔细分析一下作业类的run方法,并结合Hadoop API可以粗略的推断出:可以在core-site.xml文件中添加参数及参数值实现向作业传递参数。但该方法比较笨拙,一是因为不同作业可能需要的参数不同,若存在多个需要参数的作业势必导致core-site.xml文件增大,二是因为这种方式不够灵活,若需要不同的参数值,则必须修改core-site.xml文件并重新启动Hadoop集群。显然在运行多个作业,规模较大的集群该方法是不太可行的。既然可以通过命令行向作业传递输入和输出目录,是否可以通过命令行向作业传递特殊参数呢?答案是肯定的。
由于Configuration 支持以编程的方式设置和获取参数,那就可以将命令行中的参数保存在Configuration ,然后在Mapper或者Reducer任务通过Configuration 的get方法获取该参数的值。在测试该方法之前,需要确定map和reduce方法是否可以取得Configuration 对象,结合API可以得出map和reduce方法中的Context对象可以通过方法getConfiguration()得到Configuration 对象,至此似乎一切都迎刃而解了,接下来就来验证一下吧。未带特殊参数的作业的run方法代码如下:
@Override
public int run(String[] as) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf, "wordCount");
job.setJarByClass(WordCount.class);
Path in = new Path(as[0]);
Path out = new Path(as[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
……
System.exit(job.waitForCompletion(true)?0:1);
return 0;
}
现在假设在命令输出入hadoop jar test.jar 2014-08-18 input/ output/,那么参数2014-08-18需要传递给Mapper或者Reducer任务,具体代码如下:
@Override
public int run(String[] as) throws Exception {
Configuration conf = getConf();
//下面将命令行的参数保存在Configuration对象中
//需要注意的是必须在将conf传递给Job构造函数之前设置自定义参数
conf.set(“test.date”,as[0]);
Job job = new Job(conf, "wordCount");
job.setJarByClass(WordCount.class);
Path in = new Path(as[1]);
Path out = new Path(as[2]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
……
System.exit(job.waitForCompletion(true)?0:1);
return 0;
}
在将参数传递给Configuration对象后,在map或者reduce方法中就可以使用该参数了,具体代码为:
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//在map方法中通过Context对象获取conf对象,进而取得参数值
Configuration conf = context. getConfiguration();
String arg = conf.get(“test.date”);
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
需要注意的是必须在将conf传递给Job构造函数之前设置自定义参数,在创建了Job对象后再调用Configuration的设置参数方法将不会传递给Mapper或者Reducer任务。按照之前一贯的开发方式,认为无论在创建Job对象之前还是之后设置参数都会生效,但实际情况却不是这样的。要想彻底弄清楚Hadoop是如何做的,那只有研究一下源代码了,在研究源代码之前需要说明的是大体能够猜测到Hadoop是如何实现的,因为在学习Hadoop作业时已经了解到每个作业都有与之对应的job.xml文件,所以猜测是根据传递的Configuration对象构造了与作业对应的管理对象JobConf,这样再次修改Configuration对象将不会影响到作业的JobConf。具体是否是这样呢,只能通过阅读源代码来验证了,在开始之前先看一下Mapper和Reducer中的Context的继承关系,Context是Mapper和Reducer的内部类,分别为Mapper.Context和Reducer.Context:
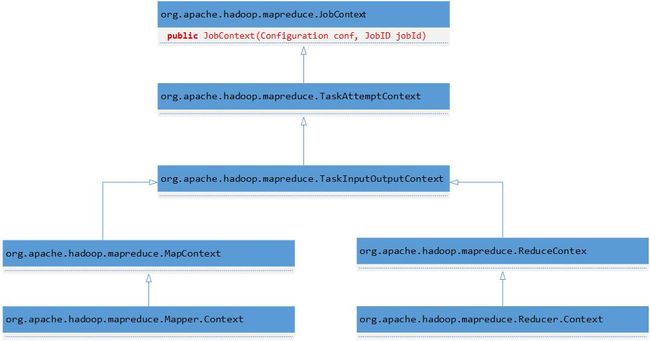
由类层次关系就可以很清晰地知道为什么在Mapper或者Reducer任务中可以获得Configuration对象,这是由JobContext决定的。经过阅读源代码总结Configuration、JobConf、JobContext和Job的关系如下:
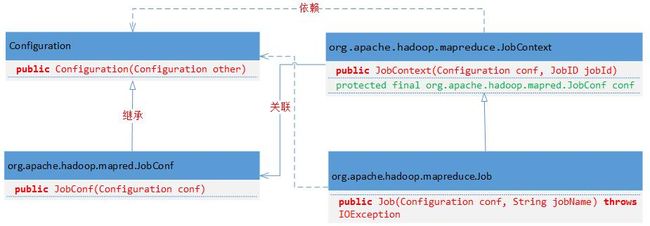
1. 使用Configuration对象创建Job对象。源代码为:
public Job(Configuration conf) throws IOException {
super(conf, null);
}
public Job(Configuration conf, String jobName) throws IOException {
this(conf);
setJobName(jobName);
}
2. Job最终调用父类JobContext的public JobContext(Configurationconf, JobID jobId)方法,源代码如下:
public JobContext(Configuration conf, JobID jobId) {
this.conf = new org.apache.hadoop.mapred.JobConf(conf);
this.credentials = this.conf.getCredentials();
this.jobId = jobId;
try {
this.ugi = UserGroupInformation.getCurrentUser();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3. Job对象包含了与特定作业对应的JobConf对象,该对象的构造函数为:
public JobConf(Configuration conf) {
super(conf);
if (conf instanceof JobConf) {
JobConf that = (JobConf)conf;
credentials = that.credentials;
}
checkAndWarnDeprecation();
}
4. 由上面的UML类图可知JobConf是Configuration的子类,Configuration的构造函数如下:
public Configuration(Configuration other) {
this.resources = (ArrayList) other.resources.clone();
synchronized (other) {
if (other.properties != null) {
this.properties = (Properties) other.properties.clone();
}
if (other.overlay != null) {
this.overlay = (Properties)other.overlay.clone();
}
this.updatingResource = new HashMap<String, String>(
other.updatingResource);
}
this.finalParameters = new HashSet<String>(other.finalParameters);
synchronized (Configuration.class) {
REGISTRY.put(this, null);
}
}
通过上面的源代码分析可知,当将Configuration对象传递给Job构造函数构建Job对象时,实际为Job对象创建了新的JobConf对象,此对象与原有的Configuration不是相同的对象,所以原有的Configuration对象再执行修改参数的方法将不会传递到作业内部。